Python 官方文档:入门教程 => 点击学习
目录1.read_excel函数原型2.参数使用举例2.1. io和sheet_name参数2.2. header参数2.3. skipfooter参数2.5. parse_date
pandas read_excel()参数使用详解
def read_excel(io,
sheet_name=0,
header=0,
names=None,
index_col=None,
parse_cols=None,
usecols=None,
squeeze=False,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
comment=None,
skip_footer=0,
skipfooter=0,
convert_float=True,
mangle_dupe_cols=True,
**kwds)
参数说明:

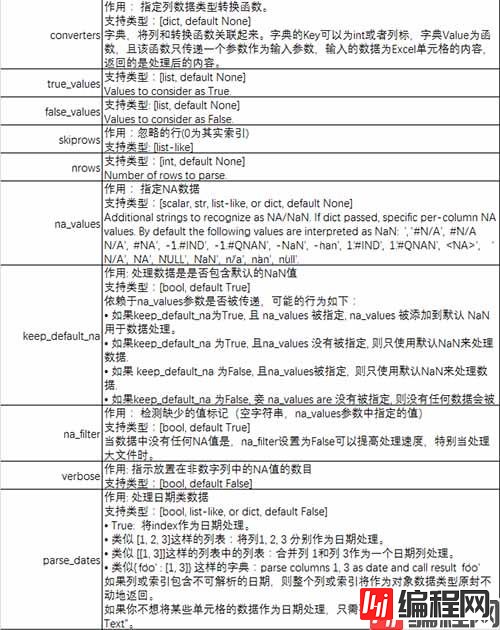

【例1】通过io和sheet_name读取Excel表
records.xlsx内容:
date val percent
2014/3/1 0.947014982 10%
2014/6/1 0.746103818 11%
2014/9/1 0.736764841 12%
2014/12/1 0.724937624 13%
2015/3/1 0.85043738 14%
2015/6/1 0.332503212 15%
2015/9/1 0.75289366 16%
2015/12/1 0.358275104 17%
2016/3/1 0.077250716 18%
2016/6/1 0.436182277 19%
2016/9/1 0.424714671 20%
2016/12/1 0.842471104 21%
2017/3/1 0.740035625 22%
2017/6/1 0.183588529 23%
2017/9/1 0.143363207 24%
Code:
In [166]: import pandas as pd
...: df = pd.read_excel(io="records.xlsx", sheet_name="Sheet1")
...: df
...:
Out[166]:
date val percent
0 2014/3/1 0.947015 10%
1 2014/6/1 0.746104 11%
2 2014/9/1 0.736765 12%
3 2014/12/1 0.724938 13%
4 2015/3/1 0.850437 14%
5 2015/6/1 0.332503 15%
6 2015/9/1 0.752894 16%
7 2015/12/1 0.358275 17%
8 2016/3/1 0.077251 18%
9 2016/6/1 0.436182 19%
10 2016/9/1 0.424715 20%
11 2016/12/1 0.842471 21%
12 2017/3/1 0.740036 22%
13 2017/6/1 0.183589 23%
14 2017/9/1 0.143363 24%
说明:此处io和sheet_name参数都可以不明确指定,直接使用:
df = pd.read_excel("records.xlsx", "Sheet1")
如果records.xlsx文件只有一张表,或者要读取的数据表为第一张表,sheet_name参数可以省略:
df = pd.read_excel("records.xlsx")
【例2】通过header参数指定表头位置
records.xlsx内容:
2020年XXX表
date val percent
2014/3/1 0.947014982 10%
2014/6/1 0.746103818 11%
2014/9/1 0.736764841 12%
2014/12/1 0.724937624 13%
2015/3/1 0.85043738 14%
2015/6/1 0.332503212 15%
2015/9/1 0.75289366 16%
2015/12/1 0.358275104 17%
2016/3/1 0.077250716 18%
2016/6/1 0.436182277 19%
2016/9/1 0.424714671 20%
2016/12/1 0.842471104 21%
2017/3/1 0.740035625 22%
2017/6/1 0.183588529 23%
2017/9/1 0.143363207 24%
我们在【例1】的基础上为records.xlsx的“Sheet1”表增加了一行表头说明,如果继续使用【例1】的代码,得到的结果是这样的:
In [169]: import pandas as pd
...: df = pd.read_excel("records.xlsx", "Sheet1")
...: df
...:
Out[169]:
2020年XXX表 Unnamed: 1 Unnamed: 2
0 date val percent
1 2014/3/1 0.947015 10%
2 2014/6/1 0.746104 11%
3 2014/9/1 0.736765 12%
4 2014/12/1 0.724938 13%
5 2015/3/1 0.850437 14%
6 2015/6/1 0.332503 15%
7 2015/9/1 0.752894 16%
8 2015/12/1 0.358275 17%
9 2016/3/1 0.077251 18%
10 2016/6/1 0.436182 19%
11 2016/9/1 0.424715 20%
12 2016/12/1 0.842471 21%
13 2017/3/1 0.740036 22%
14 2017/6/1 0.183589 23%
15 2017/9/1 0.143363 24%
这样得到的列标及数据都不是我们想要的,这种情况下就需要通过header参数来指定表头了,注意到表头是在第2行,根据header参数的说明可知,行号是从0开始计算的,所以header参数应该为1.
