



python爬虫之12306网站--火车票信息查询
思路:
1.火车票信息查询是基于车站信息查询,先完成车站信息查询,然后根据车站信息查询生成的url地址去查询当前已知出发站和目的站的所有车次车票信息
2.JSON文件存储当前从出发站到目的站的所有车次的详细信息
3.对json文件进行分析
4.分类查询车票(高铁、火车)
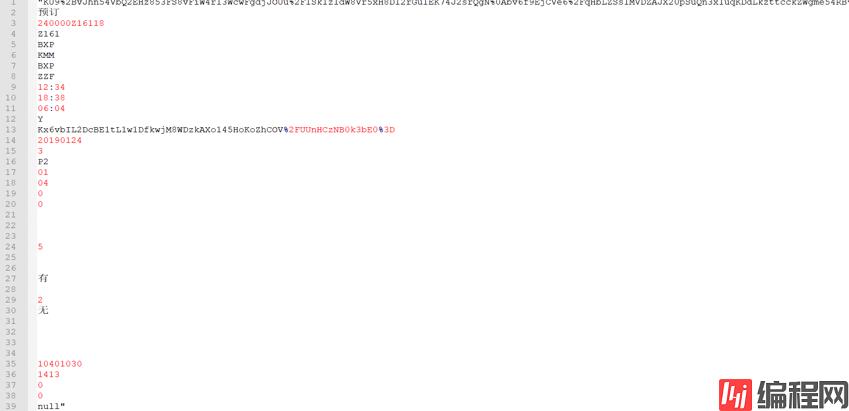
1.json文件:在12306页面选择"车票"》"单程",打开"开发人员工具",然后输入出发地、目的地

对json文件进行分析,发现是嵌套的字典,车次的所有详细信息存储在"result"中

选择一条数据然后对其进行分析,找到自己想要的数据(例如车次在的位置,出发站、到达站、座位的种类等等)
这里用的是notepad++软件,把"|"替换为"\r",这样就方便自己找到想要的数据对应的位置
代码如下:
#python 火车票信息的查询
import requests
url1="https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9090"
txt=requests.get(url1).text
inf=txt[:-2].split("@")[1:]
#print(inf)
stations={}
for record in inf:
rlist=record.split("|")
stations[rlist[2]]={"cn":rlist[1],"qp":rlist[3],"jp":rlist[4]} #把车站编码当作key
#print(stations)
def getcode(t):
while True:
s1=input("%s站:"%t)
r1=[]
for id,station in stations.items():
if s1 in station.values():
r1.append((id,station))
if r1:
break
print("没有这个车站。")
print("请重新输入。")
if len(r1)==1:
sid=r1[0][0]
else:
print("你需要在以下车站里选择:")
for i in range(len(r1)):
print(i+1,r1[i][1]["cn"])
sel=int(input("你的选择是:"))-1
sid=r1[sel][0]
return sid
fromstation=getcode("出发")
tostation=getcode("到达")
chufatime=input("出发日期(格式2019-01-01):").strip()
qurl="Https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT".fORMat(chufatime,fromstation,tostation)
print(qurl)
print("你输入的查询条件是:出发站=%s,到达站=%s"%(stations[fromstation]["cn"],stations[tostation]["cn"]))
ainf=requests.get(qurl).json()["data"]["result"] #json文件存储当前从出发站到目的站的所有车次的详细信息
#print(ainf,type(ainf))
result=[]
for i in ainf:
list=i.split("|")
checi=list[3]
chufa=stations[list[6]]["cn"]
mudi=stations[list[7]]["cn"]
ftime=list[8]
dtime=list[9]
sw=list[32]
yd=list[31]
rw=list[23]
yw=list[26]
wuzuo=list[28]
ed=list[30]
yz=list[29]
result.append((checi,chufa,mudi,ftime,dtime,sw,yd,ed,yz,yw,rw,wuzuo))
#print(result)
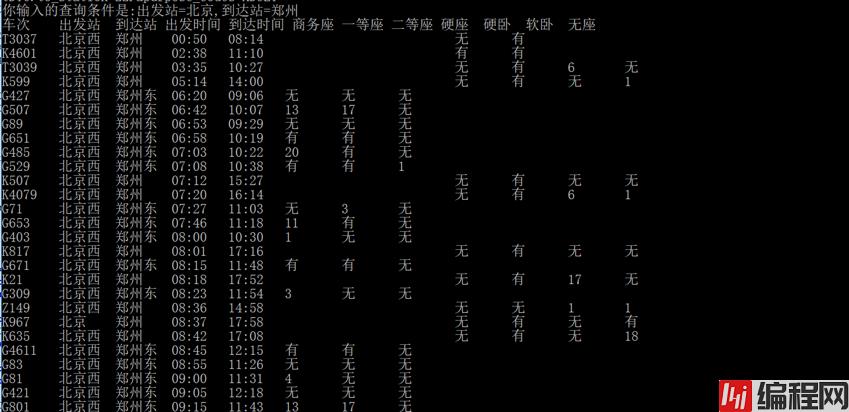
print("车次\t出发站\t到达站 出发时间 到达时间 商务座 一等座 二等座 硬座 硬卧 软卧 无座 ")
for i in result:
for n in range(len(i)):
print(i[n],end="\t")
print()
运行效果如下:

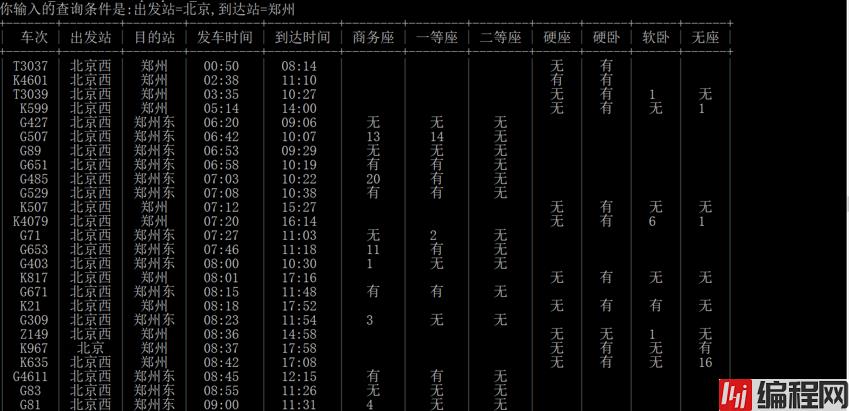
上面显示的太不友好了,这里用prettytable库(需要安装)
from prettytable import PrettyTable
............
............
table=PrettyTable(["车次","出发站","目的站","发车时间","到达时间","商务座","一等座","二等座","硬座","硬卧","软卧","无座"])
for i in result:
table.add_row([i[0],i[1],i[2],i[3],i[4],i[5],i[6],i[7],i[8],i[9],i[10],i[11]])
print(table)运行效果如下:
4.分类查询车票
import requests
from prettytable import PrettyTable
url1="https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9090"
txt=requests.get(url1).text
inf=txt[:-2].split("@")[1:]
#print(inf)
stations={}
for record in inf:
rlist=record.split("|")
stations[rlist[2]]={"cn":rlist[1],"qp":rlist[3],"jp":rlist[4]} #把车站编码当作key
#print(stations)
def getcode(t):
while True:
s1=input("%s站:"%t)
r1=[]
for id,station in stations.items():
if s1 in station.values():
r1.append((id,station))
if r1:
break
print("没有这个车站。")
print("请重新输入。")
if len(r1)==1:
sid=r1[0][0]
else:
print("你需要在以下车站里选择:")
for i in range(len(r1)):
print(i+1,r1[i][1]["cn"])
sel=int(input("你的选择是:"))-1
sid=r1[sel][0]
return sid
fromstation=getcode("出发")
tostation=getcode("到达")
chufatime=input("出发日期(格式2019-01-01):").strip()
qurl="https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT".format(chufatime,fromstation,tostation)
print(qurl)
print("你输入的查询条件是:出发站=%s,到达站=%s"%(stations[fromstation]["cn"],stations[tostation]["cn"]))
