Python 官方文档:入门教程 => 点击学习
本节我们利用 Requests 和正则表达式来抓取猫眼电影 TOP100 的相关内容,Requests 相较于 Urllib 使用更加方便,而目前我们还没有系统学习 html 解析库,所以可能对 HTML 的解析库不是很了解,所以本节我们选
本节我们利用 Requests 和正则表达式来抓取猫眼电影 TOP100 的相关内容,Requests 相较于 Urllib 使用更加方便,而目前我们还没有系统学习 html 解析库,所以可能对 HTML 的解析库不是很了解,所以本节我们选用正则表达式来作为解析工具。
本节我们要提取出猫眼电影 TOP100 榜的电影名称、时间、评分、图片等信息,提取的站点 URL 为:http://maoyan.com/board/4,提取的结果我们以文件形式保存下来。
在本节开始之前请确保已经正确安装好了 Requests 库,如果没有安装可以参考第一章的安装说明。
本节我们需要抓取的目标站点为:http://maoyan.com/board/4,打开之后便可以查看到榜单的信息,如图 3-11 所示:
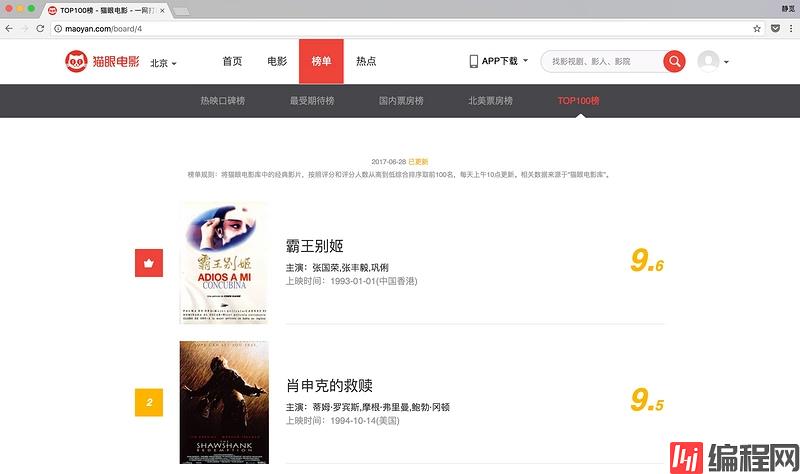
图 3-11 榜单信息
排名第一的电影是霸王别姬,页面中显示的有效信息有影片名称、主演、上映时间、上映地区、评分、图片等信息。
网页下滑到最下方可以发现有分页的列表,我们点击一下第二页观察一下页面的URL和内容发生了怎样的变化,如图 3-12 所示:
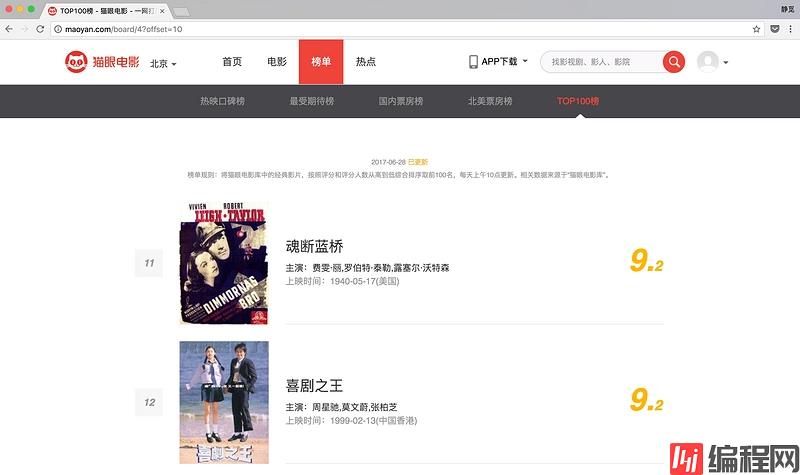
图 3-12 页面 URL 变化
可以发现页面的 URL 变成了:http://maoyan.com/board/4?off...,相比之前的URL多了一个参数,那就是 offset=10,而目前显示的结果是排行 11-20 名的电影,初步推断这是一个偏移量的参数,我们再点击下一页,发现页面的 URL 变成了:http://maoyan.com/board/4?off...,参数 offset 变成了 20,而显示的结果是排行 21-30 的电影。
由此我们可以总结出规律,offset 代表了一个偏移量值,如果偏移量为 n,则显示的电影序号就是 n+1 到 n+10,每页显示 10 个。所以我们如果想获取 TOP100 电影,只需要分开请求 10 次,而 10 次的 offset 参数设置为 0,10,20,...,90 即可,这样我们获取不同的页面结果之后再用正则表达式提取出相关信息就可以得到 TOP100 的所有电影信息了。
接下来我们用代码实现这个过程,首先抓取第一页的内容,我们实现一个 get_one_page() 方法,传入 url 参数,然后将抓取的页面结果返回,然后再实现一个 main() 方法调用一下,初步代码实现如下:
import requests
def get_one_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
def main():
url = '[Http://maoyan.com/board/4](http://maoyan.com/board/4)'
html = get_one_page(url)
print(html)
main()
python资源分享qun 784758214 ,内有安装包,pdf,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎这样运行之后我们就可以成功获取首页的源代码了,获取源代码之后我们就需要对页面进行解析,提取出我们想要的信息。
接下来我们回到网页看一下页面的真实源码,在开发者工具中 Network 监听,然后查看一下源代码,如图 3-13 所示:

图 3-13 源代码
注意这里不要在 Elements 选项卡直接查看源码,此处的源码可能经过 javascript 的操作而和原始请求的不同,我们需要从Network选项卡部分查看原始请求得到的源码。
查看其中的一个条目的源代码如图 3-14 所示:

图 3-14 源代码
可以看到一部电影信息对应的源代码是一个 dd 节点,我们用正则表达式来提取这里面的一些电影信息,首先我们需要提取它的排名信息,而它的排名信息是在 class 为 board-index 的 i 节点内,所以所以这里利用非贪婪匹配来提取 i 节点内的信息,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>随后我们需要提取电影的图片,可以看到在后面有个 a 节点,其内部有两个 img 节点,经过检查后发现第二个 img 节点的 data-src属性是图片的链接,在这里我们提取第二个 img 节点的 data-src属性,所以正则可以改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"再往后我们需要提取电影的名称,它在后面的 p 节点内,class 为 name,所以我们可以用 name 做一个标志位,然后进一步提取到其内 a 节点的正文内容,正则改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>随后如果需要再提取主演、发布时间、评分等内容的话都是同样的原理,最后正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>
