Python 官方文档:入门教程 => 点击学习
文章目录 一、RDD#flatMap 方法1、RDD#flatMap 方法引入2、解除嵌套3、RDD#flatMap 语法说明 二、代码示例 - RDD#flatMap 方法
RDD#map 方法 可以 将 RDD 中的数据元素 逐个进行处理 , 处理的逻辑 需要用外部 通过 参数传入 map 函数 ;
RDD#flatMap 方法 是 在 RDD#map 方法 的基础上 , 增加了 " 解除嵌套 " 的作用 ;
RDD#flatMap 方法 也是 接收一个 函数 作为参数 , 该函数被应用于 RDD 中的每个元素及元素嵌套的子元素 , 并返回一个 新的 RDD 对象 ;
解除嵌套 含义 : 下面的的 列表 中 , 每个元素 都是一个列表 ;
lst = [[1, 2], [3, 4, 5], [6, 7, 8]]如果将上述 列表 解除嵌套 , 则新的 列表 如下 :
lst = [1, 2, 3, 4, 5, 6, 7, 8]RDD#flatMap 方法 先对 RDD 中的 每个元素 进行处理 , 然后再 将 计算结果展平放到一个新的 RDD 对象中 , 也就是 解除嵌套 ;
这样 原始 RDD 对象 中的 每个元素 , 都对应 新 RDD 对象中的若干元素 ;
RDD#flatMap 语法说明 :
newRDD = oldRDD.flatMap(lambda x: [element1, element2, ...])旧的 RDD 对象 oldRDD 中 , 每个元素应用一个 lambda 函数 , 该函数返回多个元素 , 返回的多个元素就会被展平放入新的 RDD 对象 newRDD 中 ;
代码示例 :
# 将 字符串列表 转为 RDD 对象rdd = sparkContext.parallelize(["Tom 18", "Jerry 12", "Jack 21"])# 应用 map 操作,将每个元素 按照空格 拆分rdd2 = rdd.flatMap(lambda element: element.split(" "))代码示例 :
"""PySpark 数据处理"""# 导入 PySpark 相关包from pyspark import SparkConf, SparkContext# 为 PySpark 配置 python 解释器import osos.environ['PYSPARK_Python'] = "Y:/002_WorkSpace/PyCharmProjects/pythonProject/venv/Scripts/python.exe"# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务# setMaster("local[*]") 表示在单机模式下 本机运行# setAppName("hello_spark") 是给 Spark 程序起一个名字sparkConf = SparkConf() \ .setMaster("local[*]") \ .setAppName("hello_spark")# 创建 PySpark 执行环境 入口对象sparkContext = SparkContext(conf=sparkConf)# 打印 PySpark 版本号print("PySpark 版本号 : ", sparkContext.version)# 将 字符串列表 转为 RDD 对象rdd = sparkContext.parallelize(["Tom 18", "Jerry 12", "Jack 21"])# 应用 map 操作,将每个元素 按照空格 拆分rdd2 = rdd.flatMap(lambda element: element.split(" "))# 打印新的 RDD 中的内容print(rdd2.collect())# 停止 PySpark 程序sparkContext.stop()执行结果 :
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py23/07/31 23:02:58 WARN shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: hadoop_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/windowsProblemsSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).23/07/31 23:02:59 WARN NativeCodeLoader: Unable to load native-hadoop library for your platfORM... using builtin-java classes where applicablePySpark 版本号 : 3.4.1['Tom', '18', 'Jerry', '12', 'Jack', '21']Process finished with exit code 0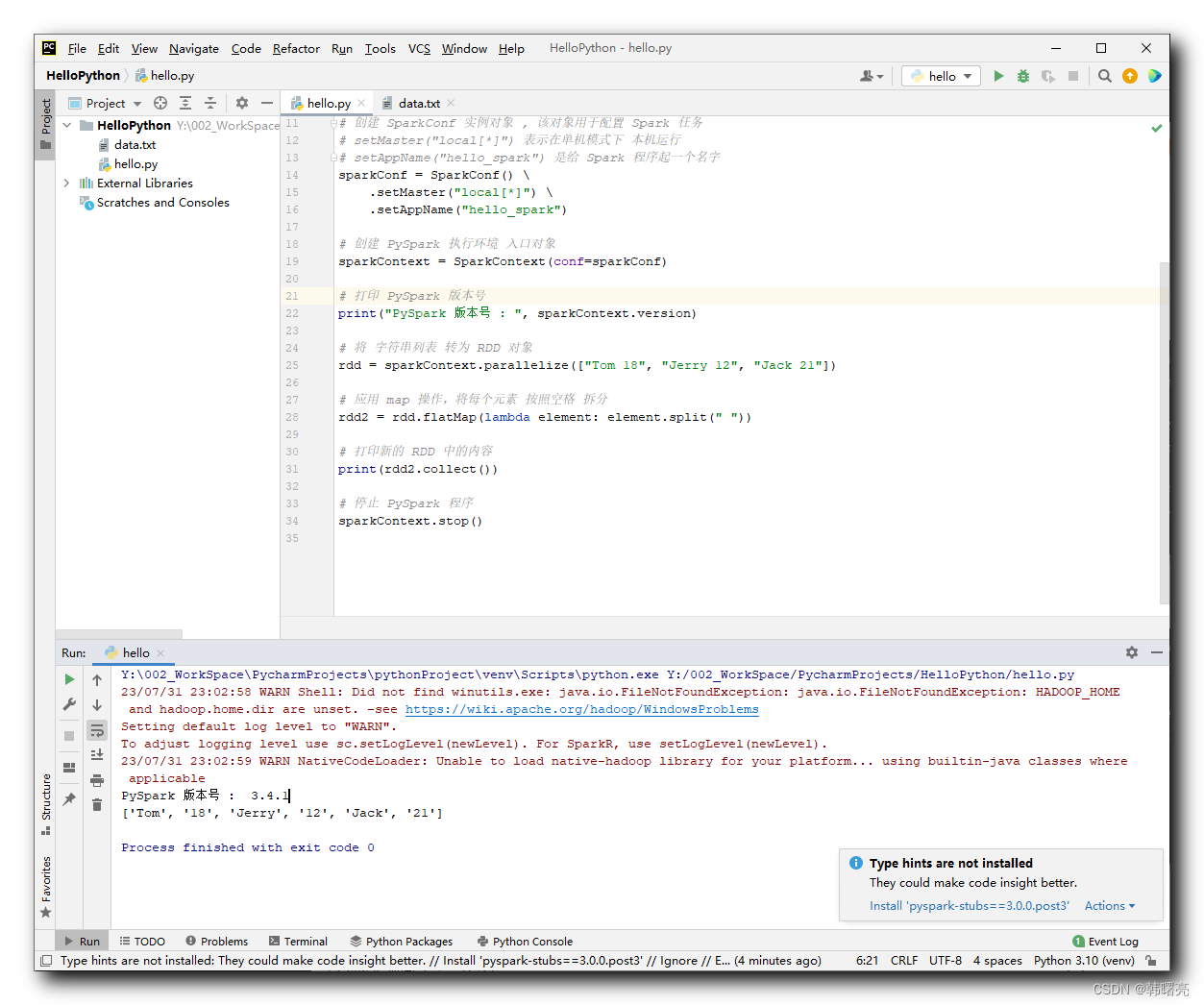
来源地址:https://blog.csdn.net/han1202012/article/details/132030548
--结束END--
本文标题: 【Python】PySpark 数据计算 ② ( RDD#flatMap 方法 | RDD#flatMap 语法 | 代码示例 )
本文链接: https://www.lsjlt.com/news/385730.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作



0