Python 官方文档:入门教程 => 点击学习
目录 【内容介绍】动手学深度学习-基于pytorch版本【脉络梳理】预备知识数据操作数据预处理线性代数矩阵计算自动求导 线性神经网络线性回归深度学习的基础优化算法线性回归的从零开始实现线
你好! 这是【李沐】动手学深度学习v2-基于pytorch版本的学习笔记
教材
源代码
安装教程(安装pytorch不要用pip,改成conda,pip太慢了,下载不下来)
个人推荐学习学习笔记
本节代码文件在源代码文件的chapter_preliminaries/ndarray.ipynb中
本节代码文件在源代码文件的chapter_preliminaries/pandas.ipynb中
import torcha=torch.arange(12)b=a.reshape((3,4))b[:]=2 # 改变b,a也会随之改变print(a) # tensor([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]) a[:]=1 # 改变a,b也会随之改变print(b) # tensor([[1, 1, 1, 1],[1, 1, 1, 1],[1, 1, 1, 1]])print(id(b)==id(a)) # False # 但a、b内存不同print(id(a)) # 2157597781424print(id(b)) # 2157597781424本节代码文件在源代码文件的chapter_preliminaries/linear-algebra.ipynb中
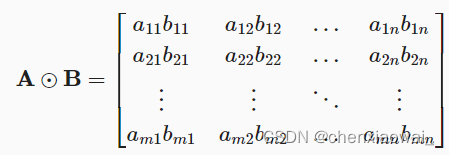
import torchA = torch.arange(20, dtype=torch.float32).reshape(5, 4)B = A.clone() # 通过分配新内存,将A的一个副本分配给Bprint(A)#tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[12., 13., 