Python 官方文档:入门教程 => 点击学习
文章目录 一、RDD#sortBy 方法1、RDD#sortBy 语法简介2、RDD#sortBy 传入的函数参数分析 二、代码示例 - RDD#sortBy 示例1、需求分析2、代码示例
RDD#sortBy 方法 用于 按照 指定的 键 对 RDD 中的元素进行排序 , 该方法 接受一个 函数 作为 参数 , 该函数从 RDD 中的每个元素提取 排序键 ;
根据 传入 sortBy 方法 的 函数参数 和 其它参数 , 将 RDD 中的元素按 升序 或 降序 进行排序 , 同时还可以指定 新的 RDD 对象的 分区数 ;
RDD#sortBy 语法 :
sortBy(f: (T) ⇒ U, ascending: Boolean, numPartitions: Int): RDD[T]RDD#sortBy 传入的函数参数 类型为 :
(T) ⇒ UT 是泛型 , 表示传入的参数类型可以是任意类型 ;
U 也是泛型 , 表示 函数 返回值 的类型 可以是任意类型 ;
T 类型的参数 和 U 类型的返回值 , 可以是相同的类型 , 也可以是不同的类型 ;
统计 文本文件 Word.txt 中出现的每个单词的个数 , 并且为每个单词出现的次数进行排序 ;
Tom JerryTom Jerry TomJack Jerry Jack Tom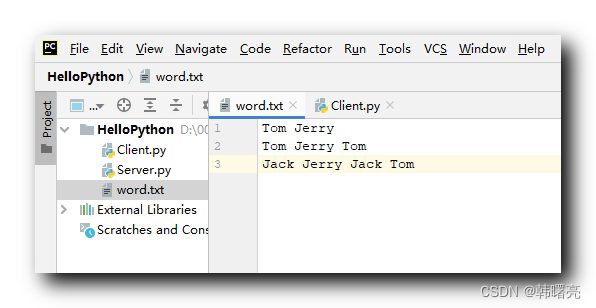
读取文件中的内容 , 统计文件中单词的个数并排序 ;
思路 :
对 RDD 数据进行排序的核心代码如下 :
# 对 rdd4 中的数据进行排序rdd5 = rdd4.sortBy(lambda element: element[1], ascending=True, numPartitions=1)要排序的数据如下 :
[('Tom', 4), ('Jack', 2), ('Jerry', 3)]按照上述二元元素的 第二个 元素 进行排序 , 对应的 lambda 表达式为 :
lambda element: element[1]ascending=True 表示升序排序 ,
numPartitions=1 表示分区个数为 1 ;
排序后的结果为 :
[('Jack', 2), ('Jerry', 3), ('Tom', 4)]代码示例 :
"""Pyspark 数据处理"""# 导入 PySpark 相关包from pyspark import SparkConf, SparkContext# 为 PySpark 配置 python 解释器import osos.environ['PYSPARK_Python'] = "D:/001_Develop/022_Python/python39/python.exe"# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务# setMaster("local[*]") 表示在单机模式下 本机运行# setAppName("hello_spark") 是给 Spark 程序起一个名字sparkConf = SparkConf() \ .setMaster("local[*]") \ .setAppName("hello_spark")# 创建 PySpark 执行环境 入口对象sparkContext = SparkContext(conf=sparkConf)# 打印 PySpark 版本号print("PySpark 版本号 : ", sparkContext.version)# 将 文件 转为 RDD 对象rdd = sparkContext.textFile("word.txt")print("查看文件内容 : ", rdd.collect())# 通过 flatMap 展平文件, 先按照 空格 切割每行数据为 字符串 列表# 然后展平数据解除嵌套rdd2 = rdd.flatMap(lambda element: element.split(" "))print("查看文件内容展平效果 : ", rdd2.collect())# 将 rdd 数据 的 列表中的元素 转为二元元组, 第二个元素设置为 1rdd3 = rdd2.map(lambda element: (element, 1))print("转为二元元组效果 : ", rdd3.collect())# 应用 reduceByKey 操作,# 将同一个 Key 下的 Value 相加, 也就是统计 键 Key 的个数rdd4 = rdd3.reduceByKey(lambda a, b: a + b)print("统计单词 : ", rdd4.collect())# 对 rdd4 中的数据进行排序rdd5 = rdd4.sortBy(lambda element: element[1], ascending=True, numPartitions=1)print("最终统计单词并排序 : ", rdd4.collect())# 停止 PySpark 程序sparkContext.stop()执行结果 :
