目录简介一、LRU和LFU算法LRU算法LFU算法小结:二、TinyLFU三、Window-TinyLFU简介 前置知识 知道什么是缓存 听完本节公开课,你可以收获 掌握朴素LRU、
前置知识
知道什么是缓存
听完本节公开课,你可以收获
LRU Least Recently Used 最近最少使用算法
LRU 算法的思想是如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。所以,当指定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
也就是淘汰数据的时候,只看数据在缓存里面待的时间长短这个维度。
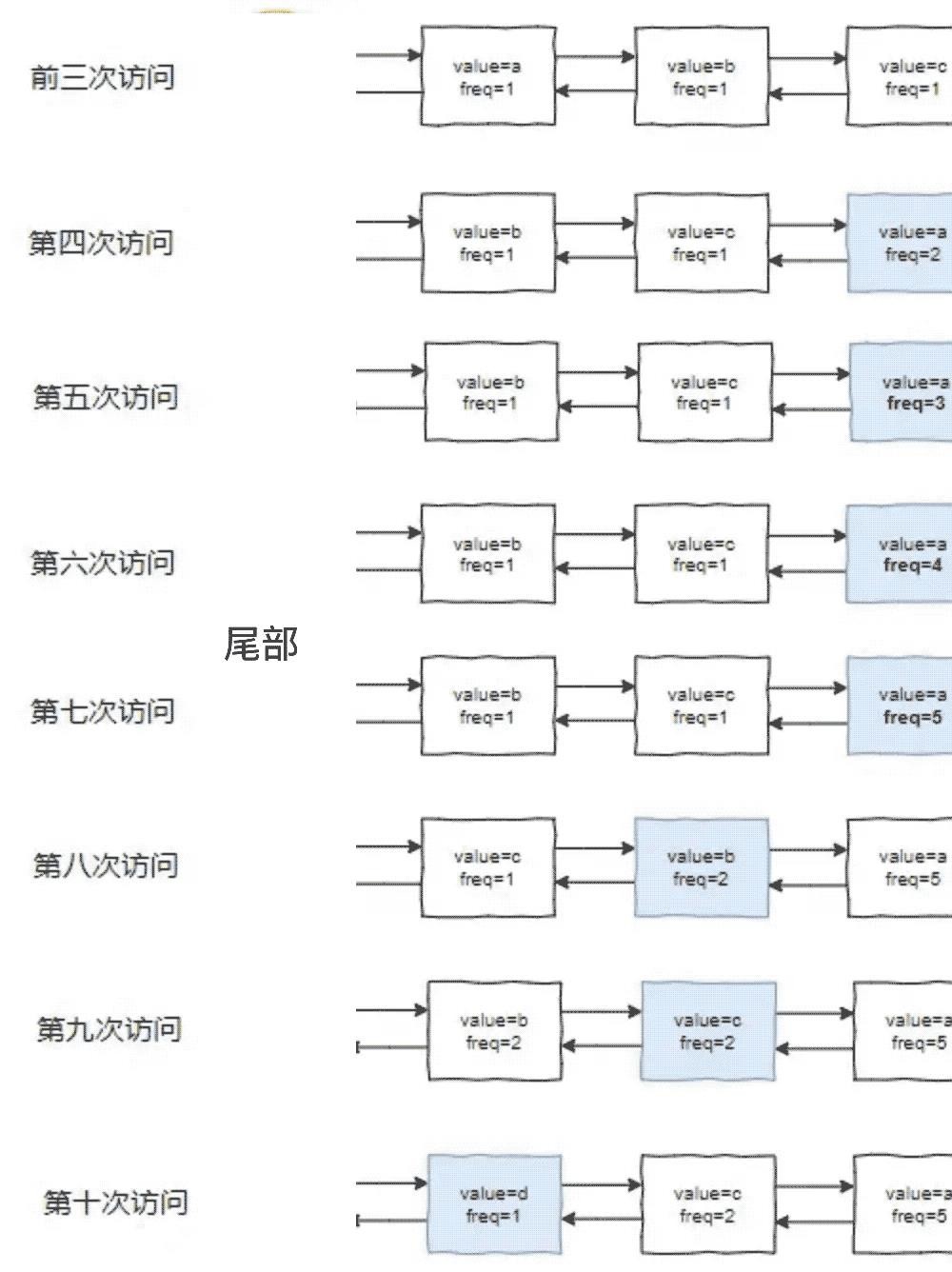
这样子做有什么缺点呢?我们来看个例子
无法复制加载中的内容
按照LRU算法进行访问和数据淘汰,10次访问的结果如下图所示
无法复制加载中的内容
10次访问结束后,缓存中剩下的数据是b、c、d三个元素,这个显然不太合理。
直观上讲,为什么说他不合理,是因为明明a是被频繁访问的数据,最终却被淘汰掉了。所以如果要改进这个算法,我们希望的是能够记录每个元素的访问频率信息,访问频率最低的那个才是最应该被淘汰的那个。
恭喜你,这就是LFU的规则。
在开始LFU之前,我们先来看一下LRU的代码怎么写。
有句古话讲得好:缓存就是Map + 淘汰策略。Map的作用是提供快速访问,淘汰策略是缓存算法的灵魂,决定了命中率的高低。根据对于LRU的描述,我们需要一个东西(术语叫做数据结构)来记录数据被访问的先后顺序,这里我们可以选择链表。
打开IDE,迅速写下第一行代码:
type LRU struct {
data map[string]*list.Element
cap int
list *list.List
}
解释一下为什么需要这几个变量, cap 是缓存中可以存放的数据个数,也就是缓存的容量上限。data就是Map。List我们用来记录数据的先后访问顺序,每次访问,都把本次访问的节点移动到链表中的头部。这样子整个链表就会按照近期的访问记录来排序了。
func (lru *LRU) add(k, v string) {
if Map中存有这条Key {
替换Map中的Value值
将链表中的对应节点移到最前面
} else {
if 已经达到缓存容量上限 {
获取链表尾部节点的Key,并从Map中删除
移除链表尾部的node
}
创建要插入的新节点
将新节点插入到链表头部
放入Map中
}
}
func (lru *LRU) get(k string) string {
if Map中存有这条Key {
返回查询到的Value
将对应节点移动到链表头部
} else {
返回 空
}
}
我们已经成功的写出了LRU算法(伪代码),接下来尝试自己写一下LFU算法。首先我们知道LFU算法比LRU多了什么,LFU需要记录每条数据的访问次数信息,并且按照访问次数从高到低排序,访问次数用什么来记录呢?
只需要在链表节点中增加一个访问频率Frequency,就可以了,这个Frequency可以使用int来存储。同时排序的规则稍加变动,不是把最近访问的放到最前面,而是按照访问频率插入到对应位置即可。如果频率相同,再按照LRU的规则,比较谁是最新访问的。
暂时无法在文档外展示此内容
讲完了LRU和LFU,我们来看一下他们有啥优缺点。
LRU
优点:实现简单、可以很快的适应访问模式的改变
缺点:对于热点数据的命中率可能不如LFU
LFU
优点:对于热点数据命中率更高
缺点:难以应对突发的稀疏流量、可能存在旧数据长期不被淘汰,会影响某些场景下的命中率(如外卖),需要额外消耗来记录和更新访问频率
Count-Min Sketch 算法
刚才提到了LFU需要统计每个条数据的访问频率,这就需要一个int或者long类型来存储次数,但是仔细一想,一条缓存数据的访问次数真的需要int类型这么大的表示范围来统计吗?我们认为一个缓存被访问15次已经算是很高的频率了,那么我们只用4个Bit就可以保存这个数据。(2^4=16)
再来介绍一个cmSketch算法,看过硬核课堂BloomFilter视频的都知道,BloomFilter利用位图的思想来标记一条数据是否存在,存在与否可以用某个Bit位的0 | 1来代替,那么我们能不能扩展一下,利用这种思想来计数呢?
我们给要计数的值计算一个Hash,然后在位图中给这个Hash值对应的位置累加1就可以了,但是BloomFilter中的一个典型问题是假阳性,可以说只要是用Hash计算就有存在冲突的可能,那么cmSketch计数法如果出现冲突会怎么样呢?会给同一个位置多计算访问次数。这里cmSketch选择了以最小的统计数据值作为结果。这是一个不那么精确地统计方法,但是可以大致的反应访问分布的规律。
