Python 官方文档:入门教程 => 点击学习
目录前言一、配置环境1. 安装python依赖2. 安装识别引擎二、使用步骤1.引入库2.提取图片文字3.运行效果总结 提示:本文多图,请手机端注意流量。 前言 利用Python做图

提示:本文多图,请手机端注意流量。
利用Python做图片识别,识别提取图片中的文字会有很多方法,但是想要简单一点怎么办,那就可以使用tesseract识别引擎来实现,一行代码就可以做到提取图片文本。
本程序用到了两个python库,pytesseract和PIL,所以先来安装。
运行以下命令
pip install Pillow
pip install pytesseract 如果在python中没有报错,说明程序安装成功,
安装完以上两个依赖还需要对应的识别引擎。点击去下载
咱们直接使用5月10号构建的最新版本。

安装tesseract识别引擎(可跳过)
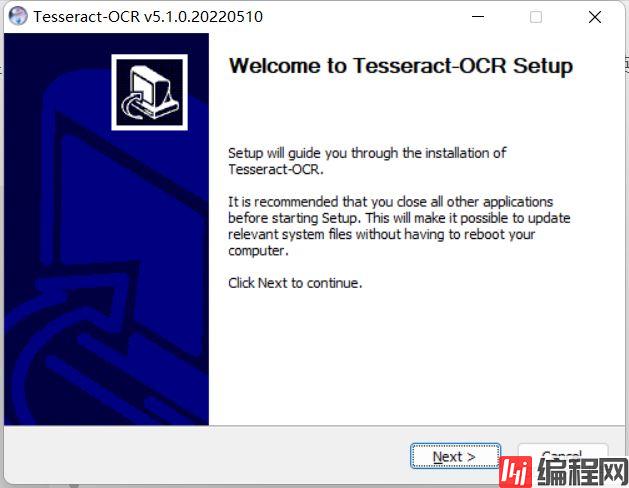
下载完成后打开程序进行安装,先选择语言,这里选择英语English就行,然后点ok

接下来就是next,完了点击I Agree同意协议,

为所有用户安装,然后点next,如图,

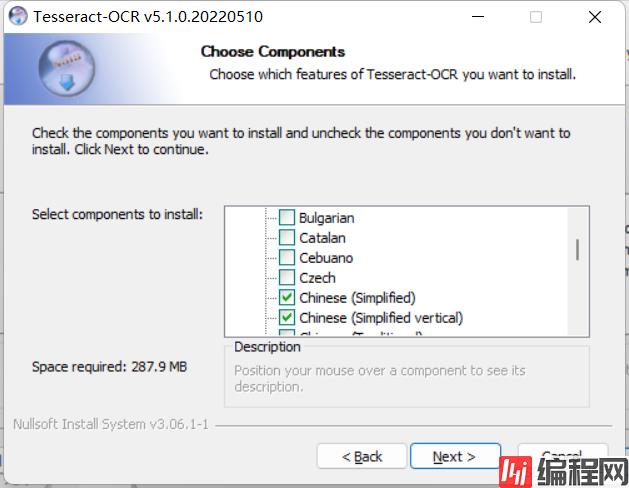
接下来安装中文的语言包用来识别中文,需要滑到下面,选择中文,我这里横排简体中文和竖排简体中文都选择了,完成后点击next,

