Python 官方文档:入门教程 => 点击学习
1. 原理 2014年的一篇文章,开创cnn用到文本分类的先河。 Convolutional Neural Networks for Sentence Classification
2014年的一篇文章,开创cnn用到文本分类的先河。
Convolutional Neural Networks for Sentence Classification
原理说简单也简单,其实就是单层CNN加个全连接层:

不过与图像中的cnn相比,改动为将卷积核的宽固定为一个词向量的维度,而长度一般取2,3,4,5这样。
上图中第一幅图的每个词对应的一行为一个词向量,可以使用Word2vec或者glove预训练得到。本例中使用随机初始化的向量。
手中有三个文件,分别为train.txt,valid.txt,test.txt。其中每一行是一个字符串化的字典,格式为{‘type': ‘xx', ‘text':‘xxxxx'}。
首先将每个文件转换为csv文件,分为text和label两列。一共有4种label,可以转换为数字表示。代码如下:
# 获取文件内容
def getData(file):
f = open(file,'r')
raw_data = f.readlines()
return raw_data
# 转换文件格式
def d2csv(raw_data,label_map,name):
texts = []
labels = []
i = 0
for line in raw_data:
d = eval(line) #将每行字符串转换为字典
if len(d['type']) <= 1 or len(d['text']) <= 1: #筛掉无效数据
continue
y = label_map[d['type']] #根据label_map将label转换为数字表示
x = d['text']
texts.append(x)
labels.append(y)
i+=1
if i%1000 == 0:
print(i)
df = pd.DataFrame({'text':texts,'label':labels})
df.to_csv('data/'+name+'.csv',index=False,sep='\t') # 保存文件
label_map = {'执行':0,'刑事':1,'民事':2,'行政':3}
train_data = getData('data/train.txt') #22000+行
d2csv(train_data,label_map,'train')
valid_data = getData('data/valid.txt') # 2000+行
d2csv(valid_data,label_map,'valid')
test_data = getData('data/test.txt') # 2000+行
d2csv(test_data,label_map,'test')
对于本任务来说,需要观察每个文本分词之后的长度。因为每个句子是不一样长的,所以需要设定一个固定的长度给模型,数据中不够长的部分填充,超出部分舍去。
训练的时候只有训练数据,因此观察训练数据的文本长度分布即可。分词可以使用jieba分词等工具。
train_text = []
for line in train_data:
d = eval(line)
t = jieba.cut(d['text'])
train_text.append(t)
sentence_length = [len(x) for x in train_text] #train_text是train.csv中每一行分词之后的数据
%matplotlib notebook
import matplotlib.pyplot as plt
plt.hist(sentence_length,1000,nORMed=1,cumulative=True)
plt.xlim(0,1000)
plt.show()
得到长度的分布图:
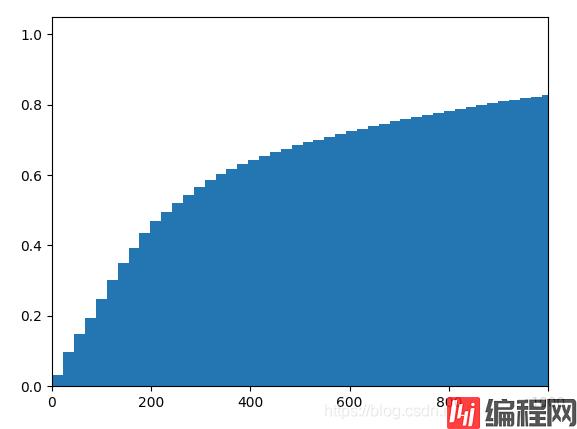
可以看到长度小于1000的文本占据所有训练数据的80%左右,因此训练时每个文本固定长度为1000个词。
目前我们手里的数据为csv形式的两列数据,一列字符串text,一列数字label。label部分不需要再处理了,不过text部分跟可训练的数据还差得远。
假设每个词对应的词向量维度为 D i m Dim Dim,每一个样本的分词后的长度已知设为 W = 1000 W=1000 W=1000,每个mini-batch的大小为 N N N。那么我们希望得到的是一个个维度为 N ∗ W ∗ D i m N*W*Dim N∗W∗Dim的浮点数数据作为mini-batch输入到模型。
于是还需要以下几个步骤:
分词去除停用词建立词汇表(词汇表是词语到index的映射,index从0到M,M为已知词汇的个数,形如{'可爱‘:0, ‘美好':1,…})将分词且去除停用词之后的数据转换为下标数据,维度应该为 N a l l ∗ W N_{all}*W Nall∗W, N a l l N_{all} Nall是所有样本的数量。其中长度不足W的样本在后面补特定字符,长度超过W的样本截断。将数据分割为一个个 N ∗ W N*W N∗W大小的mini-batch作为模型的输入。根据mini-batch数据向词向量中映射得到 N ∗ W ∗ D i m N*W*Dim N∗W∗Dim大小的最终输入。(这步在模型中)
看起来复杂哭了,手动处理起来确实有些麻烦。不过后来发现跟PyTorch很相关的有个包torchtext能够很方便的做到这几步,所以直接来介绍用这个包的做法。
