目录1.前言2.指针类型转换3.指针运算4.获取大小和偏移5.关于string1.前言 开发中,[]byte类型和string类型需要互相转换的场景并不少见,直接的想法是像下面这样进
开发中,[]byte类型和string类型需要互相转换的场景并不少见,直接的想法是像下面这样进行强制类型转换:
a := "Kylin Lab"
b := []byte(a)
fmt.Println(a)//Kylin Lab
fmt.Println(b)//[75 121 108 105 110 32 76 97 98]
如果接下来需要对b进行修改,那么这样转换就没什么问题,但是如果只是因为类型不合适,并不需要对转换后的变量做任何修改,那这样转换就显得不划算了。我们知道,[]byte和string的内存布局如下图所示:

可以看到它们都有一个底层数组来存储变量数据,而类型本身只记录这个数组的起始地址。如果采用强制类型转换的方式把a转换为b,那么就会重新分配b使用的底层数组。然后把a的底层数组内容拷贝到b的底层数组。如果字符串内容很多,多占用这许多字节的内存不说,还要耗费时间做拷贝,所以就显得很不合适了。

要是可以让b重复使用a的底层数组,那就好了。强转不行,就到了unsafe上场的时候了~
unsafe提供的第一件法宝就是指针类型转换。我们知道像下面这样的指针类型转换是编译不通过的。
a := "Kylin Lab"
var b []byte
tmp := (*string)(&b)
//cannot convert &b (type *[]byte) to type *string
但是你可以把任意一个指针类型转换为unsafe.Pointer类型,再把unsafe.Pointer类型转换为任意指针类型,就像下面这样是可以正常执行的:
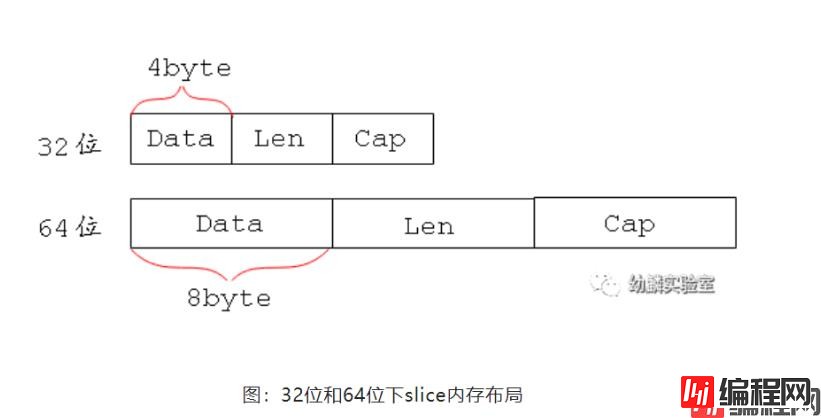
tmp := (*string)(unsafe.Pointer(&b))现在我们通过unsafe.Pointer把b的指针转换为*string类型,我们可以放心的这样做,是因为我们知道slice的底层布局与string是兼容的,b的前两项内容与a相同,都是一个uintptr和一个int。可参见reflect包中关于这两个类型的定义:
//reflect/value.Go
type StringHeader struct {
Data uintptr
Len int
}
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
我们知道上面这个例子中 变量b只初始化了变量结构,并未初始化底层数组,元素个数和容量都为0。

接下来,我们把a赋值给tmp:
a := "Kylin Lab"
var b []byte
tmp := (*string)(unsafe.Pointer(&b))
*tmp = a
fmt.Println(a) //Kylin Lab
fmt.Println(b) //[75 121 108 105 110 32 76 97 98]
fmt.Println(*tmp) //Kylin Lab
fmt.Println(tmp) //0xc000004078
fmt.Printf("%p\n", &a) //0xc00005a250
fmt.Printf("%p\n", &b) //0xc000004078
fmt.Println(&a) //0xc00005a250
fmt.Println(&b)//&[75 121 108 105 110 32 76 97 98]
现在你猜怎么着,我们已经在变量b中重复使用了a的底层数组,元素个数也填好了~
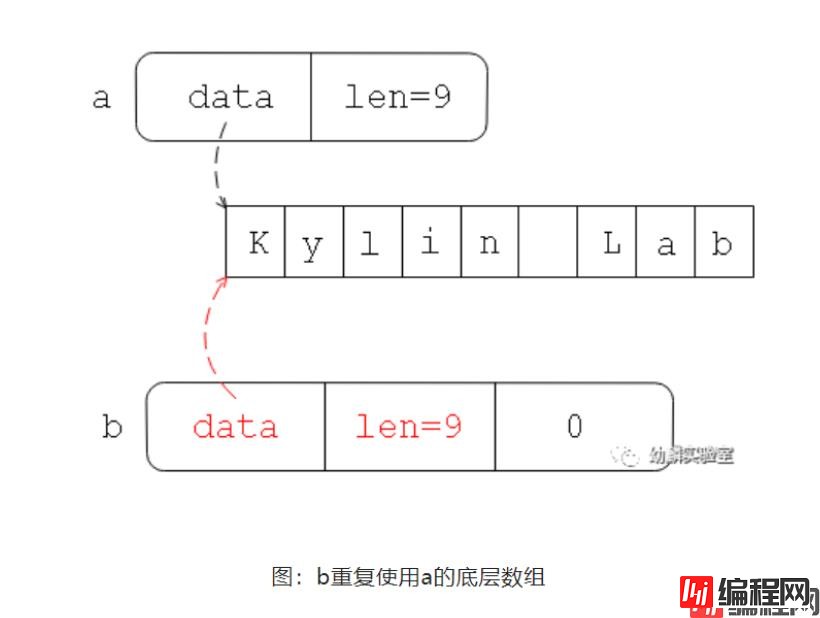
不过还没完,b的容量还为0呢!怎么修改它呢?我们能拿到b的地址,也知道data和len各占8字节(64位下),只要把b的指针加上16字节就是cap的起始地址。可问题是Go语言的指针支持做加减运算吗?不支持!