14., 15.],[16., 17., 18., 19.]])print(A+B)#tensor([[ 0., 2., 4., 6.],[ 8., 10., 12., 14.],[ 16., 18., 20., 22.],[24., 26., 28., 30.],[32., 34., 36., 38.]])print(A*B)#tensor([[0., 1., 4., 9.],[16., 25., 36., 49.],[64., 81., 100., 121.],[144., 169., 196., 225.],[256., 289., 324., 361.]])本节代码文件在源代码文件的chapter_preliminaries/calculus.ipynb中
将导数拓展到向量
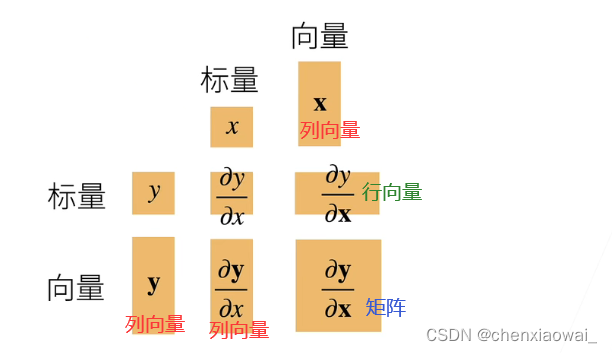
标量对列向量求导
其中, a 不是关于 x 的函数, 0 和 1 是向量 ; 其中,\it a不是关于\bf x的函数,\color{black} 0和\bf 1是向量; 其中,a不是关于x的函数,0和1是向量;

