Python 官方文档:入门教程 => 点击学习
目录爬取结果网站结构分析代码部分HttpClientUtil 类ComicSpider 类Chapter 和 ComicPage 类SinglePictureDownloader 类
我看大部分的爬虫入门教学都是爬取图片的,但是我测试了一下,那个网站现在加了一些反爬措施(如协议头部的 referer),并且很容易就会遇到429(太多请求)这个问题。可能是多线程速度太快,这也说明了控制爬取的合理速度的重要性。因为我一直有看漫画的习惯,所以就来测试一下爬取网站的漫画。(这个网站是提供试看功能,所以我就拿它来测试一下吧。)
网站地址(我喜欢的那部漫画地址):https://www.manhuaniu.com/manhua/5830/
程序运行效果
获取的文件目录信息
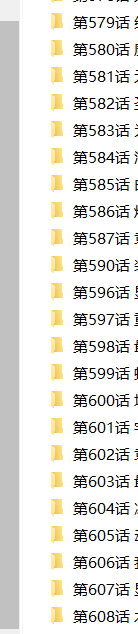
文件的总信息

注: 这里有一个小问题,获取的文件可能有的没有后缀名,但是可以以图片的方式打开观看,具体原因我也不知道,因为不影响,也就不去管它了。(或者自己使用代码,给文件重命名。)
这里以一部漫画为例,首先看上面的编号,那个编号表示漫画的目录页。这是很重要的,在这一页有漫画的目录。然后依次点击目录中的章节,可以看到每一章的漫画信息。


这里这个分页很奇怪,因为每一章节的页数不是一样的,但是它确实直接可以选择的,说明这个应该是提前加载或者异步加载的(我其实不会前端的知识,只是听说了一些。)后来通过查看源(我用眼睛发现的)发现确实是提前加载所有漫画页的链接。不是异步加载的。
这里我点击漫画图片获取图片的地址,然后再和自己发现的链接比对一下,就看出来了,然后拼接一下 url,就获取到所有的链接了。
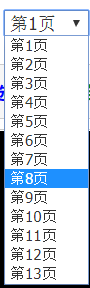
在相应的章节页中,使用浏览器的查看源,就可以发现这样一段脚本了。经过分析,脚本中的数组里面的信息,就是对应的每一页漫画的信息。

上面的截图是一个大概的结构信息,所以获取流程是: 目录页–>章节页–>漫画页
对于这里,获取到这段脚本作为字符串,然后以 “[” 和 “]” 获取字串,然后使用 fastJSON 将其转化为一个 List 集合。
// 获取的script 无法直接解析,必须先将 page url 取出来,
// 这里以 [ ] 为界限,分割字符串。
String pageUrls = script.data();
int start = pageUrls.indexOf("[");
int end = pageUrls.indexOf("]") + 1;
String urls = pageUrls.substring(start, end);
//json 转 集合,这个可以总结一下,不熟悉。
List<String> urlList = JSONArray.parseArray(urls, String.class);
这里强调一点:Element对象的 text 方法是获取可见信息,而 data 方法是获取不可见信息。脚本信息是不可直接看见的,所以我使用 data 方法获取它。所谓可见和不可见大概就是网页上可以显示和通过查看源可以获取的信息的意思。比如转义字符,通过t ext 获取就变成转义的字符了。
使用HttpClient连接池来管理连接,但是我没有使用多线程,因为我只有一个ip地址,万一被封了,很麻烦。当线程的时间还是可以 接受的,毕竟一部漫画,大概也就是十来分钟吧。(以600话为例)
package com.comic;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
public class HttpClientUtil {
private static final int TIME_OUT = 10 * 1000;
private static PoolingHttpClientConnectionManager pcm; //HttpClient 连接池管理类
private static RequestConfig requestConfig;
static {
requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(TIME_OUT)
.setConnectTimeout(TIME_OUT)
.setSocketTimeout(TIME_OUT).build();
pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(50);
pcm.setDefaultMaxPerRoute(10); //这里可能用不到这个东西。
}
public static CloseableHttpClient getHttpClient() {
return HttpClients.custom()
.setConnectionManager(pcm)
.setDefaultRequestConfig(requestConfig)
.build();
}
}
最重要的一个类,用来解析html页面获取链接数据。 注意:这里的 DIR_PATH 是硬编码路径,所以你想要测试,还请自己创建相关目录。
package com.comic;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.alibaba.fastjson.JSONArray;
public class ComicSpider {
private static final String DIR_PATH = "D:/DBC/comic/";
private String url;
private String root;
private CloseableHttpClient httpClient;
public ComicSpider(String url, String root) {
this.url = url;
// 这里不做非空校验,或者使用下面这个。
// Objects.requireNonNull(root);
if (root.charAt(root.length()-1) == '/') {
root = root.substring(0, root.length()-1);
}
this.root = root;
this.httpClient = HttpClients.createDefault();
}
public void start() {
try {
String html = this.getHtml(url); //获取漫画主页数据
List<Chapter> chapterList = this.mapChapters(html); //解析数据,得到各话的地址
