Python 官方文档:入门教程 => 点击学习
目录第一种方法:python操作xml文件提取某个单个字段批量提取某个标签值,并将其写入文本第二种:正则提取xml指定内容方法总结第一种方法:Python操作xml文件 随手找了一个
随手找了一个xml文件内容(jenkins相关文件)
<?xml version="1.0" encoding="UTF-8"?>
<!--
The MIT License
Copyright (c) 2004-2009, Sun Microsystems, Inc., Kohsuke Kawaguchi, Tom Huybrechts, id:digerata, Yahoo! Inc.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
-->
<WEB-app xmlns="Http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
version="3.1"
metadata-complete="true">
<display-name>Jenkins v2.336</display-name>
<description>Build management system</description>
<servlet>
<servlet-name>Stapler</servlet-name>
<servlet-class>org.kohsuke.stapler.Stapler</servlet-class>
<init-param>
<param-name>default-encodings</param-name>
<param-value>text/html=UTF-8</param-value>
</init-param>
<init-param>
<param-name>diagnosticThreadName</param-name>
<param-value>false</param-value>
</init-param>
<async-supported>true</async-supported>
</servlet>
<servlet-mapping>
<servlet-name>Stapler</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
<filter>
<filter-name>suspicious-request-filter</filter-name>
<filter-class>jenkins.security.SuspiciousRequestFilter</filter-class>
<async-supported>true</async-supported>
</filter>
<filter>
<filter-name>diagnostic-name-filter</filter-name>
<filter-class>org.kohsuke.stapler.DiagnosticThreadNameFilter</filter-class>
<async-supported>true</async-supported>
</filter>
<filter>
<filter-name>encoding-filter</filter-name>
<filter-class>hudson.util.CharacterEncodingFilter</filter-class>
<async-supported>true</async-supported>
</filter>
<filter>
<filter-name>compression-filter</filter-name>
<filter-class>org.kohsuke.stapler.compression.CompressionFilter</filter-class>
<async-supported>true</async-supported>
</filter>
<filter>
<filter-name>authentication-filter</filter-name>
<filter-class>hudson.security.HudsonFilter</filter-class>
<async-supported>true</async-supported>
</filter>
<filter>
<filter-name>csrf-filter</filter-name>
<filter-class>hudson.security.csrf.CrumbFilter</filter-class>
<async-supported>true</async-supported>
</filter>
<filter>
<filter-name>plugins-filter</filter-name>
<filter-class>hudson.util.PluginServletFilter</filter-class>
<async-supported>true</async-supported>
</filter>
<!--
The Headers filter allows us to override headers sent by the container
that may be in conflict with what we want. For example, Tomcat will set
Cache-Control: no-cache for any files behind the security-constraint
below. So if Hudson is on a public server, and you want to only allow
authorized users to access it, you may want to pay attention to this.
See: http://www.nabble.com/No-browser-caching-with-Hudson- -tf4601857.html
<filter>
<filter-name>change-headers-filter</filter-name>
<filter-class>hudson.ResponseHeaderFilter</filter-class>
<!- The value listed here is for 24 hours. Increase or decrease as you see
fit. Value is in seconds. Make sure to keep the public option ->
<init-param>
<param-name>Cache-Control</param-name>
<param-value>max-age=86400, public</param-value>
</init-param>
<!- It turns out that Tomcat just doesn't want to let
Go of its cache option. If you override Cache-Control,
it starts to send Pragma: no-cache as a backup.
->
<init-param>
<param-name>Pragma</param-name>
<param-value>public</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>change-headers-filter</filter-name>
<url-pattern>*.CSS</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>change-headers-filter</filter-name>
<url-pattern>*.gif</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>change-headers-filter</filter-name>
<url-pattern>*.js</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>change-headers-filter</filter-name>
<url-pattern>*.png</url-pattern>
</filter-mapping>
-->
<filter-mapping>
<filter-name>suspicious-request-filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>diagnostic-name-filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>encoding-filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>compression-filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>authentication-filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>csrf-filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>plugins-filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<listener>
<!-- Must be before WebAppMain in order to initialize the context before the first use of this class. -->
<listener-class>jenkins.util.SystemProperties$Listener</listener-class>
</listener>
<listener>
<listener-class>hudson.WebAppMain</listener-class>
</listener>
<listener>
<listener-class>jenkins.JenkinshttpsessionListener</listener-class>
</listener>
<!--
JENKINS-1235 suggests containers interpret '*' as "all roles defined in web.xml"
as opposed to "all roles defined in the security realm", so we need to list some
common names in the hope that users will have at least one of those roles.
