Python 官方文档:入门教程 => 点击学习
简介 快乐在满足中求,烦恼多从欲中来 记录程序的点点滴滴。 输入一个网址从这个网址中解析出图片,并将它保存在本地 流程图 程序分析 解析主网址 def get_urls():
快乐在满足中求,烦恼多从欲中来
记录程序的点点滴滴。
输入一个网址从这个网址中解析出图片,并将它保存在本地
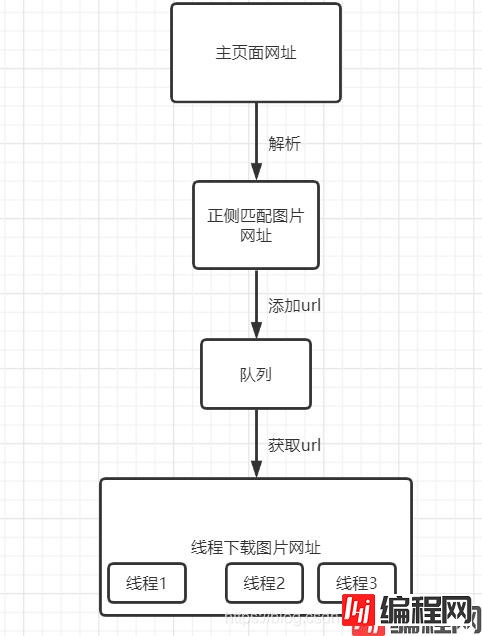
解析主网址
def get_urls():
url = 'Http://www.nipic.com/show/35350678.html' # 主网址
pattern = "(http.*?jpg)"
header = {
'user-agent': 'Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
r = requests.get(url,headers=header)
r.encoding = r.apparent_encoding
html = r.text
urls = re.findall(pattern,html)
return urls
url 为需要爬的主网址
pattern 为正则匹配
header 设置请求头
r = requests.get(url,headers=header) 发送请求
r.encoding = r.apparent_encoding 设置编码格式,防止出现乱码
| 属性 | 说明 |
|---|---|
| r.encoding | 从http header中提取响应内容编码 |
| r.apparent_encoding | 从内容中分析出的响应内容编码 |
urls = re.findall(pattern,html) 进行正则匹配
re.findall(pattern, string, flags=0)
正则 re.findall 的简单用法(返回string中所有与pattern相匹配的全部字串,返回形式为数组)
下载图片并存储
def download(url_queue: queue.Queue()):
while True:
url = url_queue.get()
root_path = 'F:\\1\\' # 图片存放的文件夹位置
file_path = root_path + url.split('/')[-1] #图片存放的具体位置
try:
if not os.path.exists(root_path): # 判断文件夹是是否存在,不存在则创建一个
os.makedirs(root_path)
if not os.path.exists(file_path): # 判断文件是否已存在
r = requests.get(url)
with open(file_path,'wb') as f:
f.write(r.content)
f.close()
print('图片保存成功')
else:
print('图片已经存在')
except Exception as e:
print(e)
print('线程名: ', threading.current_thread().name,"url_queue.size=", url_queue.qsize())
此函数需要传一个参数为队列
queue模块中提供了同步的、线程安全的队列类,queue.Queue()为一种先入先出的数据类型,队列实现了锁原语,能够在多线程中直接使用。可以使用队列来实现线程间的同步。
url_queue: queue.Queue() 这是一个队列类型的数据,是用来存储图片URL
url = url_queue.get() 从队列中取出一个url
url_queue.qsize() 返回队形内元素个数
全部代码
import requests
import re
import os
import threading
import queue
def get_urls():
url = 'http://www.nipic.com/show/35350678.html' # 主网址
pattern = "(http.*?jpg)"
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
r = requests.get(url,headers=header)
r.encoding = r.apparent_encoding
html = r.text
urls = re.findall(pattern,html)
return urls
def download(url_queue: queue.Queue()):
while True:
url = url_queue.get()
root_path = 'F:\\1\\' # 图片存放的文件夹位置
file_path = root_path + url.split('/')[-1] #图片存放的具体位置
try:
if not os.path.exists(root_path):
os.makedirs(root_path)
if not os.path.exists(file_path):
r = requests.get(url)
with open(file_path,'wb') as f:
f.write(r.content)
f.close()
print('图片保存成功')
else:
print('图片已经存在')
except Exception as e:
print(e)
print('线程名:', threading.current_thread().name,"图片剩余:", url_queue.qsize())
if __name__ == "__main__":
url_queue = queue.Queue()
urls = tuple(get_urls())
for i in urls:
url_queue.put(i)
t1 = threading.Thread(target=download,args=(url_queue,),name="craw{}".fORMat('1'))
t2 = threading.Thread(target=download,args=(url_queue,),name="craw{}".format('2'))
t1.start()
t2.start()
到此这篇关于python 爬取网页图片详解流程的文章就介绍到这了,更多相关Python 爬取网页图片内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python 爬取网页图片详解流程
本文链接: https://www.lsjlt.com/news/156799.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0