Python 官方文档:入门教程 => 点击学习
目录一、前言二、实现原理三、提取PPT中的图片1、打开压缩包2、解压文件四、提取PPT中的图片附:python提取PPT中的文字(包括图片中的文字)总结一、前言 今天要带大家实现的是
今天要带大家实现的是PPT图片的提取。在我们学习工作中,PPT的使用还是非常频繁的,但是自己做PPT是很麻烦的,所以就需要用到别人的模板或者素材,这个时候提取PPT图片就可以减少我们很多工作。
其实实现原理很简单,我们的pptx文件其实是一个压缩包。我们可以直接修改pptx文件的后缀,改成zip然后解压,比如下面这个:
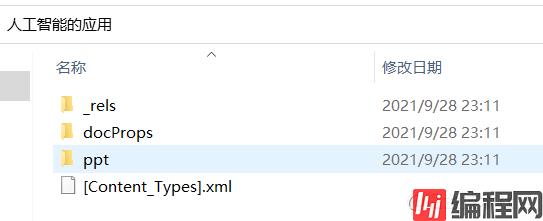
这是解压后的文件。我们可以在ppt目录下找到一个media目录,这个目录下就是我们要的图片的。这个目录包含了PPT的所有多媒体文件。
知道这点后,我们就可以选择用Python来解压出PPT中的media目录就可以提取出所有图片了。
在Python中提供了一个zipfile模块用于处理压缩包文件。我们来看看它的简单操作:
from zipfile import ZipFile
# 打开压缩文件
f = ZipFile("test.pptx")
# 查看压缩包所有文件
for file in f.namelist():
print(file)
# 关闭压缩包文件
f.close()
输出的部分结果如下:
[Content_Types].xml
_rels/.rels
ppt/presentation.xml
ppt/slides/_rels/slide2.xml.rels
ppt/slides/slide1.xml
ppt/slides/slide2.xml
ppt/slides/slide3.xml
可以看到我们打印出了压缩包的文件。
我们还可以通过下面的方式打开压缩包:
from zipfile import ZipFile
with ZipFile("test.pptx") as f:
for file in f.namelist():
print(file)
通过with语句,就可以不显示地调用close方法。下面我们看看解压操作:
from zipfile import ZipFile
with ZipFile("test.pptx") as f:
for file in f.namelist():
# 解压文件
f.extract(file, path="unzip")
解压文件的操作通过f.extract来实现,这里传入了两个参数,分别是压缩包文件,和解压路径,如果压缩包有密码还需要传入解压密码。
然后我们还需要判断一下,如果是媒体目录我们才解压。我们添加一点代码:
from zipfile import ZipFile
with ZipFile("test.pptx") as f:
for file in f.namelist():
# 如果是media目录下的文件就解压
if file.startswith("ppt/media/"):
f.extract(file, path="unzip")
这样我们就实现了PPT图片的提取。
我们把上面代码再完善一下:
import os
from zipfile import ZipFile
# 解压目录
unzip_path = "unzip"
# 如果解压目录不存在则创建
if not os.path.exists(unzip_path):
os.mkdir(unzip_path)
with ZipFile("test1/test.pptx") as f:
for file in f.namelist():
if file.startswith("ppt/media/"):
f.extract(file, path=unzip_path)
这里我们就是添加了一个解压目录的创建,这样我们执行的时候就不会因为目录不存在而报错了。
另外,其实我们手动解压然后提取PPT中的图片也是很方便的,也并不会比程序慢。
很多人都知道,Python可以操作excel,pdf·还有PPT,这篇文章就围绕Python提取PPT中的文字来写,包括提取PPT中的艺术字,图片中的文字。
因为实现环境是linux,所以无法用win32com来实现这个需求,使用extract库也可以提取PDF,PPT等文件中的文字,但这里不用extract来实现,用python-pptx,如果熟悉extract库一点的也知道,extract中也使用了python-pptx,实现过程也是调用了python-pptx。
presentation = pptx.Presentation(fp)
results = []
for slide in presentation.slides:
for shape in slide.shapes:
if shape.has_text_frame:
for paragraph in shape.text_frame.paragraphs:
part = []
for run in paragraph.runs:
part.append(run.text)
results.append(''.join(part))
elif isinstance(shape, Picture):
content = self.parsepic.request_api(shape.image.blob)
results.append(''.join(content))
results = [line for line in results if line.strip()]代码分析:
presentation = pptx.Presentation(fp)实例化ppt对象,只有实例化Presentation对象才能操作ppt,通过此对象可以访问其他类的接口。
通过presentation访问幻灯片presentation.slides,slides是由每一个幻灯片对象组成的列表。
通过幻灯片对象slide访问包含在此幻灯片上的形状对象shape,如文本框,表格,图片等
if shape.has_text_frame判断形状对象是否为文本对象
for paragraph in shape.text_frame.paragraphs:
part = []
for run in paragraph.runs:
part.append(run.text)
results.append(''.join(part))获取文本框的文本,文本框中也会出现多个段落内容
elif isinstance(shape, Picture):
content = self.parsepic.request_api(shape.image.blob)
results.append(''.join(content))判断是否为图片对象或者艺术字对象,这里是调用百度图片提取文字的接口来提取PPT中包含在图片中的文字。
def request_api(self, img_data):
url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic'
# 高进度版
# url = 'Https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic'
postdata = {
'language_type': 'CHN_ENG', # 中英文混合
'detect_direction': 'true',
'image': base64.b64encode(img_data)
}
headers = {
'Content-Type': 'application/x-www-fORM-urlencoded',
'User-Agent': random.choice(USER_AGENT['pc'])
}
r = requests.post(url, params={'access_token': self.get_token()}, data=postdata, headers=headers).JSON()
if r.get('error_code'):
raise Exception(r['error_msg'])
return [item['Words'] for item in r['words_result']]需要注册一个账号,并且开通图片提取文字的服务,获取APPKEY, APPSECRETKEY,从而获取到token,具体接口详情看百度开发者文档。
python-pptx官方文档:https://python-pptx.readthedocs.io/en/latest/api/slides.html#pptx.slide.Slides
到此这篇关于用Python提取PPT中的图片的文章就介绍到这了,更多相关Python提取PPT的图片内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 一步步教你用Python提取PPT中的图片
本文链接: https://www.lsjlt.com/news/178000.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0