-->
<security-role>
<role-name>admin</role-name>
</security-role>
<security-role>
<role-name>user</role-name>
</security-role>
<security-role>
<role-name>hudson</role-name>
</security-role>
<security-constraint>
<web-resource-collection>
<web-resource-name>Hudson</web-resource-name>
<url-pattern>/loginEntry</url-pattern>
<!--http-method>GET</http-method-->
</web-resource-collection>
<auth-constraint>
<role-name>**</role-name>
</auth-constraint>
</security-constraint>
<!-- Disable TRACE method with security constraint (copied from jetty/webdefaults.xml) -->
<security-constraint>
<web-resource-collection>
<web-resource-name>Disable TRACE</web-resource-name>
<url-pattern>/*</url-pattern>
<http-method>TRACE</http-method>
</web-resource-collection>
<auth-constraint />
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>other</web-resource-name>
<url-pattern>/*</url-pattern>
</web-resource-collection>
<!-- no security constraint -->
</security-constraint>
<login-config>
<auth-method>FORM</auth-method>
<form-login-config>
<form-login-page>/login</form-login-page>
<form-error-page>/loginError</form-error-page>
</form-login-config>
</login-config>
<!-- if specified, this value is used as the Hudson home directory -->
<env-entry>
<env-entry-name>HUDSON_HOME</env-entry-name>
<env-entry-type>java.lang.String</env-entry-type>
<env-entry-value></env-entry-value>
</env-entry>
<!-- configure additional extension-content-type mappings -->
<mime-mapping>
<extension>xml</extension>
<mime-type>application/xml</mime-type>
</mime-mapping>
<!--mime-mapping> commenting out until this works out of the box with JOnAS. See http://www.nabble.com/Error-with-mime-type%2D-%27application-xslt%2Bxml%27-when-deploying-hudson-1.316-in-jonas-td24740489.html
<extension>xsl</extension>
<mime-type>application/xslt+xml</mime-type>
</mime-mapping-->
<mime-mapping>
<extension>log</extension>
<mime-type>text/plain</mime-type>
</mime-mapping>
<mime-mapping>
<extension>war</extension>
<mime-type>application/octet-stream</mime-type>
</mime-mapping>
<mime-mapping>
<extension>ear</extension>
<mime-type>application/octet-stream</mime-type>
</mime-mapping>
<mime-mapping>
<extension>rar</extension>
<mime-type>application/octet-stream</mime-type>
</mime-mapping>
<mime-mapping>
<extension>webm</extension>
<mime-type>video/webm</mime-type>
</mime-mapping>
<error-page>
<exception-type>java.lang.Throwable</exception-type>
<location>/oops</location>
</error-page>
<session-config>
<cookie-config>
<!-- See https://www.owasp.org/index.PHP/HttpOnly for the discussion of this topic in OWASP -->
<http-only>true</http-only>
</cookie-config>
<!-- Tracking mode is managed by WebAppMain.FORCE_SESSION_TRACKING_BY_COOKIE_PROP -->
</session-config>
</web-app># coding=utf-8
"""
作者:gaojs
功能:
新增功能:
日期:2022/6/2 17:12
"""
import xml.dom.minidom
dom = xml.dom.minidom.parse('web.xml')
root = dom.documentElement
bond_list = root.getElementsByTagName('filter-name')
print(bond_list[0].firstChild.data)运行结果:
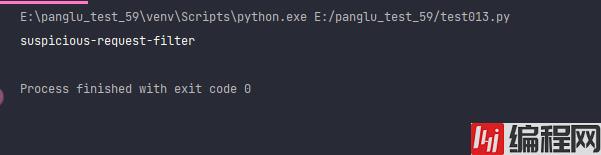
# coding=utf-8
"""
作者:gaojs
功能:
新增功能:
日期:2022/6/2 17:12
"""
import xml.dom.minidom
dom = xml.dom.minidom.parse('web.xml')
root = dom.documentElement
filter_list = root.getElementsByTagName('filter-name')
# print(filter_list[0].firstChild.data)
for bond in filter_list:
s = bond.firstChild.data
print(s)
with open('filter_result.txt', 'a') as fin:
fin.write(s + '\n')文件结果:

with open('web.xml', mode='r') as fin:
test = fin.read()
result = re.findall('<filter-name>(.*?)</filter-name>', test)
for key in result:
print(key)
with open('array/filter_result.txt', 'a') as f:
f.write(key + '\n')结果:

以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。
--结束END--
本文标题: python如何提取xml指定内容
本文链接: https://www.lsjlt.com/news/176567.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0