this.download(chapterList); //依次下载各话。
} catch (IOException e) {
e.printStackTrace();
}
}
private String getHtml(String url) throws ClientProtocolException, IOException {
HttpGet get = new HttpGet(url);
//下面这两句,是因为总是报一个 Invalid cookie header,然后我在网上找到的解决方法。(去掉的话,不影响使用)。
RequestConfig defaultConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD).build();
get.setConfig(defaultConfig);
//因为是初学,而且我这里只是请求一次数据即可,这里就简单设置一下 UA
get.setHeader("User-Agent", "Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36");
HttpEntity entity = null;
String html = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
html = EntityUtils.toString(entity, "UTF-8");
}
}
}
return html;
}
//获取章节名 链接地址
private List<Chapter> mapChapters(String html) {
Document doc = Jsoup.parse(html, "UTF-8");
Elements name_urls = doc.select("#chapter-list-1 > li > a");
return name_urls.stream()
.map(name_url->new Chapter(name_url.text(),
root+name_url.attr("href")))
.collect(Collectors.toList());
}
public void download(List<Chapter> chapterList) {
chapterList.forEach(chapter->{
//按照章节创建文件夹,每一个章节一个文件夹存放。
File dir = new File(DIR_PATH, chapter.getName());
if (!dir.exists()) {
if (!dir.mkdir()) {
try {
throw new FileNotFoundException("无法创建指定文件夹"+dir);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
//开始按照章节下载
try {
List<ComicPage> urlList = this.getPageUrl(chapter);
urlList.forEach(page->{
SinglePictureDownloader downloader = new SinglePictureDownloader(page, dir.getAbsolutePath());
downloader.download();
});
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
//获取每一个页漫画的位置
private List<ComicPage> getPageUrl(Chapter chapter) throws IOException {
String html = this.getHtml(chapter.getUrl());
Document doc = Jsoup.parse(html, "UTF-8");
Element script = doc.getElementsByTag("script").get(2); //获取第三个脚本的数据
// 获取的script 无法直接解析,必须先将 page url 取出来,
// 这里以 [ ] 为界限,分割字符串。
String pageUrls = script.data();
int start = pageUrls.indexOf("[");
int end = pageUrls.indexOf("]") + 1;
String urls = pageUrls.substring(start, end);
//json 转 集合,这个可以总结一下,不熟悉。
List<String> urlList = JSONArray.parseArray(urls, String.class);
AtomicInteger index=new AtomicInteger(0); //我无法使用索引,这是别人推荐的方式
return urlList.stream() //注意这里拼接的不是 root 路径,而是一个新的路径
.map(url->new ComicPage(index.getAndIncrement(),"https://restp.dongqiniqin.com//"+url))
.collect(Collectors.toList());
}
}
注意: 这里我的思路是,所有的漫画都存放到 DIR_PATH 目录中。 然后每一章节是一个子目录(以章节名来命名),然后每一个章节的漫画放到一个目录中,但是这里会遇到一个问题。因为实际上漫画是一页一页观看的,所以漫画就有一个顺序的问题(毕竟一堆乱序漫画,看起来也很费劲,虽然我这里不是为了看漫画)。所以我就给每一个漫画页一个编号,按照上面脚本上的顺序,进行编号。但是由于我使用了Java8的 Lambda 表达式,所以我无法使用索引。(这涉及到另一个问题了)。 这里的解决办法是我看别人推荐的: 每次调用 index的 getAndIncrement 方法就可以增加 index 的值,非常方便。
AtomicInteger index=new AtomicInteger(0); //我无法使用索引,这是别人推荐的方式
return urlList.stream() //注意这里拼接的不是 root 路径,而是一个新的路径
.map(url->new ComicPage(index.getAndIncrement(),"https://restp.dongqiniqin.com//"+url))
.collect(Collectors.toList());
两个实体类,因为是面向对象嘛,我就设计了两个简单的实体类来封装一下信息,这样操作比较方便一点。