Code:
In [170]: import pandas as pd
...: df = pd.read_excel("records.xlsx", "Sheet1", header=1)
...: df
...:
Out[170]:
date val percent
0 2014/3/1 0.947015 10%
1 2014/6/1 0.746104 11%
2 2014/9/1 0.736765 12%
3 2014/12/1 0.724938 13%
4 2015/3/1 0.850437 14%
5 2015/6/1 0.332503 15%
6 2015/9/1 0.752894 16%
7 2015/12/1 0.358275 17%
8 2016/3/1 0.077251 18%
9 2016/6/1 0.436182 19%
10 2016/9/1 0.424715 20%
11 2016/12/1 0.842471 21%
12 2017/3/1 0.740036 22%
【例3】通过skipfooter参数忽略表尾数据
有时我们的数据是从第3方获取到的,往往会在表的末尾添加一行“数据来源:xxx”.如:
2020年XXX表
date val percent
2014/3/1 0.947014982 10%
2014/6/1 0.746103818 11%
2014/9/1 0.736764841 12%
2014/12/1 0.724937624 13%
2015/3/1 0.85043738 14%
2015/6/1 0.332503212 15%
2015/9/1 0.75289366 16%
2015/12/1 0.358275104 17%
2016/3/1 0.077250716 18%
2016/6/1 0.436182277 19%
2016/9/1 0.424714671 20%
2016/12/1 0.842471104 21%
2017/3/1 0.740035625 22%
2017/6/1 0.183588529 23%
2017/9/1 0.143363207 24%
数据来源: XXX
这种情况下,可以通过skipfooter参数来忽略该数据。
Code:
In [173]: import pandas as pd
...: df = pd.read_excel("records.xlsx", "Sheet1", header=1, skipfooter=1)
...: df
...:
Out[173]:
date val percent
0 2014/3/1 0.947015 10%
1 2014/6/1 0.746104 11%
2 2014/9/1 0.736765 12%
3 2014/12/1 0.724938 13%
4 2015/3/1 0.850437 14%
5 2015/6/1 0.332503 15%
6 2015/9/1 0.752894 16%
7 2015/12/1 0.358275 17%
8 2016/3/1 0.077251 18%
9 2016/6/1 0.436182 19%
10 2016/9/1 0.424715 20%
11 2016/12/1 0.842471 21%
12 2017/3/1 0.740036 22%
13 2017/6/1 0.183589 23%
14 2017/9/1 0.143363 24%
2.4. index_col参数
【例4】通过index_col参数指定DataFrame index
在【例3】中,查看我们读取得到的DataFrame的索引:
In [174]: df.index
Out[174]: RangeIndex(start=0, stop=15, step=1)
它是一个自动添加的整型索引,但如果现在我想要使用“date”列作为索引,可以通过index_col参数指定:
In [175]: import pandas as pd
...: df = pd.read_excel("records.xlsx", "Sheet1", header=1, skipfooter=1,index_col=0)
...: df
...:
Out[175]:
val percent
date
2014/3/1 0.947015 10%
2014/6/1 0.746104 11%
2014/9/1 0.736765 12%
2014/12/1 0.724938 13%
2015/3/1 0.850437 14%
2015/6/1 0.332503 15%
2015/9/1 0.752894 16%
2015/12/1 0.358275 17%
2016/3/1 0.077251 18%
2016/6/1 0.436182 19%
2016/9/1 0.424715 20%
2016/12/1 0.842471 21%
2017/3/1 0.740036 22%
2017/6/1 0.183589 23%
2017/9/1 0.143363 24%
In [176]: df.index
Out[176]:
Index(['2014/3/1', '2014/6/1', '2014/9/1', '2014/12/1', '2015/3/1', '2015/6/1',
'2015/9/1', '2015/12/1', '2016/3/1', '2016/6/1', '2016/9/1',
'2016/12/1', '2017/3/1', '2017/6/1', '2017/9/1'],
dtype='object', name='date')
或者改成这样:
df = pd.read_excel("records.xlsx", "Sheet1", header=1, skipfooter=1, index_col=“date”)
查看【例4】index的参数类型:
In [183]: type(df.index[0])
Out[183]: str
发现并不是我们想要的日期类型,而是str。现在我们想把它转换为日期类型,可选的一种方法就是通过parse_dates参数来实现。
【例5】parse_dates参数处理日期
Code:
In [184]: import pandas as pd
...: df = pd.read_excel("records.xlsx", "Sheet1", header=1, skipfooter=1,i
...: ndex_col="date", parse_dates=True)
...: df
...:
Out[184]:
val percent
date
2014-03-01 0.947015 10%
2014-06-01 0.746104 11%
2014-09-01 0.736765 12%
2014-12-01 0.724938 13%
2015-03-01 0.850437 14%
2015-06-01 0.332503 15%
2015-09-01 0.752894 16%
2015-12-01 0.358275 17%
2016-03-01 0.077251 18%
2016-06-01 0.436182 19%
2016-09-01 0.424715 20%
