Python 官方文档:入门教程 => 点击学习
利用百度 ai 开发平台的 OCR 文字识别 api 识别并提取图片中的文字。首先需注册获取 API 调用的 ID 和 key,步骤如下: 打开百度AI开放平台,进入控制台中的文字识
利用百度 ai 开发平台的 OCR 文字识别 api 识别并提取图片中的文字。首先需注册获取 API 调用的 ID 和 key,步骤如下:
打开百度AI开放平台,进入控制台中的文字识别应用(需要有百度账号)。
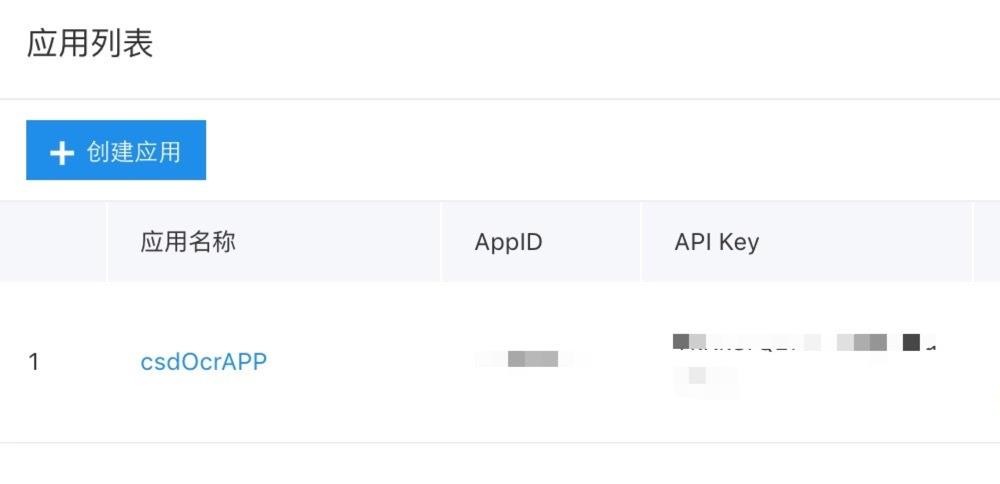
创建一个应用,并进入管理应用,记下 AppID, API Key, Secrect Key,调用 API需用到。

最后安装 python 的百度ai接口的的库
pip install baidu-aip
以下是代码实现,需将所有识别的图片放进名为 picture 的文件夹。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Jun 12 09:37:38 2018
利用百度api实现图片文本识别
@author: XnCSD
"""
import glob
from os import path
import os
from aip import AipOcr
from PIL import Image
def convertimg(picfile, outdir):
'''调整图片大小,对于过大的图片进行压缩
picfile: 图片路径
outdir: 图片输出路径
'''
img = Image.open(picfile)
width, height = img.size
while(width*height > 4000000): # 该数值压缩后的图片大约 两百多k
width = width // 2
height = height // 2
new_img=img.resize((width, height),Image.BILINEAR)
new_img.save(path.join(outdir,os.path.basename(picfile)))
def baiduOCR(picfile, outfile):
"""利用百度api识别文本,并保存提取的文字
picfile: 图片文件名
outfile: 输出文件
"""
filename = path.basename(picfile)
APP_ID = '******' # 刚才获取的 ID,下同
API_KEY = '******'
SECRECT_KEY = '******'
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
i = open(picfile, 'rb')
img = i.read()
print("正在识别图片:\t" + filename)
message = client.basicGeneral(img) # 通用文字识别,每天 50 000 次免费
#message = client.basicAccurate(img) # 通用文字高精度识别,每天 800 次免费
print("识别成功!")
i.close();
with open(outfile, 'a+') as fo:
fo.writelines("+" * 60 + '\n')
fo.writelines("识别图片:\t" + filename + "\n" * 2)
fo.writelines("文本内容:\n")
# 输出文本内容
for text in message.get('Words_result'):
fo.writelines(text.get('words') + '\n')
fo.writelines('\n'*2)
print("文本导出成功!")
print()
if __name__ == "__main__":
outfile = 'export.txt'
outdir = 'tmp'
if path.exists(outfile):
os.remove(outfile)
if not path.exists(outdir):
os.mkdir(outdir)
print("压缩过大的图片...")
// 首先对过大的图片进行压缩,以提高识别速度,将压缩的图片保存与临时文件夹中
for picfile in glob.glob("picture/*"):
convertimg(picfile, outdir)
print("图片识别...")
for picfile in glob.glob("tmp/*"):
baiduOCR(picfile, outfile)
os.remove(picfile)
print('图片文本提取结束!文本输出结果位于 %s 文件中。' % outfile)
os.removedirs(outdir)
到此这篇关于Python基于百度API识别并提取图片中文字的文章就介绍到这了,更多相关Python百度API识别图片文字内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python基于百度API识别并提取图片中文字
本文链接: https://www.lsjlt.com/news/129222.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0