这时候就要拿出unsafe提供的第二件法宝了!
a := "Kylin Lab"
var b []byte
tmp := (*string)(unsafe.Pointer(&b))
*tmp = a
fmt.Println(len(a)) //9
fmt.Println(len(b)) //9
fmt.Println(cap(b)) //0
//unsafe/unsafe.go
package unsafe
type ArbitraryType int
type IntegerType int//引用不会出错
type Pointer *ArbitraryType
func Sizeof(x ArbitraryType) uintptr
func Offsetof(x ArbitraryType) uintptr
func Alignof(x ArbitraryType) uintptr
func Add(ptr Pointer, len IntegerType) Pointer
func Slice(ptr *ArbitraryType, len IntegerType) []ArbitraryType
//builtin/builtin.go
// uintptr is an integer type that is large enough to hold the bit pattern of
// any pointer.
type uintptr uintptr
// IntegerType is here for the purposes of documentation only. It is a stand-in
// for any integer type: int, uint, int8 etc.
type IntegerType int//引用会出错
Go语言不支持指针直接进行运算,也是为了保障程序运行安全,防止出现莫名其妙的、玄之又玄的bug。
不过unsafe.Pointer可以和各种指针类型相互转换,也可以转换为uintptr类型,uintptr本质上就是一个无符号整型,所以它是可以进行运算的。 继续上面的例子,我们可以把b的指针转换为unsafe.Pointer,再进一步转换为uintptr。
(uintptr)(unsafe.Pointer(&b))现在就把b的地址转换为uintptr类型了,64位下,如果把它加上16,就是b的容量的起始地址了。
(uintptr)(unsafe.Pointer(&b)) + 16即便如此,我们也不能直接通过uintptr来修改b的容量,因为它不是指针类型,而且也不能直接转换为指针类型。但是可以通过unsafe.Pointer类型中转一下。
tmp2 := (*int)(unsafe.Pointer((uintptr)(unsafe.Pointer(&b)) + 16))现在才算是拿到了b的容量的指针,再通过这个*int修改b的容量就OK了~
*tmp2 = len(b)目前为止,我们已经借助unsafe的两个法宝,成功完成了string到[]byte的转换,并且复用了a的底层数组。
a := "Kylin Lab"
var b []byte
tmp := (*string)(unsafe.Pointer(&b))
*tmp = a
tmp2 := (*int)(unsafe.Pointer((uintptr)(unsafe.Pointer(&b)) + 16))
*tmp2 = len(b)
fmt.Println(len(a)) //9
fmt.Println(len(b)) //9
fmt.Println(cap(b)) //9
上面tmp2赋值这一行很长,也很绕。
注:虽然下面可以编译过,但是一定不要像下面这样先使用uintptr类型的临时变量来存储一个地址,然后才把它转换为某个指针类型。
tmp2 := (uintptr)(unsafe.Pointer(&b)) + 16
capPtr := (*int)(unsafe.Pointer(tmp2))
这是因为uintptr只是一个存储着地址的无符号整型而已,它不是指针,如果垃圾回收为了减少内存碎片而移动了一些变量,内存关联到的指针类型的值是会一并修改的,但是uintptr并不会,这就可能出现一些神奇的bug,所以这一行只能这么绕着写。
除此之外,这个硬编码的“16”怎么看都显得格外不和谐。有没有什么好方法,可以获取程序运行平台中一个类型的大小呢?这就要用到unsafe提供的第三个法宝了~
unsafe.Sizeof可以拿到任意类型的大小,unsafe.Alignof可以拿到任意类型的对齐边界。按照reflect.SliceHeader的定义,我们这里可以用unsafe.Sizeof来获取uintptr和int的大小,b的起始地址偏移这么多就是第三个字段Cap的地址了。
a := "Kylin Lab"
var b []byte
tmp := (*string)(unsafe.Pointer(&b))
*tmp = a
tmp2 := (*int)(unsafe.Pointer((uintptr)(unsafe.Pointer(&b)) + unsafe.Sizeof(uintptr(1)) + unsafe.Sizeof(1)))
*tmp2 = len(b)
fmt.Println(len(a)) //9
fmt.Println(len(b)) //9
fmt.Println(cap(b)) //9
不过这样还是存在投机的成分,别忘了内存对齐哦~
这里这样写可行,是因为我们知道uintptr和int的大小不是4字节就是8字节,无论哪一种,都会紧挨着第三个字段,不会出现因内存对齐而形成的间隙。
所以unsafe还有一个unsafe.Offsetof方法可以获得结构体中某个字段距离结构体起始地址的偏移值,这样就可以确定结构体成员正确的位置了。
