Python 官方文档:入门教程 => 点击学习
目录1 前言2 哪里去获取数据呢3 怎么抓取数据呢1 前言 python爬虫用来收集数据是最直接和常用的方法,可以使用python爬虫程序获得大量的数据,从而变得非常的简单和快速;绝
python爬虫用来收集数据是最直接和常用的方法,可以使用python爬虫程序获得大量的数据,从而变得非常的简单和快速;绝大多数网站使用了模板开发,使用的模板可以快速生成大量相同布局不同内容的页面,这时只需要为一个页面开发爬虫程序,因为爬虫程序也可以对同一模板生成的不同内容进行爬取内容
这里给大家准备好了,打开这个连接,就能找看到对应的基金信息:
Http://fund.eastmoney.com/jzzzl.html
有了基金连接,我们要做的就是怎么把它抓取下来,123 开始,我恰巧发现了后台访问的接口,是不是很神奇,该是上图的时候了,大家可以看到如下图:
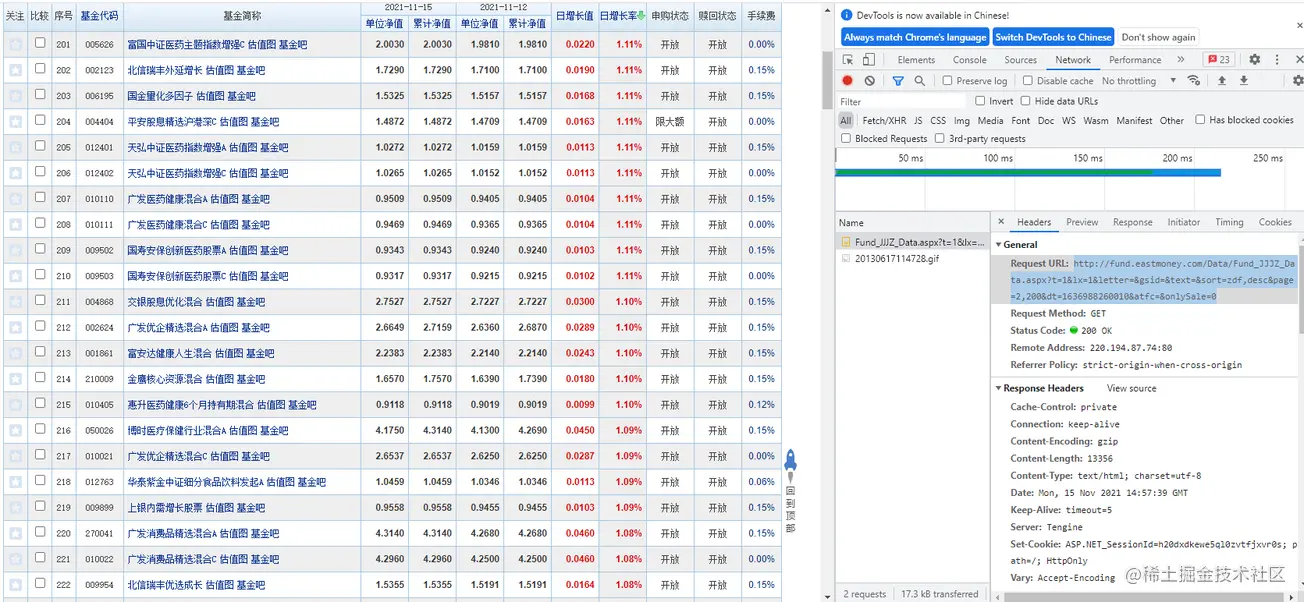
# 这是原始的连接
http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?lx=1&sort=zdf,desc&page=2,200&onlySale=0
# 经过我使用postman 删减掉一些参数发现精简的连接如下,我不能不吐槽一下,这个时候了还有参数传递使用中文首字母拼写的,
# lx分明就是类型的简写。sort 是对某些字段排序可以忽略。分页的话2,200就是第二页,每页200条,onlySale就是可以卖出的条件。
http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?lx=1&sort=zdf,desc&page=2,100&onlySale=0这里我们使用Python,需要安装的类库有 requests/demJSON/prettytable/json,有没有特别简单呢?