因为这个算法也就有了一个名字,叫做Count-Min Sketch。
下面我们来手撕这个算法。
//根据BloomFilter来思考一下我们需要什么
//一个bit图,n个Hash函数
//一个BitMap的实现
type cmRow []byte //byte = uint8 = 0000,0000 = COUNTER 4BIT = 2 counter
//64 counter
//1 uint8 = 2counter
//32 uint8 = 64 counter
func newCmRow(numCounters int64) cmRow {
return make(cmRow, numCounters/2)
}
func (r cmRow) get(n uint64) byte {
return byte(r[n/2]>>((n&1)*4)) & 0x0f
}
0000,0000|0000,0000| 0000,0000 make([]byte, 3) = 6 counter
func (r cmRow) increment(n uint64) {
//定位到第i个Counter
i := n / 2 //r[i]
//右移距离,偶数为0,奇数为4
s := (n & 1) * 4
//取前4Bit还是后4Bit
v := (r[i] >> s) & 0x0f //0000, 1111
//没有超出最大计数时,计数+1
if v < 15 {
r[i] += 1 << s
}
}
//cmRow 100,
//保鲜
func (r cmRow) reset() {
// 计数减半
for i := range r {
r[i] = (r[i] >> 1) & 0x77 //0111,0111
}
}
func (r cmRow) clear() {
// 清空计数
for i := range r {
r[i] = 0
}
}
//快速计算最接近x的二次幂的算法
//比如x=5,返回8
//x = 110,返回128
//2^n
//1000000 (n个0)
//01111111(n个1) + 1
// x = 1001010 = 1111111 + 1 =10000000
func next2Power(x int64) int64 {
x--
x |= x >> 1
x |= x >> 2
x |= x >> 4
x |= x >> 8
x |= x >> 16
x |= x >> 32
x++
return x
}
如果我们要给n个数据计数,那么每4Bit当做一个计数器Counter,我们一共需要几个uint8来计数呢?答案是n/2
| 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 |
|---|---|---|---|---|---|---|---|
| 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 |
| 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 |
| 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 |
//cmSketch封装
const cmDepth = 4
type cmSketch struct {
rows [cmDepth]cmRow
seed [cmDepth]uint64
mask uint64
}
//numCounter - 1 = next2Power() = 0111111(n个1)
//0000,0000|0000,0000|0000,0000
//0000,0000|0000,0000|0000,0000
//0000,0000|0000,0000|0000,0000
//0000,0000|0000,0000|0000,0000
func newCmSketch(numCounters int64) *cmSketch {
if numCounters == 0 {
panic("cmSketch: bad numCounters")
}
numCounters = next2Power(numCounters)
sketch := &cmSketch{mask: uint64(numCounters - 1)}
// Initialize rows of counters and seeds.
