



python爬虫查询车站信息
目录:
1.找到要查询的url
2.对信息进行分析
3.对信息进行处理
python爬虫查询全拼相同的车站
目录:
1.找到要查询的url
2.对信息进行分析
3.对信息进行处理
1.找到车站信息的url

2.分析车站信息,发现每个车站信息以"@"分隔

车站信息查询
#车站信息查询
import requests
#1.获得url(存取车站信息的url)并读取,根据获得信息的特点去掉无用的信息并转换存储到列表中
url="https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9090"
txt=requests.get(url).text
#print(txt)
inf=txt[:-2].split("@")[1:] #得到的是存储所有车站信息的列表
#print(inf)
#2.通过循环把列表在进行分割转换成新的列表,取其中一项(车站顺序编号)当做字典的key,其余当作值,存储到新的字典中
stations={}
for record in inf:
rlist=record.split("|")
stations[int(rlist[-1])]={"cname":rlist[1],"id":rlist[2],"qp":rlist[3],"jx":rlist[4]}
#print(stations[0])
#print(stations.get(2848))
#print(stations.values())
#3.判断查询条件是否存在,存在如果唯一则打印并跳出循环,不唯一则显示查询的所有的结果,提供选择,根据选择的信息打印出结果然后跳出循环,不存在则打印提示信息,重新输出
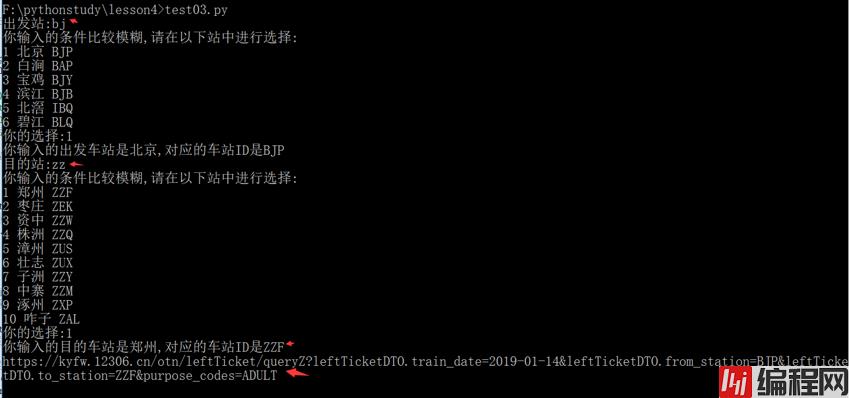
while True:
s1=input("出发站:")
flag=0
result=[]
for station in stations.values():
if s1 in station.values():
#print(station)
result.append(station)
flag=1
if flag:
break
else:
print("没有这个车站!")
print("请重新输入!")
if len(result)==1:
resultId=result[0]["id"]
print("你输入的出发车站是%s,对应的车站ID是%s"%(result[0]["cname"],resultId))
else:
print("你输入的条件比较模糊,请在以下站中进行选择:")
for i in range(len(result)):
print(i+1,result[i]["cname"],result[i]["id"])
sel=int(input("你的选择:"))-1
resultId=result[sel]["id"]
print("你输入的出发车站是%s,对应的车站ID是%s"%(result[sel]["cname"],resultId))
while True:
s2=input("目的站:")
flag2=0
result2=[]
for station in stations.values():
if s2 in station.values():
#print(station)
result2.append(station)
flag2=1
if flag2:
break
else:
print("没有这个车站!")
print("请重新输入!")
if len(result2)==1:
result2Id=result2[0]["id"]
print("你输入的目的车站是%s,对应的车站ID是%s"%(result2[0]["cname"],result2Id))
else:
print("你输入的条件比较模糊,请在以下站中进行选择:")
for i in range(len(result2)):
print(i+1,result2[i]["cname"],result2[i]["id"])
sel2=int(input("你的选择:"))-1
result2Id=result2[sel2]["id"]
print("你输入的目的车站是%s,对应的车站ID是%s"%(result2[sel]["cname"],result2Id))
#生成一条带查询的url(url在浏览器开发者模式查找)
qurl="Https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-14&leftTicketDTO.from_station=%s&leftTicketDTO.to_station=%s&purpose_codes=ADULT"
print(qurl %(resultId,result2Id))运行效果如下:
2.查询出所有全拼相同的所有车站名称 #python 查询出所有全拼相同的所有车站名称
import requests
url="https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9090"
txt=requests.get(url).text
inf=txt[:-2].split("@")[1:]
stations={}
for record in inf:
rlist=record.split("|")
stations[int(rlist[-1])]={"cname":rlist[1],"id":rlist[2],"qp":rlist[3],"jx":rlist[4]}
pyin=[]
for station in stations.values(): #把获得的信息所有的"qp"所对应的值全部放到列表中(pyin)
pyin.append(station["qp"])
npy=list(set(pyin)) #利用集合的去重特性对列表进行去掉重复项
npy.sort() #对列表进行排序
c={}
for station in stations.values(): #分别把所有的全拼当作键,值加入到新的字典当中
c[station["qp"]]=c.get(station["qp"],0)+1
#print(c)
c2=[]
for k,v in c.items(): #判断字典的值是否大于1,大于则说明存在全拼相同的车站名
if v>1:
c2.append(k) #把满足条件的所有的全拼加入到新的列表中
c2.sort()
#print(c2)
for p in c2: #遍历列表,打印出符合条件的车站
print(p,end=":")
for station in stations.values():
if p==station["qp"]:
print(station["cname"])运行效果如下:



0