在贴代码之前先贴两个torchtext的教程。torchtext入门教程 还是不懂的话看torchtext文档。 还还是不懂请直接看源码。对照教程看以下代码。
首先是分词函数,写为有一个参数的函数:
def tokenizer(x):
res = [w for w in jieba.cut(x)]
return res接着是停用词表,在网上找的一个停用词资源(也可以跳过这步):
stop_words = []
print('build stop words set')
with open('data/stopwords.dat') as f:
for l in f.readlines():
stop_words.append(l.strip())然后设定TEXT和LABEL两个field。定义以及参数含义看上面的文档或教程。
TEXT = data.Field(sequential=True, tokenize=tokenizer,fix_length=1000,stop_words=stop_words)
LABEL = data.Field(sequential=False,use_vocab=False)读取文件,分词,去掉停用词等等。直接一波带走:
train,valid,test = data.TabularDataset.splits(path='data',train='train.csv',
validation='valid.csv',test='test.csv',
format='csv',
skip_header=True,csv_reader_params={'delimiter':'\t'},
fields=[('text',TEXT),('label',LABEL)])建立词汇表:
TEXT.build_vocab(train)生成iterator形式的mini-batch数据:
train_iter, val_iter, test_iter = data.Iterator.splits((train,valid,test),
batch_sizes=(args.batch_size,args.batch_size,args.batch_size),
device=args.device,
sort_key=lambda x:len(x.text),
sort_within_batch=False,
repeat=False)That's all! 简单得令人发指!虽然为了搞懂这几个函数整了大半天。最终的这几个xxx_iter就会生成我们需要的维度为N ∗ W N*WN∗W的数据。
模型其实相对很简单,只有一个embedding映射,加一层cnn加一个激活函数以及一个全连接。
不过需要注意使用不同大小的卷积核的写法。
可以选择使用多个nn.Conv2d然后手动拼起来,这里使用nn.ModuleList模块。其实本质上还是使用多个Conv2d然后拼起来。
import torch
import torch.nn as nn
import torch.nn.functional as F
class textCNN(nn.Module):
def __init__(self, args):
super(textCNN, self).__init__()
self.args = args
Vocab = args.embed_num ## 已知词的数量
Dim = args.embed_dim ##每个词向量长度
Cla = args.class_num ##类别数
Ci = 1 ##输入的channel数
Knum = args.kernel_num ## 每种卷积核的数量
Ks = args.kernel_sizes ## 卷积核list,形如[2,3,4]
self.embed = nn.Embedding(Vocab,Dim) ## 词向量,这里直接随机
self.convs = nn.ModuleList([nn.Conv2d(Ci,Knum,(K,Dim)) for K in Ks]) ## 卷积层
self.dropout = nn.Dropout(args.dropout)
self.fc = nn.Linear(len(Ks)*Knum,Cla) ##全连接层
def forward(self,x):
x = self.embed(x) #(N,W,D)
x = x.unsqueeze(1) #(N,Ci,W,D)
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs] # len(Ks)*(N,Knum,W)
x = [F.max_pool1d(line,line.size(2)).squeeze(2) for line in x] # len(Ks)*(N,Knum)
x = torch.cat(x,1) #(N,Knum*len(Ks))
x = self.dropout(x)
logit = self.fc(x)
return logit
import os
import sys
import torch
import torch.autograd as autograd
import torch.nn.functional as F
def train(train_iter, dev_iter, model, args):
if args.cuda:
model.cuda(args.device)
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
steps = 0
best_acc = 0
last_step = 0
model.train()
print('training...')