这样我们一个正则表达式可以匹配一个电影的结果,里面匹配了 7 个信息,接下来我们通过调用 findall() 方法提取出所有的内容,实现一个 parse_one_page() 方法如下:
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',
re.S)
items = re.findall(pattern, html)
print(items)这样我们就可以成功将一页的 10 个电影信息都提取出来了,是一个列表形式,输出结果如下:
[('1', 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', '霸王别姬', '\n 主演:张国荣,张丰毅,巩俐\n ', '上映时间:1993-01-01(中国香港)', '9.', '6'), ('2', 'http://p0.meituan.net/movie/__40191813__4767047.jpg@160w_220h_1e_1c', '肖申克的救赎', '\n 主演:蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿\n ', '上映时间:1994-10-14(美国)', '9.', '5'), ('3', 'http://p0.meituan.net/movie/fc9d78dd2ce84d20e53b6d1ae2eea4fb1515304.jpg@160w_220h_1e_1c', '这个杀手不太冷', '\n 主演:让·雷诺,加里·奥德曼,娜塔莉·波特曼\n ', '上映时间:1994-09-14(法国)', '9.', '5'), ('4', 'http://p0.meituan.net/movie/23/6009725.jpg@160w_220h_1e_1c', '罗马假日', '\n 主演:格利高利·派克,奥黛丽·赫本,埃迪·艾伯特\n ', '上映时间:1953-09-02(美国)', '9.', '1'), ('5', 'http://p0.meituan.net/movie/53/1541925.jpg@160w_220h_1e_1c', '阿甘正传', '\n 主演:汤姆·汉克斯,罗宾·怀特,加里·西尼斯\n ', '上映时间:1994-07-06(美国)', '9.', '4'), ('6', 'http://p0.meituan.net/movie/11/324629.jpg@160w_220h_1e_1c', '泰坦尼克号', '\n 主演:莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩\n ', '上映时间:1998-04-03', '9.', '5'), ('7', 'http://p0.meituan.net/movie/99/678407.jpg@160w_220h_1e_1c', '龙猫', '\n 主演:日高法子,坂本千夏,糸井重里\n ', '上映时间:1988-04-16(日本)', '9.', '2'), ('8', 'http://p0.meituan.net/movie/92/8212889.jpg@160w_220h_1e_1c', '教父', '\n 主演:马龙·白兰度,阿尔·帕西诺,詹姆斯·凯恩\n ', '上映时间:1972-03-24(美国)', '9.', '3'), ('9', 'http://p0.meituan.net/movie/62/109878.jpg@160w_220h_1e_1c', '唐伯虎点秋香', '\n 主演:周星驰,巩俐,郑佩佩\n ', '上映时间:1993-07-01(中国香港)', '9.', '2'), ('10', 'http://p0.meituan.net/movie/9bf7d7b81001a9cf8adbac5a7cf7d766132425.jpg@160w_220h_1e_1c', '千与千寻', '\n 主演:柊瑠美,入野自由,夏木真理\n ', '上映时间:2001-07-20(日本)', '9.', '3')]
但这样还不够,数据比较杂乱,我们再将匹配结果处理一下,遍历提取结果并生成字典,方法改写如下:
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',
re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:] if len(item[3]) > 3 else '',
'time': item[4].strip()[5:] if len(item[4]) > 5 else '',