ainf=requests.get(qurl).json()["data"]["result"] #json文件存储当前从出发站到目的站的所有车次的详细信息
#print(ainf,type(ainf))
result=[]
gaotie=[]
huoche=[]
for i in ainf:
list=i.split("|")
checi=list[3]
chufa=stations[list[6]]["cn"]
mudi=stations[list[7]]["cn"]
ftime=list[8]
dtime=list[9]
sw=list[32]
yd=list[31]
rw=list[23]
yw=list[26]
wuzuo=list[28]
ed=list[30]
yz=list[29]
result.append((checi,chufa,mudi,ftime,dtime,sw,yd,ed,yz,yw,rw,wuzuo))
if checi[0] in ["G","D"]:
gaotie.append([checi,chufa,mudi,ftime,dtime,sw,yd,ed])
else:
huoche.append([checi,chufa,mudi,ftime,dtime,yz,yw,rw,wuzuo])
#print(result)
while True:
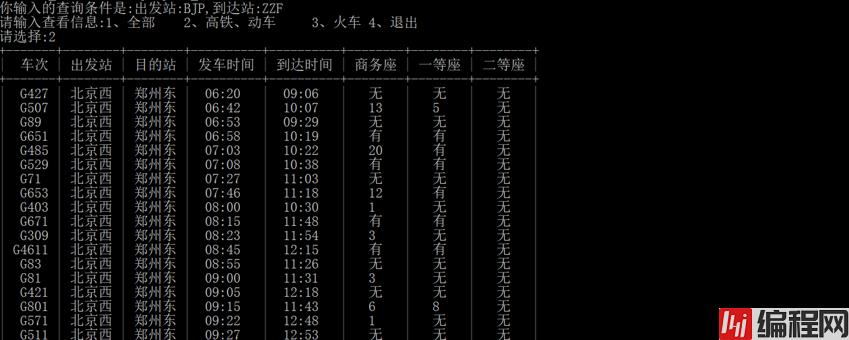
print("请输入查看信息:1、全部 2、高铁、动车 3、火车 4、退出")
show=int(input("请选择:"))
if show==1:
table=PrettyTable(["车次","出发站","目的站","发车时间","到达时间","商务座","一等座","二等座","硬座","硬卧","软卧","无座"])
for i in result:
table.add_row([i[0],i[1],i[2],i[3],i[4],i[5],i[6],i[7],i[8],i[9],i[10],i[11]])
print(table)
elif show==2:
table=PrettyTable(["车次","出发站","目的站","发车时间","到达时间","商务座","一等座","二等座"])
for i in gaotie:
table.add_row([i[0],i[1],i[2],i[3],i[4],i[5],i[6],i[7]])
print(table)
elif show==3:
table=PrettyTable(["车次","出发站","目的站","发车时间","到达时间","硬座","硬卧","软卧","无座"])
for i in huoche:
table.add_row([i[0],i[1],i[2],i[3],i[4],i[5],i[6],i[7],i[8]])
print(table)
elif show==4:
print("查询结束!")
break
else:
print("输入错误请重新输入!")运行效果如下:
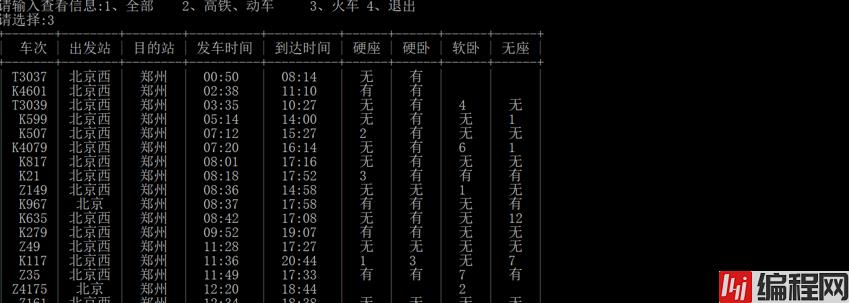


0