列向量对列向量求导
结果是矩阵
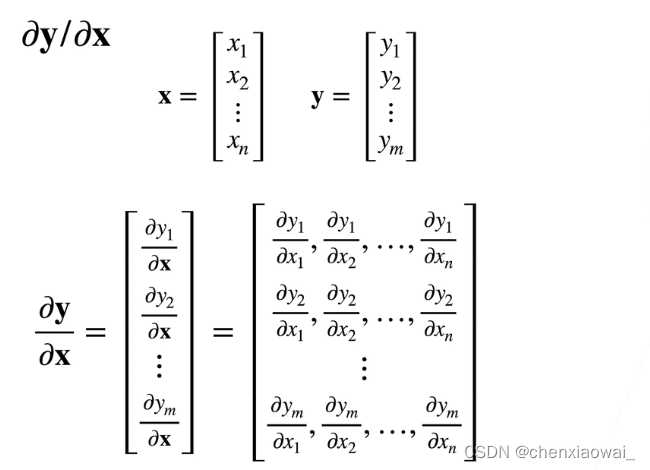
样例:
x ∈ R n , y ∈ R m , ∂ y ∂ x ∈ R m n ; a , a 和 A 不是关于 x 的函数, 0 和 I 是矩阵 ; \bf x\in\mathbb R^{n} ,\bf y\in\mathbb R^{m},\frac{\partial\bf y}{\partial\bf x}\in\mathbb R^{mn};\it a,\bf a和\bf A不是关于\bf x的函数,\color{black} 0和\bf I是矩阵; x∈Rn,y∈Rm,∂x∂y∈Rmn;a,a和A不是关于x的函数,0和I是矩阵;

将导数拓展到矩阵

本节代码文件在源代码文件的chapter_preliminaries/autograd.ipynb中
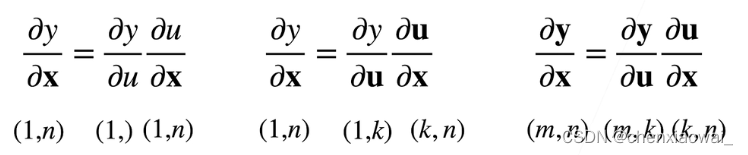