'score': item[5].strip() + item[6].strip()
}这样我们就可以成功提取出电影的排名、图片、标题、演员、时间、评分内容了,并把它赋值为一个个的字典,形成结构化数据,运行结果如下:
{'image': 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'actor': '张国荣,张丰毅,巩俐', 'score': '9.6', 'index': '1', 'title': '霸王别姬', 'time': '1993-01-01(中国香港)'}
{'image': 'http://p0.meituan.net/movie/__40191813__4767047.jpg@160w_220h_1e_1c', 'actor': '蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿', 'score': '9.5', 'index': '2', 'title': '肖申克的救赎', 'time': '1994-10-14(美国)'}
{'image': 'http://p0.meituan.net/movie/fc9d78dd2ce84d20e53b6d1ae2eea4fb1515304.jpg@160w_220h_1e_1c', 'actor': '让·雷诺,加里·奥德曼,娜塔莉·波特曼', 'score': '9.5', 'index': '3', 'title': '这个杀手不太冷', 'time': '1994-09-14(法国)'}
{'image': 'http://p0.meituan.net/movie/23/6009725.jpg@160w_220h_1e_1c', 'actor': '格利高利·派克,奥黛丽·赫本,埃迪·艾伯特', 'score': '9.1', 'index': '4', 'title': '罗马假日', 'time': '1953-09-02(美国)'}
{'image': 'http://p0.meituan.net/movie/53/1541925.jpg@160w_220h_1e_1c', 'actor': '汤姆·汉克斯,罗宾·怀特,加里·西尼斯', 'score': '9.4', 'index': '5', 'title': '阿甘正传', 'time': '1994-07-06(美国)'}
{'image': 'http://p0.meituan.net/movie/11/324629.jpg@160w_220h_1e_1c', 'actor': '莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩', 'score': '9.5', 'index': '6', 'title': '泰坦尼克号', 'time': '1998-04-03'}
{'image': 'http://p0.meituan.net/movie/99/678407.jpg@160w_220h_1e_1c', 'actor': '日高法子,坂本千夏,糸井重里', 'score': '9.2', 'index': '7', 'title': '龙猫', 'time': '1988-04-16(日本)'}
{'image': 'http://p0.meituan.net/movie/92/8212889.jpg@160w_220h_1e_1c', 'actor': '马龙·白兰度,阿尔·帕西诺,詹姆斯·凯恩', 'score': '9.3', 'index': '8', 'title': '教父', 'time': '1972-03-24(美国)'}
{'image': 'http://p0.meituan.net/movie/62/109878.jpg@160w_220h_1e_1c', 'actor': '周星驰,巩俐,郑佩佩', 'score': '9.2', 'index': '9', 'title': '唐伯虎点秋香', 'time': '1993-07-01(中国香港)'}
{'image': 'http://p0.meituan.net/movie/9bf7d7b81001a9cf8adbac5a7cf7d766132425.jpg@160w_220h_1e_1c', 'actor': '柊瑠美,入野自由,夏木真理', 'score': '9.3', 'index': '10', 'title': '千与千寻', 'time': '2001-07-20(日本)'}
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎到此为止我们就成功提取了单页的电影信息。
随后我们将提取的结果写入文件,在这里直接写入到一个文本文件中,通过 JSON 库的 dumps() 方法实现字典的序列化,并指定 ensure_ascii 参数为 False,这样可以保证输出的结果是中文形式而不是 Unicode 编码,代码实现如下:
def write_to_json(content):