为了试试这个方法,我们要把b的指针转换为reflect.SliceHeader类型,其实也可以自己定义一个SliceHeader类型,但这不是有现成的可以直接拿来用嘛~
bPtr := (*reflect.SliceHeader)(unsafe.Pointer(&b)) 然后获取Cap字段在结构体内的偏移值:
unsafe.Offsetof(bPtr.Cap)再然后,就是把这个字段的地址转换为*int,然后修改它的值了:
a := "Kylin Lab"
var b []byte
tmp := (*string)(unsafe.Pointer(&b))
*tmp = a
bPtr := (*reflect.SliceHeader)(unsafe.Pointer(&b))
tmp2 := (*int)(unsafe.Pointer((uintptr)(unsafe.Pointer(&b)) + unsafe.Offsetof(bPtr.Cap)))
*tmp2 = len(b)
fmt.Println(len(a)) //9
fmt.Println(len(b)) //9
fmt.Println(cap(b)) //9
我们为了多介绍一些unsafe的功能,刻意绕了个远~
其实都把b转换为reflect.SliceHeader结构体了,改个字段值哪里要这么麻烦!!!我们大可以这样做:
strHeader := (*reflect.StringHeader)(unsafe.Pointer(&a))
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&b))
这样通过strHeader和sliceHeader想操作哪个字段都很方便。
a := "Kylin Lab"
var b []byte
strHeader := (*reflect.StringHeader)(unsafe.Pointer(&a))
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&b))
sliceHeader.Data = strHeader.Data
sliceHeader.Len = strHeader.Len
sliceHeader.Cap = strHeader.Len
fmt.Println(len(a)) //9
fmt.Println(len(b)) //9
fmt.Println(cap(b)) //9
关于string,我们还要啰嗦一点,Go语言中string变量的内容默认是不会被修改的,而我们通过给string变量整体赋新值的方式来改变它的内容时,实际上会重新分配它的底层数组。
而string类型字面量的底层数组会被分配到只读数据段,在我们的例子中,b复用了a的底层数组,所以就不能再像下面这样修改b的内容了,否则执行阶段会发生错误。
a := "Kylin Lab"
var b []byte
strHeader := (*reflect.StringHeader)(unsafe.Pointer(&a))
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&b))
sliceHeader.Data = strHeader.Data
sliceHeader.Len = strHeader.Len
sliceHeader.Cap = strHeader.Len
b[0] = 'k'
而运行时动态拼接而成的string变量,它的底层数组不在只读数据段,而是由Go语言在语法层面阻止对字符串内容的修改行为。
a := "Kylin Lab" //string字面量
c := "Hello " + a //动态拼接的字符串
c[0] = 'h' // cannot assign to c[0] 编译时报错
a := "Kylin Lab" //string字面量
a[0] = 'h' // cannot assign to c[0] 编译时报错
若我们利用unsafe让一个[]byte复用这个字符串c的底层数组,就可以绕过Go语法层面的限制,修改底层数组的内容了。
但是尽量不要这样做,如果不确定这个字符串会在哪里用到的话~
a := "Kylin Lab"
c := "Hello" + a
var s []byte
strHeader := (*reflect.StringHeader)(unsafe.Pointer(&c))
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&s))
sliceHeader.Data = strHeader.Data
sliceHeader.Len = strHeader.Len
sliceHeader.Cap = strHeader.Len
s[0] = 'h'
fmt.Println(c) //hello Kylin Lab
fmt.Println(a) //Kylin Lab
fmt.Println(string(s)) //hello Kylin Lab到此这篇关于golang unsafe包详细讲解的文章就介绍到这了,更多相关GoLang unsafe内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: GoLangunsafe包详细讲解
本文链接: https://www.lsjlt.com/news/121278.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-04-05
2024-04-05
2024-04-05
2024-04-05
2024-04-05
2024-04-05
2024-04-05
2024-04-05
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0