# 安装命令如下
# 发起请求
pip install requests
# 将不是那么严格的json 格式转换为json
pip install demjson
# 格式化打印数据
pip install prettytable
# 将json 格式化的文本转换为json
pip install json这里我可以上代码了,简单的逻辑就是先抓取api接口返回的信息,然后解析报文,将返回结果转换成json 格式后只选择需要获取的内容,最后将获取的结果进行输出即可。
import requests
import json
import demjson
from prettytable import PrettyTable
# 数据表格的列表表头字段
title_list = ["code", "name", "value"]
# 查询基金列表信息
def query_fund_list(page= 1):
req_url = "http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?lx=1&sort=zdf,desc&page={},20&onlySale=0".fORMat(page)
response = requests.get(req_url)
# 输出响应头
# print(response.headers)
# 获取请求结果并替换,否则结果不能进行格式化json
resp_body = response.text.replace("var db=", "")
# 本来首选是这个json, 因为json 不支持 {a :"1"} 这样的转换,因此使用了 demojson
# json_data = json.loads(resp_body)
# 转换对象为 json 对象,使不规则的json格式化为json对象
resp_body = demjson.decode(resp_body)
# 获取结果数组
fund_list = resp_body["datas"]
body_list = []
for node in fund_list:
tmp = []
tmp.append(node[0])
tmp.append(node[1])
tmp.append(node[3])
body_list.append(tmp)
# 创建一个对象 PrettyTable 用于打印输出结果
bt = PrettyTable()
# 将表头信息信息放入bt 中
bt.field_names = title_list
# 将表格内容放置在 bt 中
bt.add_rows(body_list)
# 打印结果
print(bt)
if __name__ == "__main__":
# 这里只打印了第一页,循环打印结果就不写了,大家都会的
query_fund_list(1)最终输出的结果如图所示 :
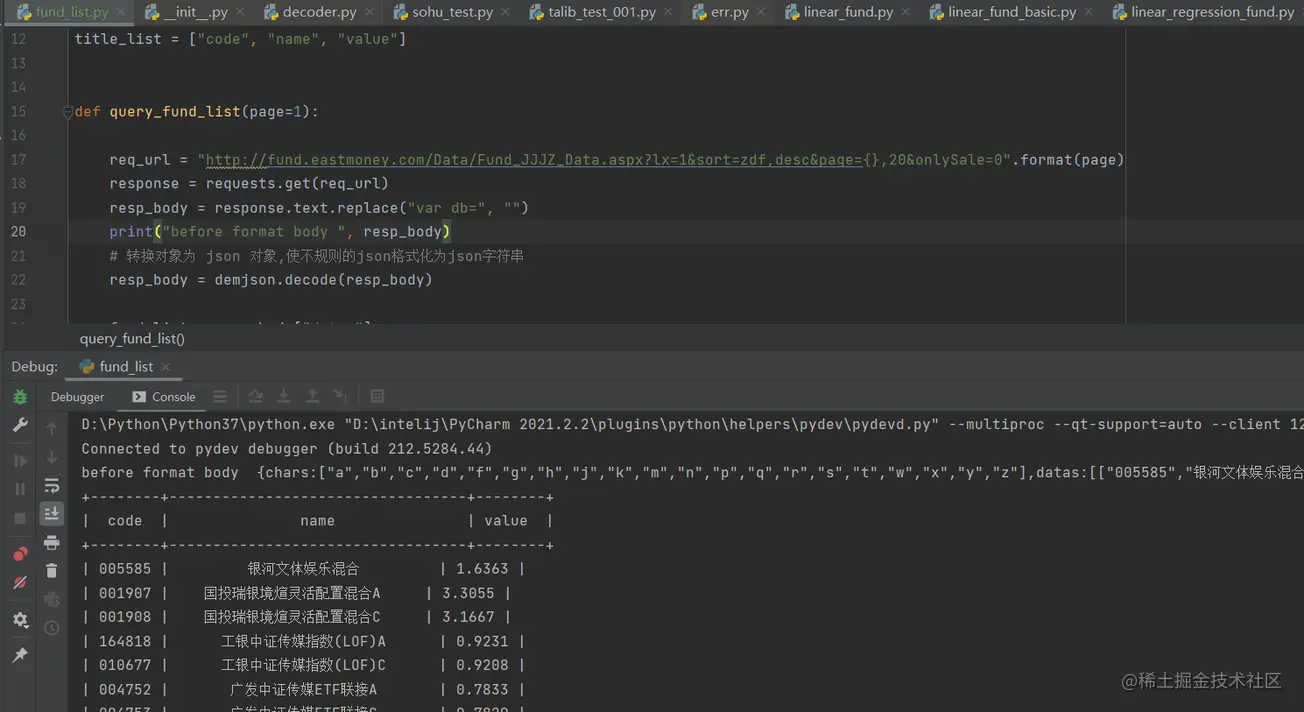
最终我们达到的结果就是这样的结果,有了这些结果,我们可以进行结构化存储,放进数据库中方面查询和使用。
| 基金代码 | 基金名称 | 最新净值 |
|---|---|---|
| 005585 | 银河文体娱乐混合 | 1.6363 |
| 001907 | 国投瑞银境煊灵活配置混合A | 3.3055 |
| 001908 | 国投瑞银境煊灵活配置混合C | 3.1667 |
| 164818 | 工银中证传媒指数(LOF)A | 0.9231 |
| ... | ... | ... |
这是一个简单的开始,我们获取到了基金的列表。后续我们会抓取基金的基本信息和变动信息,建立模型去展现。
到此这篇关于Python爬虫获取基金列表的文章就介绍到这了,更多相关Python获取列表内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python爬虫获取基金列表
本文链接: https://www.lsjlt.com/news/117622.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0