with open('result.txt', 'a') as f:
print(type(json.dumps(content)))
f.write(json.dumps(content, ensure_ascii=False,)+'\n')通过调用 write_to_json() 方法即可实现将字典写入到文本文件的过程,此处的 content 参数就是一部电影的提取结果,是一个字典。
最后实现一个 main() 方法负责调用以上实现的方法,将单页的电影结果写入到文件,实现如下:
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):
write_to_json(item)到此为止我们就完成了单页电影的提取,也就是首页的 10 部电影就可以成功提取并保存到文本文件中了。
但我们需要抓取的是 TOP100 的电影,所以我们还需要遍历一下给这个链接传入一个 offset 参数,实现其他 90 部电影的爬取,添加如下调用即可:
if __name__ == '__main__':
for i in range(10):
main(offset=i * 10)这里还需要将 main() 方法修改一下,接收一个 offset 值作为偏移量,然后构造 URL 进行爬取,实现如下:
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)到此为止,我们的猫眼电影 TOP100 的爬虫就全部完成了,再稍微整理一下,完整的代码如下:
import json
import requests
from requests.exceptions import RequestException
import re
import time
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)现在猫眼多了反爬虫,如果速度过快则会无响应,所以这里又增加了一个延时等待。
最后我们运行一下代码,类似的输出结果如下:
{'index': '1', 'image': 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'title': '霸王别姬', 'actor': '张国荣,张丰毅,巩俐', 'time': '1993-01-01(中国香港)', 'score': '9.6'}
{'index': '2', 'image': 'http://p0.meituan.net/movie/__40191813__4767047.jpg@160w_220h_1e_1c', 'title': '肖申克的救赎', 'actor': '蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿', 'time': '1994-10-14(美国)', 'score': '9.5'}
...
{'index': '98', 'image': 'http://p0.meituan.net/movie/76/7073389.jpg@160w_220h_1e_1c', 'title': '东京物语', 'actor': '笠智众,原节子,杉村春子', 'time': '1953-11-03(日本)', 'score': '9.1'}
{'index': '99', 'image': 'http://p0.meituan.net/movie/52/3420293.jpg@160w_220h_1e_1c', 'title': '我爱你', 'actor': '宋在河,李彩恩,吉海延', 'time': '2011-02-17(韩国)', 'score': '9.0'}
{'index': '100', 'image': 'http://p1.meituan.net/movie/__44335138__8470779.jpg@160w_220h_1e_1c', 'title': '迁徙的鸟', 'actor': '雅克·贝汉,菲利普·拉波洛,Philippe Labro', 'time': '2001-12-12(法国)', 'score': '9.1'}
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎中间的部分输出结果已省略,可以看到这样就成功把 TOP100 的电影信息爬取下来了。
这时我们再看下文本文件,结果如图 3-15 所示:

图 3-15 运行结果
可以看到电影信息也已全部保存到了文本文件中,大功告成!
本节我们通过爬取猫眼 TOP100 的电影信息练习了 Requests 和正则表达式的用法,这是最基础的实例,希望大家可以通过这个实例对爬虫的实现有一个最基本的思路,也对这两个库的用法有更深一步的体会。
--结束END--
本文标题: Python3网络爬虫实战-27、Req
本文链接: https://www.lsjlt.com/news/191558.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0