Python 官方文档:入门教程 => 点击学习
由于微博的网页端有反爬虫,需要登录,所以我们换个思路,曲线救国。 我们找到微博在浏览器上面用于手机端的调试的APL,如何找到呢? 我这边直接附上微博的手机端的地址:https://
由于微博的网页端有反爬虫,需要登录,所以我们换个思路,曲线救国。
我们找到微博在浏览器上面用于手机端的调试的APL,如何找到呢?
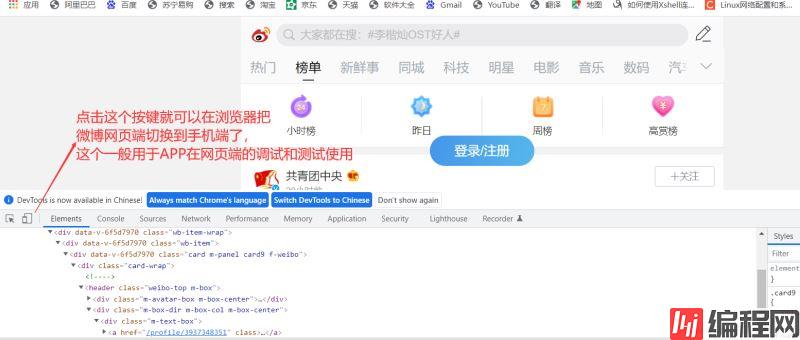
我这边直接附上微博的手机端的地址:https://m.weibo.cn/
1.模拟搜索用户
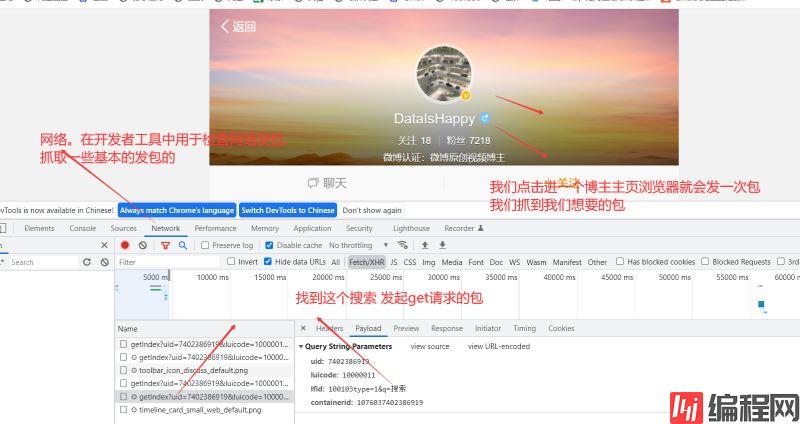
搜索一个用户获取到的api:
Https://m.weibo.cn/api/container/getIndex?containerid=100103type=1&q=半半子&page_type=searchall
1.1 对api内参数进行处理
containerid=100103type=1&q=半半子 ——> containerid=100103type%3D1%26q%3D%E5%8D%8A%E5%8D%8A%E5%AD%90_
这个参数需要提前转码,否则无法获取数据
1.2 对用户名进行判断,通过后提取uid
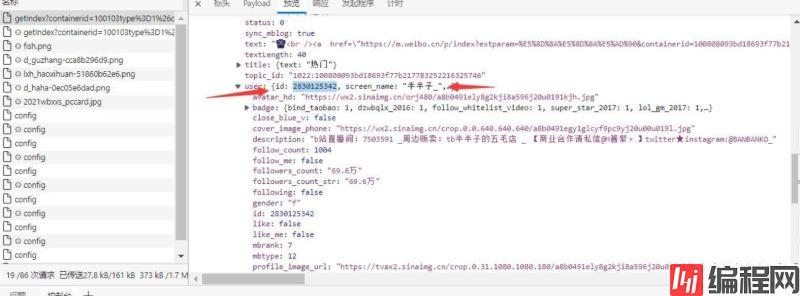
2.获取more参数
GET
api : https://m.weibo.cn/profile/info?uid=2830125342
2.1 提取并处理more参数
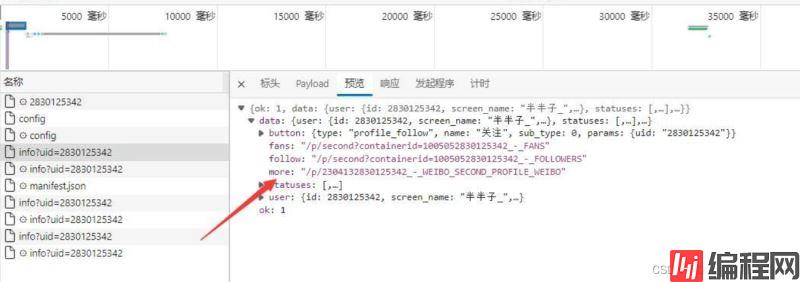
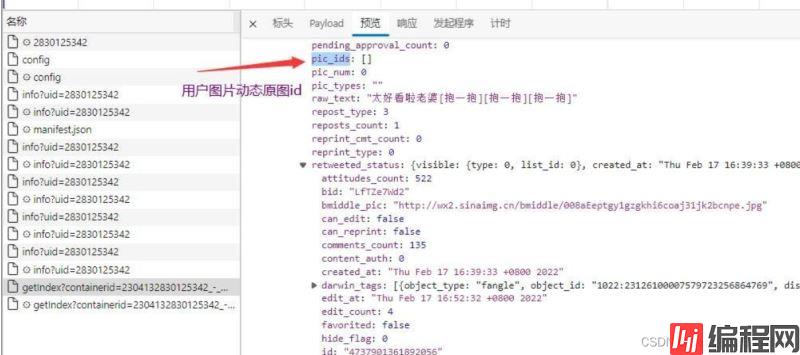
3.循环提取图片id
GET
api : https://m.weibo.cn/api/container/getIndex?containerid=2304132830125342_-_WEIBO_SECOND_PROFILE_WEIBO&page_type=03&page=1
3.1 提取图片id——>pic_id
3.2 获取发送图片用户
3.3 根据动态创建时间生成用户唯一识别码
4.下载图片
我们从浏览器抓包中就会获取到后台服务器发给浏览器的图片链接
https://wx2.sinaimg.cn/large/pic_id.jpg
浏览器打开这个链接就可以直接下载图片
爬取完整代码:
import os
import sys
import time
from urllib.parse import quote
import requests
headers = {
'user-agent': 'Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (Khtml, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
def time_to_str(c_at):
ti = time.strptime(c_at, '%a %b %d %H:%M:%S +0800 %Y')
time_str = time.strftime('%Y%m%d%H%M%S', ti)
return time_str
# 1. 搜索用户,获取uid
# 2. 通过uid获取空间动态关键参数
# 3. 获取动态内容
# 4. 提取图片参数
# 5. 下载图片
# 1. 搜索用户,获取uid
# ========= 用户名 =========
# 输入不同的用户名可切换下载的用户图片
# 用户名需要完全匹配
name = '半半子_'
# =========================
con_id = f'100103type=1&q={name}'
# 这个条件需要转码
con_id = quote(con_id, 'utf-8')
user_url = f'https://m.weibo.cn/api/container/getIndex?containerid={con_id}&page_type=searchall'
user_JSON = requests.get(url=user_url, headers=headers).json()
user_cards = user_json['data']['cards']
for card_num in range(len(user_cards)):