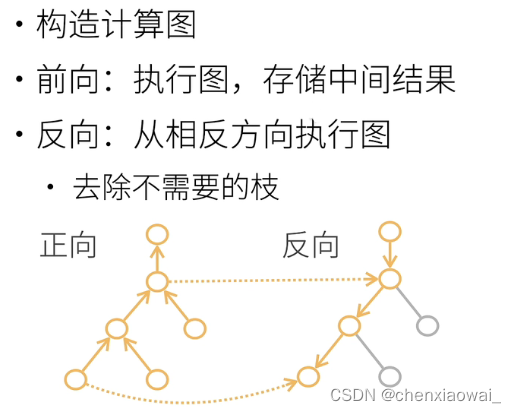
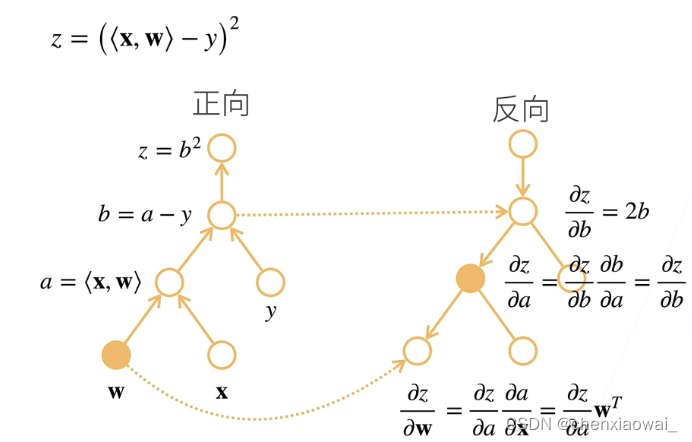
样例:

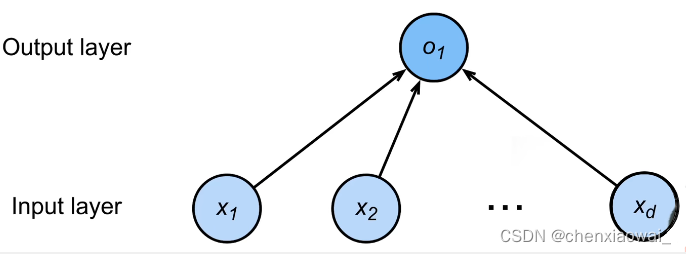
本节代码文件在源代码文件的chapter_linear-networks/linear-regression.ipynb中



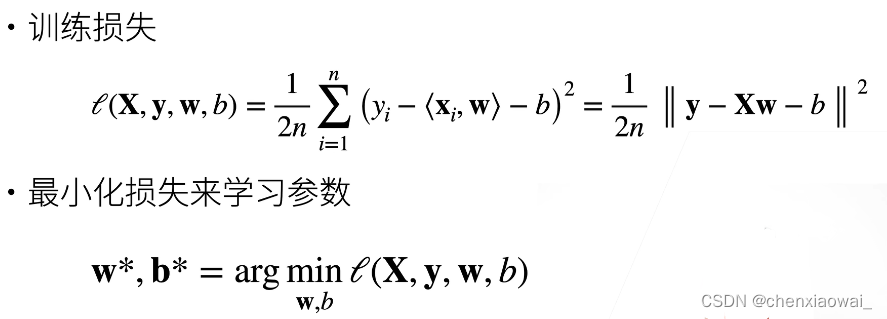



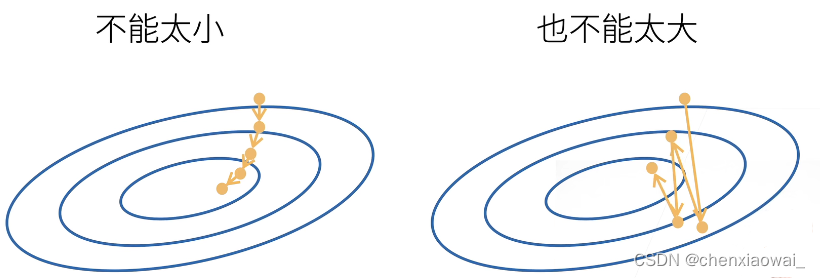



本节代码文件在源代码文件的chapter_linear-networks/linear-regression-scratch.ipynb中
其中,定义模型包括定义损失函数和定义优化算法
本节代码文件在源代码文件的chapter_linear-networks/linear-regression-concise.ipynb中