for epoch in range(1, args.epochs+1):
for batch in train_iter:
feature, target = batch.text, batch.label #(W,N) (N)
feature.data.t_()
if args.cuda:
feature, target = feature.cuda(), target.cuda()
optimizer.zero_grad()
logit = model(feature)
loss = F.cross_entropy(logit, target)
loss.backward()
optimizer.step()
steps += 1
if steps % args.log_interval == 0:
result = torch.max(logit,1)[1].view(target.size())
corrects = (result.data == target.data).sum()
accuracy = corrects*100.0/batch.batch_size
sys.stdout.write('\rBatch[{}] - loss: {:.6f} acc: {:.4f}$({}/{})'.format(steps,
loss.data.item(),
accuracy,
corrects,
batch.batch_size))
if steps % args.dev_interval == 0:
dev_acc = eval(dev_iter, model, args)
if dev_acc > best_acc:
best_acc = dev_acc
last_step = steps
if args.save_best:
save(model,args.save_dir,'best',steps)
else:
if steps - last_step >= args.early_stop:
print('early stop by {} steps.'.format(args.early_stop))
elif steps % args.save_interval == 0:
save(model,args.save_dir,'snapshot',steps)
训练脚本中还有设置optimizer以及loss的部分。其余部分比较trivial。
模型的保存:
def save(model, save_dir, save_prefix, steps):
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
save_prefix = os.path.join(save_dir,save_prefix)
save_path = '{}_steps_{}.pt'.format(save_prefix,steps)
torch.save(model.state_dict(),save_path)
def eval(data_iter, model, args):
model.eval()
corrects, avg_loss = 0,0
for batch in data_iter:
feature, target = batch.text, batch.label
feature.data.t_()
if args.cuda:
feature, target = feature.cuda(), target.cuda()
logit = model(feature)
loss = F.cross_entropy(logit,target)
avg_loss += loss.data[0]
result = torch.max(logit,1)[1]
corrects += (result.view(target.size()).data == target.data).sum()
size = len(data_iter.dataset)
avg_loss /= size
accuracy = 100.0 * corrects/size
print('\nEvaluation - loss: {:.6f} acc: {:.4f}%({}/{}) \n'.format(avg_loss,accuracy,corrects,size))
return accuracy这暂时就不贴了。可以参考下一部分给出的GitHub。
最终在测试集合上accuracy为97%(毕竟只是四分类)。
但是遇到个问题就是随着accuracy上升,loss也在迅速增大。
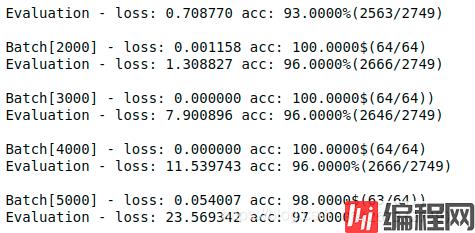
在一番探究之后大致得出结论就是,这样是没问题的。比如在本例中是个四分类,加入全连接层输出的结果是[-10000,0,0,10000],而正确分类是0。
那么这就是个错误的结果。计算一下这个单个样例的loss。先算softmax,约等于[ e − 20000 , e − 10000 , e − 10000 , 1 e^{-20000},e^{-10000},e^{-10000},1 e−20000,e−10000,e−10000,1]。真实的label为[1,0,0,0],因此交叉熵为20000。
所以我们发现这一个错误样例的loss就会这么大。最终的loss大一些也是正常的。
不过为什么随着accuracy接近100%而导致loss迅速增加这个问题还需要进一步研究。大概是因为随着accuracy升高导致结果接近训练集的分布,这样与验证集或测试集的分布产生比较极端差别的个例会增加。
代码部分参考了很多这位老哥的github,在此感谢。跟他不一样的地方主要是数据处理部分。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。
--结束END--
本文标题: pytorch实现textCNN的具体操作
本文链接: https://www.lsjlt.com/news/126126.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作



0