if 'mblog' in user_cards[card_num]:
if user_cards[card_num]['mblog']['user']['screen_name'] == name:
print(f'正在获取{name}的空间')
# 2. 通过uid获取空间动态关键参数
user_id = user_cards[card_num]['mblog']['user']['id']
info_url = f'https://m.weibo.cn/profile/info?uid={user_id}'
info_json = requests.get(url=info_url, headers=headers).json()
more_card = info_json['data']['more'].split("/")[-1]
break
file_name = 'weibo'
if not os.path.exists(file_name):
os.mkdir(file_name)
if len(more_card) == 0:
sys.exit()
page_type = '03'
page = 0
while True:
# 3. 获取动态内容
page += 1
url = f'https://m.weibo.cn/api/container/getIndex?containerid={more_card}&page_type={page_type}&page={page}'
param = requests.get(url=url, headers=headers).json()
cards = param['data']['cards']
print(f'第 {page} 页')
for i in range(len(cards)):
card = cards[i]
if card['card_type'] != 9:
continue
mb_log = card['mblog']
# 4. 提取图片参数
# 获取本人的图片
pic_ids = mb_log['pic_ids']
user_name = mb_log['user']['screen_name']
created_at = mb_log['created_at']
if len(pic_ids) == 0:
# 获取转发的图片
if 'retweeted_status' not in mb_log:
continue
if 'pic_ids' not in mb_log['retweeted_status']:
continue
pic_ids = mb_log['retweeted_status']['pic_ids']
user_name = mb_log['retweeted_status']['user']['screen_name']
created_at = mb_log['retweeted_status']['created_at']
time_name = time_to_str(created_at)
pic_num = 1
print(f'======== {user_name} ========')
# 5. 下载图片
for pic_id in pic_ids:
pic_url = f'https://wx2.sinaimg.cn/large/{pic_id}.jpg'
pic_data = requests.get(pic_url, headers)
# 文件名 用户名_日期(年月日时分秒)_编号.jpg
# 例:半半子__20220212120146_1.jpg
with open(f'{file_name}/{user_name}_{time_name}_{pic_num}.jpg', mode='wb') as f:
f.write(pic_data.content)
print(f' 正在下载:{pic_id}.jpg')
pic_num += 1
time.sleep(2)
到此这篇关于python实现微博动态图片爬取详解的文章就介绍到这了,更多相关Python微博图片爬取内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python实现微博动态图片爬取详解
本文链接: https://www.lsjlt.com/news/141609.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0