D:\001_Develop\022_Python\Python39\python.exe D:/002_Project/011_Python/HelloPython/Client.py23/08/04 10:49:06 WARN shell: Did not find winutils.exe: java.io.FileNotFoundException: Could not locate hadoop executable: D:\001_Develop\052_Hadoop\hadoop-3.3.4\bin\winutils.exe -see https://wiki.apache.org/hadoop/windowsProblemsSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).PySpark 版本号 : 3.4.1查看文件内容 : ['Tom Jerry', 'Tom Jerry Tom', 'Jack Jerry Jack Tom']查看文件内容展平效果 : ['Tom', 'Jerry', 'Tom', 'Jerry', 'Tom', 'Jack', 'Jerry', 'Jack', 'Tom']转为二元元组效果 : [('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jack', 1), ('Jerry', 1), ('Jack', 1), ('Tom', 1)]D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spillingD:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spillingD:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spillingD:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling统计单词 : [('Tom', 4), ('Jack', 2), ('Jerry', 3)]D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spillingD:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling最终统计单词并排序 : [('Jack', 2), ('Jerry', 3), ('Tom', 4)]Process finished with exit code 0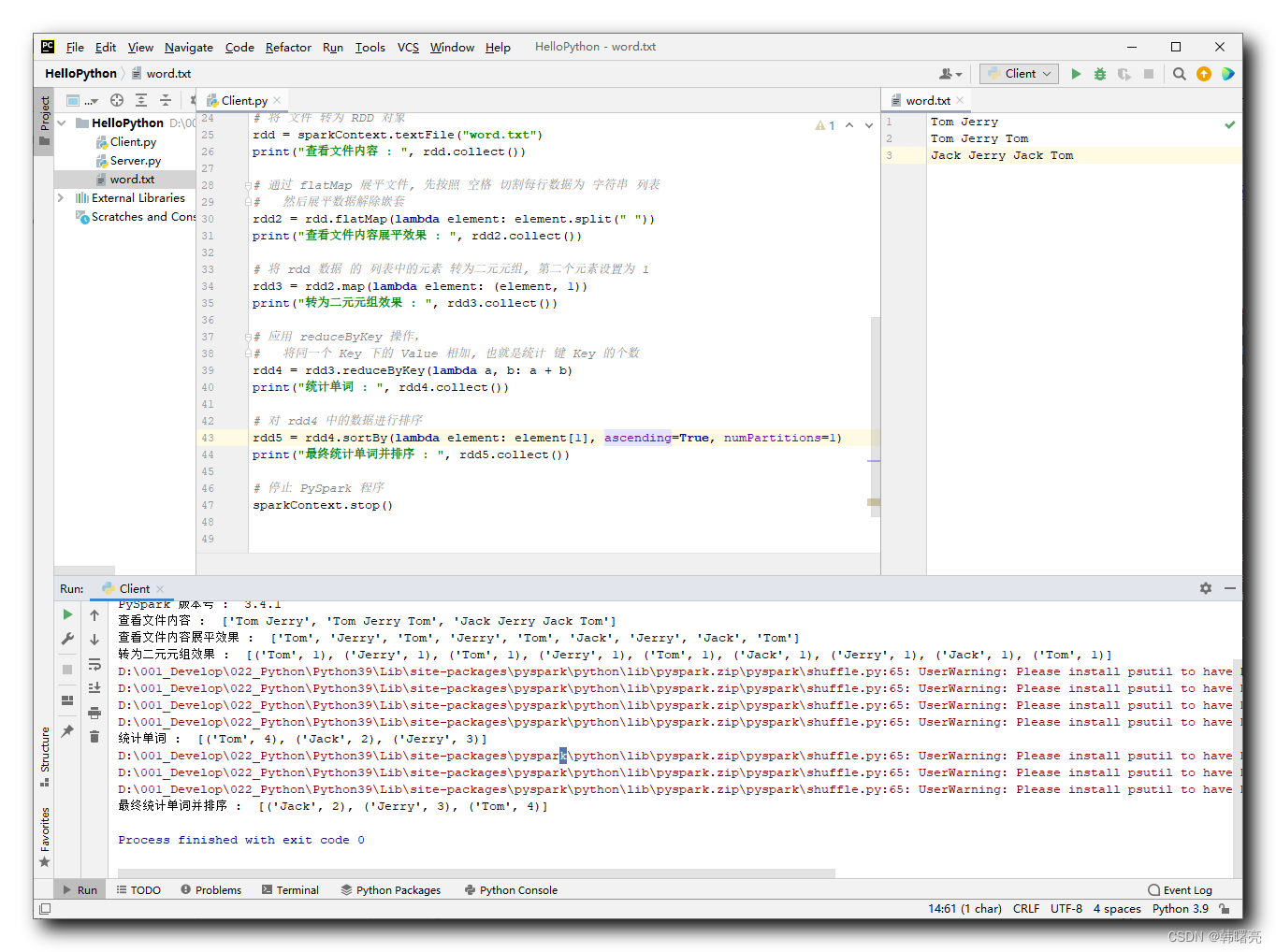
来源地址:https://blog.csdn.net/han1202012/article/details/132096941
--结束END--
本文标题: 【Python】PySpark 数据计算 ⑤ ( RDD#sortBy方法 - 排序 RDD 中的元素 )
本文链接: https://www.lsjlt.com/news/383833.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答
一口价域名售卖能注册吗?域名是网站的标识,简短且易于记忆,为在线用户提供了访问我们网站的简单路径。一口价是在域名交易中一种常见的模式,而这种通常是针对已经被注册的域名转售给其他人的一种方式。
一口价域名买卖的过程通常包括以下几个步骤:
1.寻找:买家需要在域名售卖平台上找到心仪的一口价域名。平台通常会为每个可售的域名提供详细的描述,包括价格、年龄、流
443px" 443px) https://www.west.cn/docs/wp-content/uploads/2024/04/SEO图片294.jpg https://www.west.cn/docs/wp-content/uploads/2024/04/SEO图片294-768x413.jpg 域名售卖 域名一口价售卖 游戏音频 赋值/切片 框架优势 评估指南 项目规模 安全指南 Osprey 游戏分析 游戏调试 游戏图形 游戏物理 开源库 魔方破解 游戏安全 反作弊 安全最佳实践 游戏逻辑 LaVie 域名转让平台

官方手机版

微信公众号

商务合作




0