Python 官方文档:入门教程 => 点击学习
MitmProxy 是一个支持 Http 和 https 的抓包程序,类似 Fiddler、Charles 的功能,只不过它是一个控制台的形式操作。同时 MitmProxy 还有两个关联组件,一个是 MitmDump,它是 MitmProx
MitmProxy 是一个支持 Http 和 https 的抓包程序,类似 Fiddler、Charles 的功能,只不过它是一个控制台的形式操作。
同时 MitmProxy 还有两个关联组件,一个是 MitmDump,它是 MitmProxy 的命令行接口,利用它我们可以对接 python 脚本,用 Python 实现监听后的处理。另一个是 MitmWEB,它是一个 Web 程序,通过它我们可以清楚地观察到 MitmProxy 捕获的请求。
本节我们来了解一下 MitmProxy、MitmDump、MitmWeb 的安装方式。
最简单的安装方式还是使用 Pip,直接执行如下命令即可安装:
pip3 install mitmproxy这是最简单和通用的安装方式,执行完毕之后即可完成 MitmProxy的安装,另外还安装了MitmDump、MitmWeb 两个组件,如果不想用此种方式安装也可以选择下文列出的专门针对各个平台的安装方式或者 Docker 安装方式。
Mac 的安装非常简单,使用 HomeBrew 即可,命令如下:
brew install mitmproxy
Python资源分享qun 784758214 ,内有安装包,pdf,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎执行命令后即可完成 MitmProxy 的安装。
MitmProxy 也支持 Docker,其 Docker Hub 的地址为https://hub.docker.com/r/mitm...
Docker 下 MitmProxy 的安装命令为:
docker run --rm -it -p 8080:8080 mitmproxy/mitmproxy mitmdump这样就在 8080 端口上启动了 MitmProxy 和 MitmDump。
如果想要获取 CA 证书,可以选择挂载磁盘选项,命令如下:
docker run --rm -it -v ~/.mitmproxy:/home/mitmproxy/.mitmproxy -p 8080:8080 mitmproxy/mitmproxy mitmdump这样可以在 ~/.mitmproxy 目录找到 CA 证书。
另外还可以在 8081 端口上启动 MitmWeb,命令如下:
docker run --rm -it -p 8080:8080 -p 127.0.0.1:8081:8081mitmproxy/mitmproxy mitmweb
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎更多启动方式可以参考 Docker Hub 的安装说明。
对于 MitmProxy 来说,如果想要截获 HTTPS 请求,我们就需要设置证书,MitmProxy 在安装后会提供一套 CA 证书,只要客户端信任了 MitmProxy 提供的证书,我们就可以通过 MitmProxy 获取 HTTPS 请求的具体内容,否则 MitmProxy 是无法解析 HTTPS 请求的。
首先运行一下命令产生 CA 证书,启动 MitmDump 即可:
mitmdump
这样即可启动 MitmDump,接下来我们就可以在用户目录下的 .mitmproxy 目录里面找到 CA 证书,如图 1-61 所示:
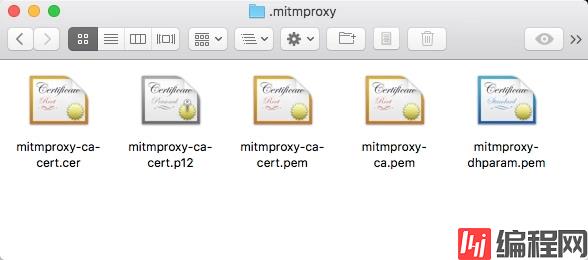
图 1-61 证书文件
证书一共五个,下面是对这五个证书的说明:

下面我们介绍一下 Mac、iOS、Android 平台下的证书配置过程。
Mac 下双击 mitmproxy-ca-cert.pem 即可弹出钥匙串管理页面,然后找到 mitmproxy 证书,点击打开其设置选项,选择始终信任即可,如图 1-66 所示:
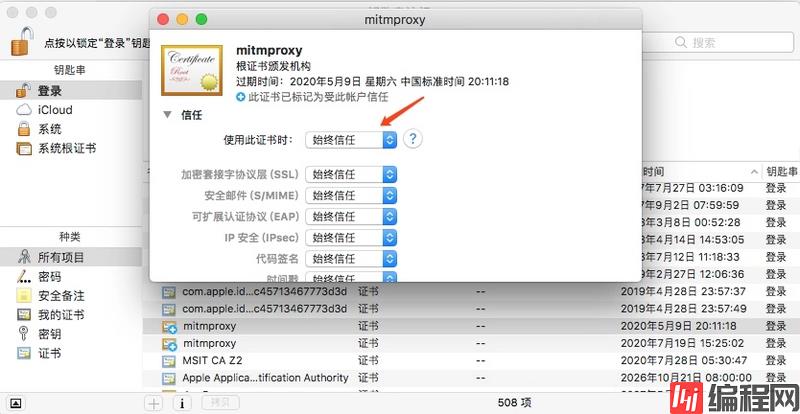
图 1-66 证书配置
这样就配置完成 Mac 下信任 CA 证书了。
将 mitmproxy-ca-cert.pem 文件发送到 iPhone 上,推荐使用邮件的方式发送,iPhone 上可以直接点击附件并识别安装,如图 1-67 所示:
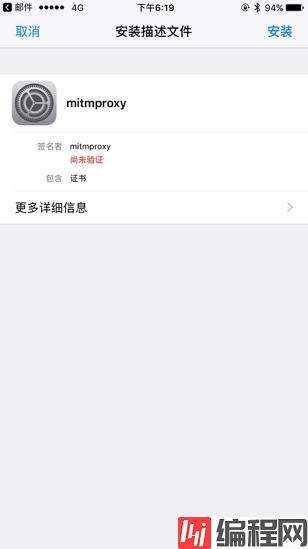
图 1-67 证书安装页面
点击之后会跳到安装描述文件的页面,点击右上角的安装按钮即可安装,此处会有警告提示,如图 1-68 所示:
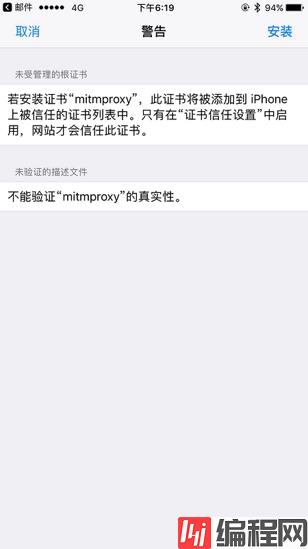
图 1-68 安装警告页面
继续点击右上角的安装即可,安装成功之后会有已安装的提示,如图 1-69 所示:

如果你的 iOS 版本是 10.3 以下的话,此处信任 CA 证书的流程就已经完成了。
如果你的 iOS 版本是 10.3 及以上,还需要在设置->通用->关于本机->证书信任设置将证书添加完全信任,如图 1-70 所示:
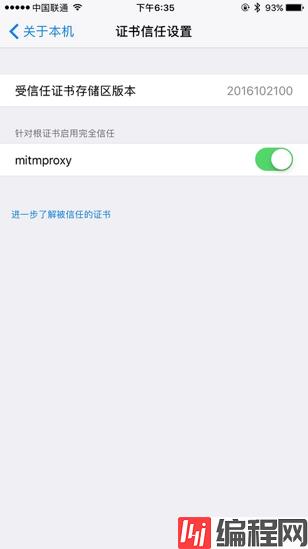
图 1-70 证书信任设置
在这里将 MitmProxy 的完全信任开关打开即可。
这样 iOS 上配置信任 CA 证书的流程就结束了。
Android
Android 手机同样需要将证书 mitmproxy-ca-cert.pem 文件发送到手机上,例如直接拷贝文件。Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
接下来点击证书便会出现一个提示窗口,如图 1-71 所示:

图 1-71 证书安装页面
这时输入证书的名称,然后点击确定即可完成安装。
本节我们了解了 MitmProxy、MitmDump、MitmWeb 的安装方式,在后文我们会用它来进行 APP 数据的抓取。
--结束END--
本文标题: Python3网络爬虫实战-7、APP爬
本文链接: https://www.lsjlt.com/news/192158.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0