source := rand.New(rand.NewSource(time.Now().UnixNano()))
for i := 0; i < cmDepth; i++ {
sketch.seed[i] = source.Uint64()
sketch.rows[i] = newCmRow(numCounters)
}
return sketch
}
func (s *cmSketch) Increment(hashed uint64) {
for i := range s.rows {
s.rows[i].increment((hashed ^ s.seed[i]) & s.mask)
}
}
// 找到最小的计数值
func (s *cmSketch) Estimate(hashed uint64) int64 {
min := byte(255)
for i := range s.rows {
val := s.rows[i].get((hashed ^ s.seed[i]) & s.mask)
if val < min {
min = val
}
}
return int64(min)
}
// 让所有计数器都减半,保鲜机制
func (s *cmSketch) Reset() {
for _, r := range s.rows {
r.reset()
}
}
// 清空所有计数器
func (s *cmSketch) Clear() {
for _, r := range s.rows {
r.clear()
}
}
TinyLFU解决了LFU统计的内存消耗问题,和缓存保鲜的问题,但是TinyLFU是否还有缺点呢?
有,论文中是这么描述的,根据实测TinyLFU应对突发的稀疏流量时表现不佳。大概思考一下也可以得知,这些稀疏流量的访问频次不足以让他们在LFU缓存中占据位置,很快就又被淘汰了。
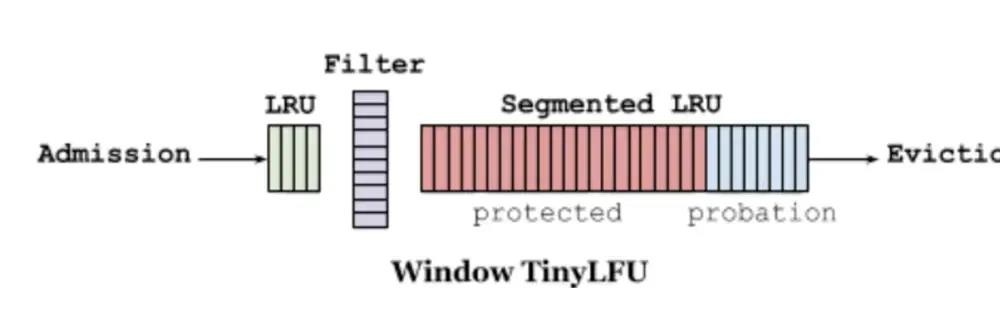
我们回顾之前讲过的,LRU对于稀疏流量效果很好,那可以不可以把LRU和LFU结合一下呢?就出现了下面这种缓存策略。
Window-TinyLFU策略里包含LRU和LFU两部分,前端的小LRU叫做Window LRU,它的容量只占据1%的总空间,它的目的就是用来存放短期的突发访问数据。存放主要元素的Segmented LRU(SLRU)是一种LRU的改进,主要把在一个时间窗口内命中至少2次的记录和命中1次的单独存放,这样就可以把短期内较频繁的缓存元素区分开来。具体做法上,SLRU包含2个固定尺寸的LRU,一个叫Probation段A1,一个叫Protection段A2。新记录总是插入到A1中,当A1的记录被再次访问,就把它移到A2,当A2满了需要驱逐记录时,会把驱逐记录插入到A1中。W-TinyLFU中,SLRU有80%空间被分配给A2段。
视频讲解
以上就是LRU LFU TinyLFU缓存算法实例详解的详细内容,更多关于LRU LFU TinyLFU缓存算法的资料请关注编程网其它相关文章!
--结束END--
本文标题: LRU LFU TinyLFU缓存算法实例详解
本文链接: https://www.lsjlt.com/news/121142.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-04-05
2024-04-05
2024-04-05
2024-04-05
2024-04-05
2024-04-05
2024-04-05
2024-04-05
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0