2016-12-01 0.842471 21%
2017-03-01 0.740036 22%
2017-06-01 0.183589 23%
2017-09-01 0.143363 24%
In [185]: type(df.index[0])
Out[185]: pandas._libs.tslibs.timestamps.Timestamp
当parase_date设置为True时,默认将index处理为日期类型。
如果要处理的列不是index列,可以通过parse_dates= "date"来实现。
如果要处理的列包含多个,可以通过parse_dates= [“col1”,“col2”,…]来实现。
在前面几个例子中,我们发现percent列的数据都是xx%这样的表示,且是str类型:
In [187]: type(df["percent"][0])
Out[187]: str
str类型并不是我们所希望的,现在我们希望可以将之转化为float类型,这可以通过converters参数来实现。
【例6】converters参数进行数据类型转换
Code:
In [189]: import pandas as pd
...: def convertPercent(val):
...: return float(val.split("%")[0])*0.01
...:
...: df = pd.read_excel("records.xlsx", "Sheet1", header=1, skipfooter=1,i
...: ndex_col="date", parse_dates=True, converters={"percent":convertPerce
...: nt})
...: df
...:
Out[189]:
val percent
date
2014-03-01 0.947015 0.10
2014-06-01 0.746104 0.11
2014-09-01 0.736765 0.12
2014-12-01 0.724938 0.13
2015-03-01 0.850437 0.14
2015-06-01 0.332503 0.15
2015-09-01 0.752894 0.16
2015-12-01 0.358275 0.17
2016-03-01 0.077251 0.18
2016-06-01 0.436182 0.19
2016-09-01 0.424715 0.20
2016-12-01 0.842471 0.21
2017-03-01 0.740036 0.22
2017-06-01 0.183589 0.23
2017-09-01 0.143363 0.24
【例7】na_values参数处理na数据
很多时候,并不是所有的数据都是有效数据,例如下表中2014/12/1和2016/6/1两行的数据均为“–”:
2020年XXX表
date val percent
2014/3/1 0.947014982 10%
2014/6/1 0.746103818 11%
2014/9/1 0.736764841 12%
2014/12/1 -- --
2015/3/1 0.85043738 14%
2015/6/1 0.332503212 15%
2015/9/1 0.75289366 16%
2015/12/1 0.358275104 17%
2016/3/1 0.077250716 18%
2016/6/1 -- --
2016/9/1 0.424714671 20%
2016/12/1 0.842471104 21%
2017/3/1 0.740035625 22%
2017/6/1 0.183588529 23%
2017/9/1 0.143363207 24%
数据来源: XXX
这种情况下可以通过na_values参数来处理。
Code
In [191]: import pandas as pd
...: df = pd.read_excel("records.xlsx", "Sheet1", header=1, skipfooter=1,i
...: ndex_col="date", parse_dates=True, na_values="--")
...: df
...:
Out[191]:
val percent
date
2014-03-01 0.947015 10%
2014-06-01 0.746104 11%
2014-09-01 0.736765 12%
2014-12-01 NaN NaN
2015-03-01 0.850437 14%
2015-06-01 0.332503 15%
2015-09-01 0.752894 16%
2015-12-01 0.358275 17%
2016-03-01 0.077251 18%
2016-06-01 NaN NaN
2016-09-01 0.424715 20%
2016-12-01 0.842471 21%
2017-03-01 0.740036 22%
2017-06-01 0.183589 23%
2017-09-01 0.143363 24%
【例8】 usecols参数选择列
当我们只想处理数据表中的某些指定列时,可以通过usecols参数来指定。例如,我只想处理"date"和"val"两列数据,可以这样通过
usecols=["date","val"]
来指定。
Code
In [193]: import pandas as pd
...: df = pd.read_excel("records.xlsx", "Sheet1", header=1, skipfooter=1,i
...: ndex_col="date", parse_dates=True, na_values="--", usecols=["date","v
...: al"])
...: df
...:
Out[193]:
val
date
2014-03-01 0.947015
2014-06-01 0.746104
2014-09-01 0.736765
2014-12-01 NaN
2015-03-01 0.850437
2015-06-01 0.332503
2015-09-01 0.752894
2015-12-01 0.358275
2016-03-01 0.077251
2016-06-01 NaN
2016-09-01 0.424715
2016-12-01 0.842471
2017-03-01 0.740036
2017-06-01 0.183589
2017-09-01 0.143363
到此这篇关于python Pandas库read_excel()参数的文章就介绍到这了,更多相关Pandas库read_excel()参数内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: python Pandas库read_excel()参数实例详解
本文链接: https://www.lsjlt.com/news/119522.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0