Python 官方文档:入门教程 => 点击学习
目录一、请求目标(URL)二、网址的组成:三、请求体(response)四、请求方法(Method)五、常用的请求报头六、requests模块查看请求体一、请求目标(URL) URL
URL又叫作统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种方法。类似于windows的文件路径。

1.Http://:这个是协议,也就是HTTP超文本传输协议,也就是网页在网上传输的协议。
2.mail:这个是服务器名,代表着是一个邮箱服务器,所以是mail。
3.163.com:这个是域名,是用来定位网站的独一无二的名字。
4.mail.163.com:这个是网站名,由服务器名+域名组成。
5./:这个是根目录,也就是说,通过网站名找到服务器,然后在服务器存放网页的根目录。
6.index.html:这个是根目录下的网页。
7.http://mail.163.com/index.html:这个叫做URL,统一资源定位符,全球性地址,用于定位网上的资源。
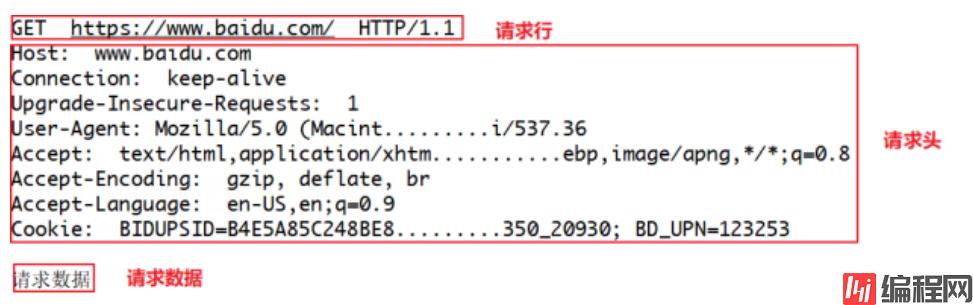
就像打电话一样,HTTP到底和服务器说了什么,才能让服务器返回正确的消息的,其实客户端的请求告诉了服务器这些内容:请求行、请求头部、空行、请求数据
HTTP请求可以使用多种请求方法,但是爬虫最主要就两种方法:GET和POST方法。
get请求:一般情况下,只从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求。
post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用
post请求。
以上是在网站开发中常用的两种方法。并且一般情况下都会遵循使用的原则。但是有的网站和服务器为了做反爬虫机制,也经常会不按常理出牌,有可能一个应该使用get方法的请求就一定要改成post请求,这个要视情况而定。
GET与POST方法的区别:
1.GET是从服务器上获取数据,POST是向服务器传送数据
2.GET请求参数都显示在浏览器网址上,即Get"请求的参数是URL的一部分。例如: http://www.baidu.com/s?wd=Chinese
3.POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据。请求的参数类型包含在"Content-Type"消息头里,指明发送请求时要提交的数据格式。
注意:
网站制作者一般不会使用Get方式提交表单,因为有可能会导致安全问题。比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。并且浏览器会记录历史信息,导致账号不安全的因素存在。
请求头描述了客户端向服务器发送请求时所使用的编码,以及发送内容的长度,告诉服务器自己有没有登陆,采用的什么浏览器访问的等等。
1.Accept:浏览器告诉服务器自己接受什么数据类型,文字,图片等。
2.Accept-charset:浏览器申明自己接收的字符集。
3.Accept-Encoding:浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip, deflate,br)。
4.Accept-Language:浏览器申明自己接收的语言。
5.Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中。
6.content-Length表示请求消息正文的长度。
7.origin:声明请求资源的起始位置
8.connection:处理完这次请求后,是断开连接还是继续保持连接。9.Cookie:发送给WEB服务器的Cookie内容,经常用来判断是否登陆了。
9.Cookie:发送给WEB服务器的Cookie内容,经常用来判断是否登陆了。
10.Host:客户端指定自己想访问的WEB服务器的域名/IP地址和端口号。
11.If-Modified-since:客户机通过这个头告诉服务器,资源的缓存时间。只有当所请求的内容在指定的时间后又经过修改才返回它,否则返回304"Not Modified"应答。
12.Pragma:指定"no-cache"值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝。
13.Referer:告诉服务器该页面从哪个页面链接的。
14.From∶请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它。
15.(user-Agent:浏览器表明自己的身份(是哪种浏览器)
16.upgrade-insecure-requests∶申明浏览器支持从http请求自动升级为https请求,并且在以后发送请求的时候都使用https。
UA-Pixels,uA-Color,uA-oS,UA-CPU:由某些版本的IE浏览器所发送的非标准的请求头,表示屏幕大小、颜色深度、操作系统和CPu类型。
在我们用requests模块请求数据的时候携带上诉请求报头的字段信息,将我们的爬虫代码进行伪装。同样的伪装之后我们也可以通过代码查看请求体的字段信息,有如下几种常见的属性:
#查看请求体中的url地址
response.request.url
#查看请求体中的请求头信息
response.request.headers
#查看请求体中的请求方法
response.request.method到此这篇关于python爬虫基础讲解之请求的文章就介绍到这了,更多相关python请求内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python爬虫基础讲解之请求
本文链接: https://www.lsjlt.com/news/125870.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0