Chapter 类代表的是目录中的每一个章节的信息,章节的名字和章节的链接。 ComicPage 类代表的是每一个章节中的每一页漫画信息,每一页的编号和链接地址。
package com.comic;
public class Chapter {
private String name; //章节名
private String url; //对应章节的链接
public Chapter(String name, String url) {
this.name = name;
this.url = url;
}
public String getName() {
return name;
}
public String getUrl() {
return url;
}
@Override
public String toString() {
return "Chapter [name=" + name + ", url=" + url + "]";
}
}
package com.comic;
public class ComicPage {
private int number; //每一页的序号
private String url; //每一页的链接
public ComicPage(int number, String url) {
this.number = number;
this.url = url;
}
public int getNumber() {
return number;
}
public String getUrl() {
return url;
}
}
因为前几天使用多线程下载类爬取图片,发现速度太快了,ip 好像被封了,所以就又写了一个当线程的下载类。 它的逻辑很简单,主要是获取对应的漫画页链接,然后使用get请求,将它保存到对应的文件夹中。(它的功能大概和获取网络中的一张图片类似,既然你可以获取一张,那么成千上百也没有问题了。)
package com.comic;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import com.m3u8.HttpClientUtil;
public class SinglePictureDownloader {
private CloseableHttpClient httpClient;
private ComicPage page;
private String filePath;
private String[] headers = {
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .net CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
};
public SinglePictureDownloader(ComicPage page, String filePath) {
this.httpClient = HttpClientUtil.getHttpClient();
this.page = page;
this.filePath = filePath;
}
public void download() {
HttpGet get = new HttpGet(page.getUrl());
String url = page.getUrl();
//取文件的扩展名
String prefix = url.substring(url.lastIndexOf("."));
Random rand = new Random();
//设置请求头
get.setHeader("User-Agent", headers[rand.nextInt(headers.length)]);
HttpEntity entity = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
File picFile = new File(filePath, page.getNumber()+prefix);
try (OutputStream out = new BufferedOutputStream(new FileOutputStream(picFile))) {
entity.writeTo(out);
System.out.println("下载完毕:" + picFile.getAbsolutePath());
}
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭实体,关于 httpClient 的关闭资源,有点不太了解。
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
package com.comic;
public class Main {
public static void main(String[] args) {
String root = "https://www.manhuaniu.com/"; //网站根路径,用于拼接字符串
String url = "https://www.manhuaniu.com/manhua/5830/"; //第一张第一页的url
ComicSpider spider = new ComicSpider(url, root);
spider.start();
}
}
注:这里的代码是为了学习爬虫知识,而不是为了看漫画,如果你想看的话,还是推荐去作者推荐的地方付费观看,毕竟作者创作也是很辛苦的。
这个网站基本上没有反爬措施,所以处理起来也很方便(我也就是刚学,只知道一个 UA 和 referer,哈哈!)只要仔细分析,还是很容易爬取到相应信息的。最近看了一些人关于爬虫的介绍,使用什么语言并不是最重要的(不一定非要用 python,如果学Java的爬虫,必要的Java基础是必不可少的:IO流、多线程等,还是看你喜欢使用那个,像我就喜欢我最顺手的,而不是简单的。因为python意味着学习更多的 python 知识,但是我学习爬虫就是为了爬虫的知识而已),关键是对于各种反爬的处理,像我这样小爬虫,也就是一个小玩具而已。不过,千里之行始于足下,这是一个积累知识的过程。
到此这篇关于Java爬虫爬取漫画示例的文章就介绍到这了,更多相关Java爬虫爬取漫画内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Java爬虫爬取漫画示例
本文链接: https://www.lsjlt.com/news/211766.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0