这期内容当中小编将会给大家带来有关Pyspark如何读取parquet数据,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。可以跳过不符合条件的数据,只读取需要的数据,降低io数据量;压缩编码可以降低磁盘存储
这期内容当中小编将会给大家带来有关Pyspark如何读取parquet数据,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
可以跳过不符合条件的数据,只读取需要的数据,降低io数据量;压缩编码可以降低磁盘存储空间,使用更高效的压缩编码节约存储空间;只读取需要的列,支持向量运算,能够获取更好的扫描性能。parquet数据:列式存储结构,由Twitter和Cloudera合作开发,相比于行式存储,其特点是:
那么我们怎么在pyspark中读取和使用parquet数据呢?我以local模式,linux下的PyCharm执行作说明。
首先,导入库文件和配置环境:
import osfrom pyspark import SparkContext, SparkConffrom pyspark.sql.session import SparkSession os.environ["PYSPARK_python"]="/usr/bin/python3" #多个Python版本时需要指定 conf = SparkConf().setAppName('test_parquet')sc = SparkContext('local', 'test', conf=conf)spark = SparkSession(sc)然后,使用spark进行读取,得到DataFrame格式的数据:host:port 属于主机和端口号
parquetFile = r"hdfs://host:port/Felix_test/test_data.parquet"df = spark.read.parquet(parquetFile)而,DataFrame格式数据有一些方法可以使用,例如:
df.first() :显示第一条数据,Row格式
print(df.first())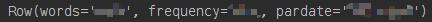
df.columns:列名
df.count():数据量,数据条数
df.topandas():从spark的DataFrame格式数据转到Pandas数据结构
df.show():直接显示表数据;其中df.show(n) 表示只显示前n行信息
type(df):显数据示格式

上述就是小编为大家分享的Pyspark如何读取parquet数据了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注编程网精选频道。
--结束END--
本文标题: Pyspark如何读取parquet数据
本文链接: https://www.lsjlt.com/news/235435.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0