本篇文章为大家展示了怎么解析spark的宽窄依赖和持久化,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。一.持久化官网1.官网位置截图2.cache 源码cache底层调用的是persisit&nbs
本篇文章为大家展示了怎么解析spark的宽窄依赖和持久化,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。

cache底层调用的是persisit ,默认参数是StorageLevel.MEMORY_ONLYcache 用完最好手动干掉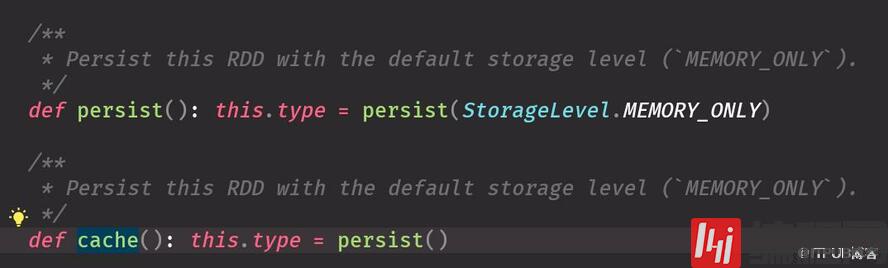

是否使用磁盘是否使用内存不管反序列化副本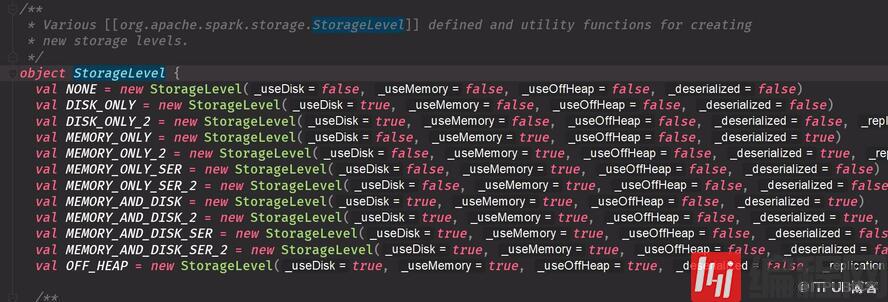

选择默认第一种MEMORY_ONLY 内存不够选怎序列化磁盘最好别选择不要用这个副本形式耗内存缓存选择:Spark’s storage levels are meant to provide different trade-offs (权衡)between memory usage and CPU efficiency.We recommend Going through the following process to select one: 选择方式 优先级从上到下 优先选择第一个MEMORY_ONLY ,内存实在不够就序列化 If your RDDs fit comfortably with the default storage level (MEMORY_ONLY), leave them that way 默认可以搞定就用默认的. This is the most CPU-efficient option, allowing operations on the RDDs to run as fast as possible. 不要选择java的序列化 If not, try using MEMORY_ONLY_SER and selecting a fast serialization library to make the objects much more space-efficient 空间很好, but still reasonably fast to access. (Java and Scala) Don’t spill to disk 不要放到磁盘 unless the functions that computed your datasets are expensive, or they filter a large amount of the data. Otherwise, recomputing a partition may be as fast as reading it from disk.宽依赖用shufer宽窄依赖容错程度不一样一个shuffer产生两个stage,两个产生三个stage等等Lineage 血缘关系 用于容错很多都是记录的textfile =》 xx => yy描述的是一个RDD如何从父RDD过来的RDD作用一个函数就是对RDD里面的分区作用一个函数丢失了根据父RDD重新算一下dependence 宽依赖:一个父RDD的partition至多被子RDD的某个partition使用一次 没shuffer pipline 丢一个就直接拿出来计算就可以 窄依赖:一个父RDD的parttiton会被子RDD的partitio使用多次 有shuffer 宽依赖挂掉了要从父RDD全部计算 有的时候解决数据倾斜需要shuffer 他们容错程度不一样的 有shuffer就会生成stage总结:老子被儿子用几次,多个孩子(宽)或单个孩子(窄)driver 就是main方法 中创建sparkcontextaction 产生job ,shuffer 产生stage ,stage 里是task上述内容就是怎么解析spark的宽窄依赖和持久化,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注编程网精选频道。
--结束END--
本文标题: 怎么解析spark的宽窄依赖和持久化
本文链接: https://www.lsjlt.com/news/230158.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作



0