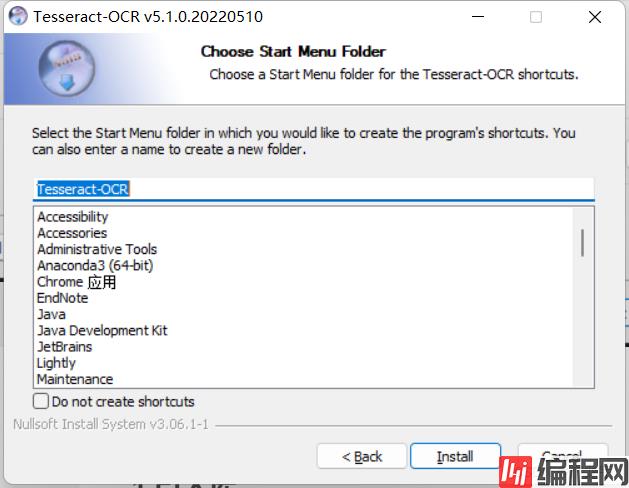
选择安装路径,建议安装到C盘以外,然后点击next

这里点击安装install,
等待安装完成
安装完成后,点击next,再点击finish完成安装,

验证是否安装成功
添加环境变量,就是你安装到的那个文件夹路径,直接加到path里面,
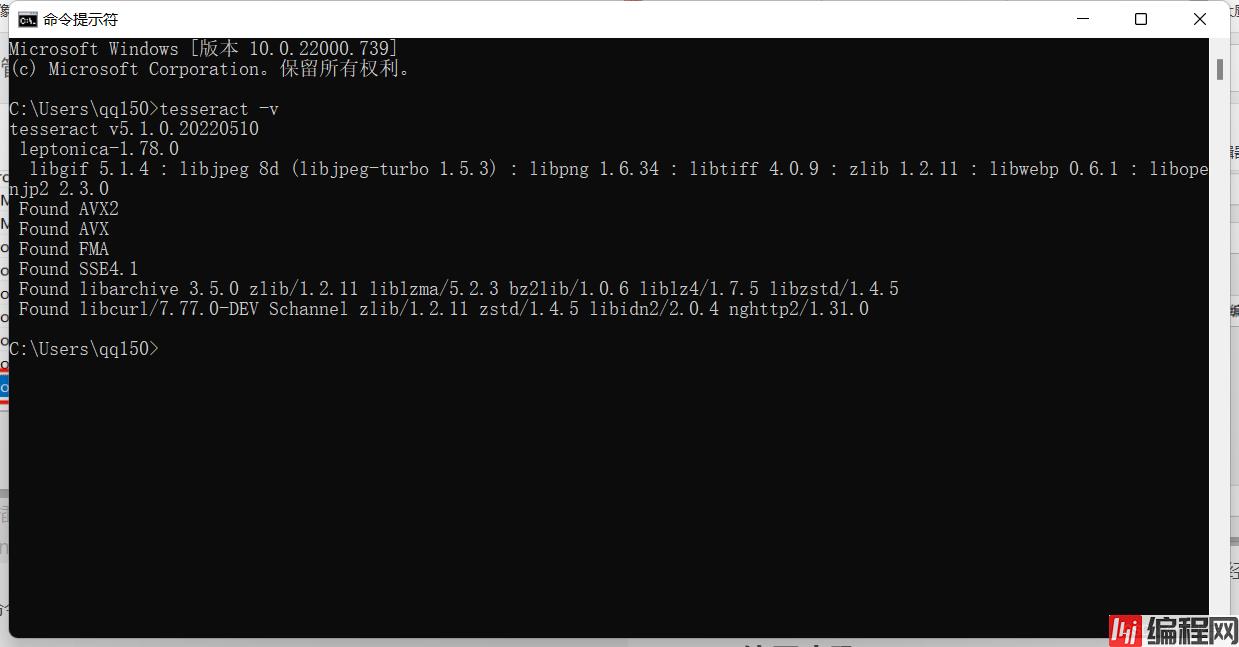
然后在命令行运行tesseract -v,如果和下图一样,说明你已经安装成功了,
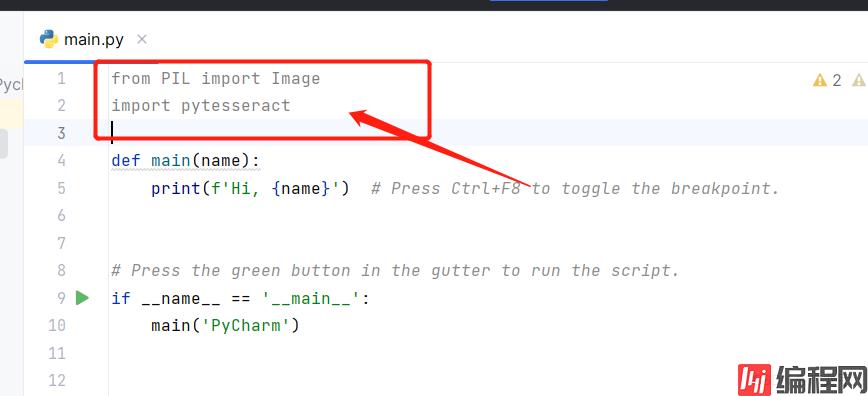
from PIL import Image
import pytesseract
将读取图片的一行代码封装为一个函数,
def read_image(name):
print(pytesseract.image_to_string(Image.open(name), lang='chi_sim'))
在main函数中直接调用即可,
def main():
read_image('1657158527412.jpg')以以下图片为例,

运行效果如下,

本文介绍了tesseract的python调用,也就是pytesseract库,其中还有一些其他的内容并没有涉及,仅涉及到了图片提取文字,如果你对其感兴趣,可以深入探索一下,也希望能和我探讨一下。
完整代码
from PIL import Image
import pytesseract
def read_image(name):
print(pytesseract.image_to_string(Image.open(name), lang='chi_sim'))
def main():
read_image('img.png')
if __name__ == '__main__':
main()到此这篇关于python利用 pytesseract快速识别提取图片中的文字( 图片识别)的文章就介绍到这了,更多相关python pytesseract识别图片文字内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: python利用pytesseract快速识别提取图片中的文字((图片识别)
本文链接: https://www.lsjlt.com/news/171175.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0