简洁实现是指通过使用深度学习框架来实现线性回归模型,具体流程与从零开始实现大体相同,不过一些常用函数不需要我们自己写了(直接导库,用别人写好的)
本节代码文件在源代码文件的chapter_linear-networks/softmax-regression.ipynb中
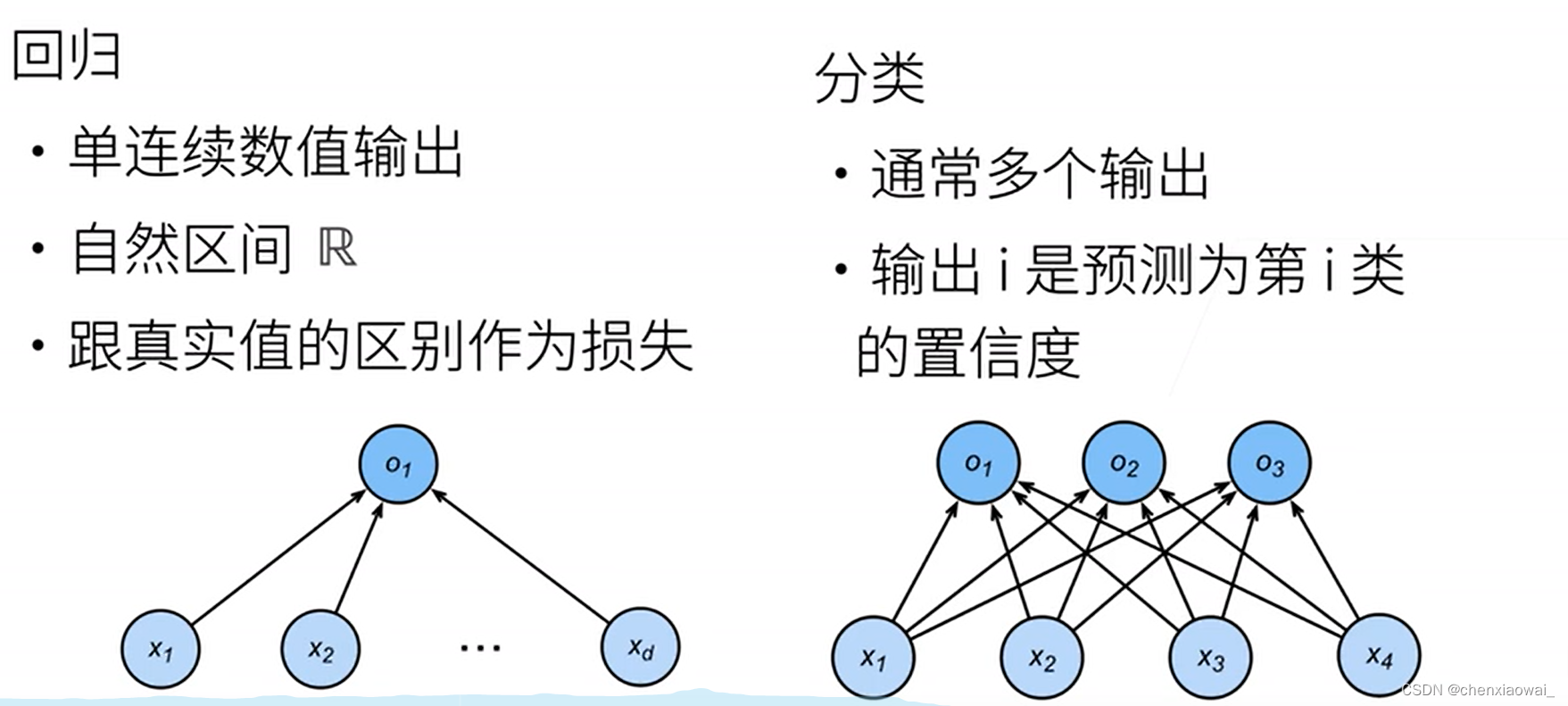
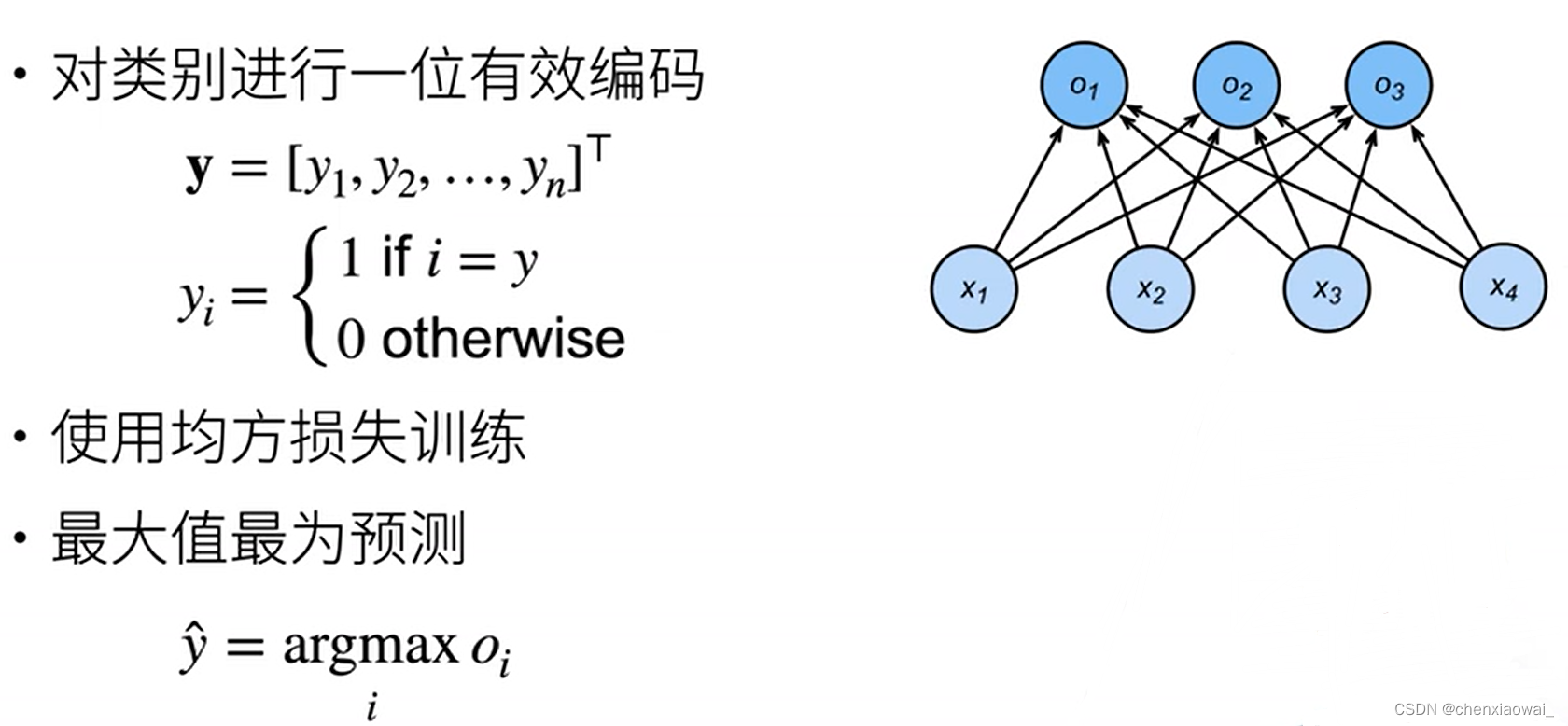
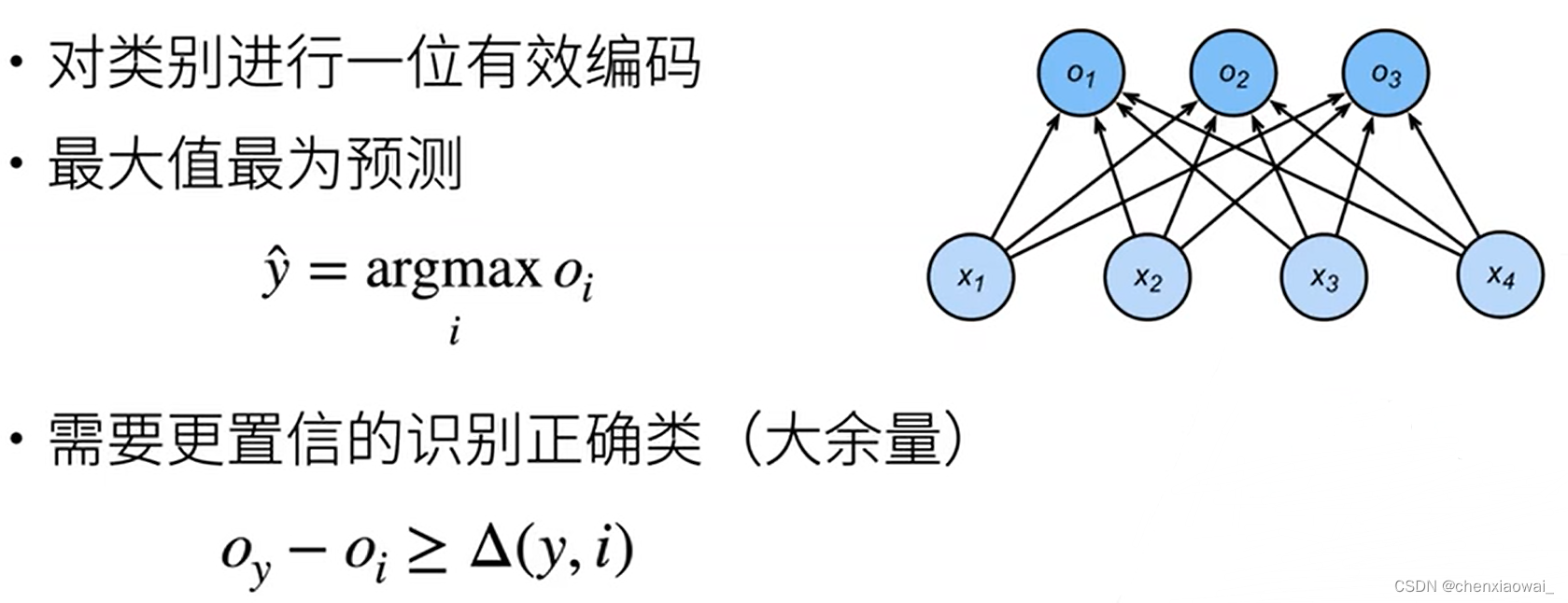
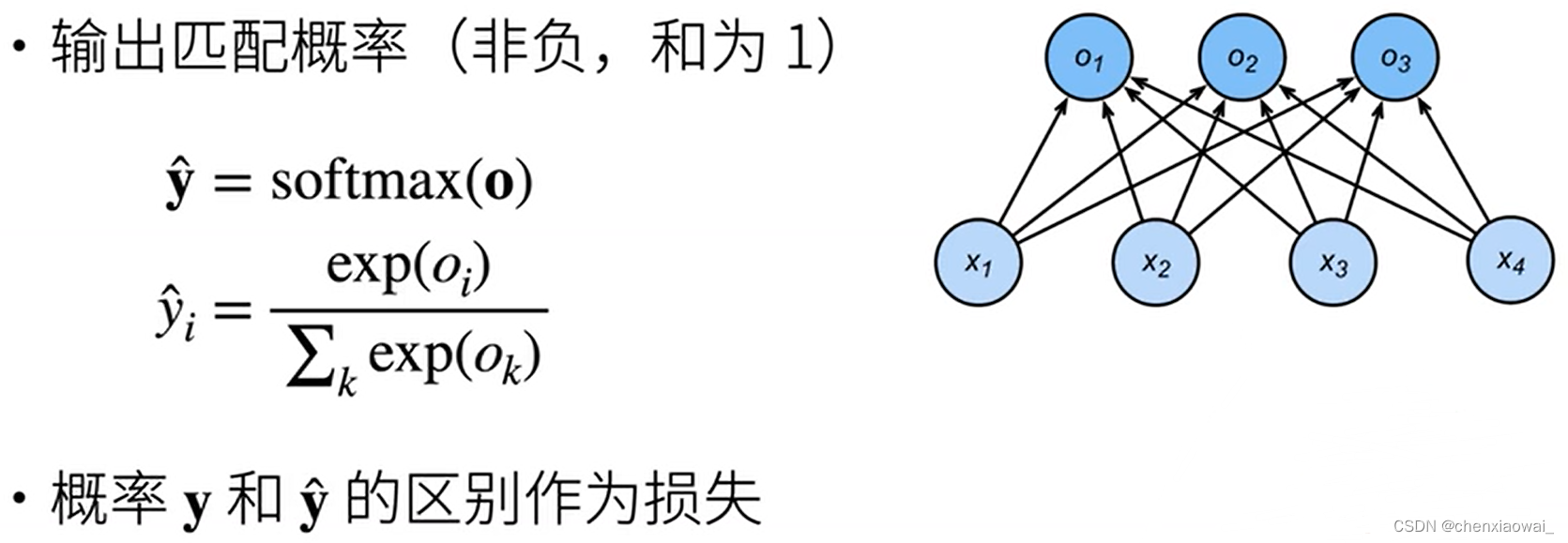


本节代码文件在源代码文件的chapter_linear-networks/softmax-regression.ipynb中
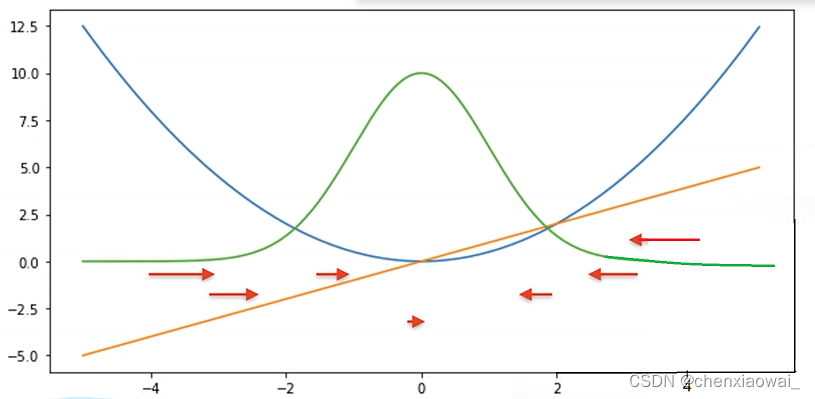
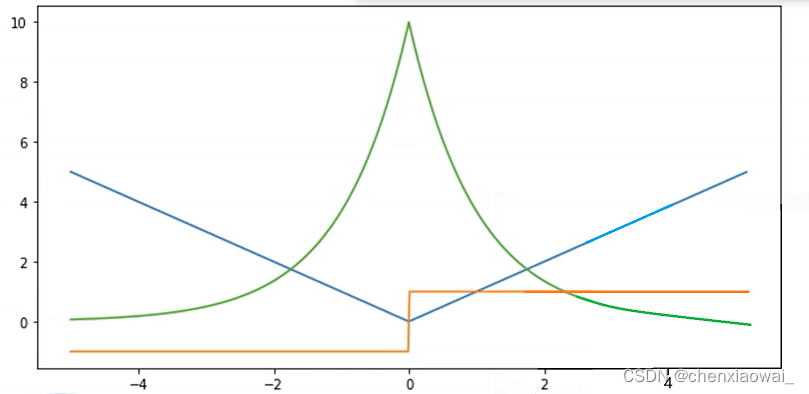
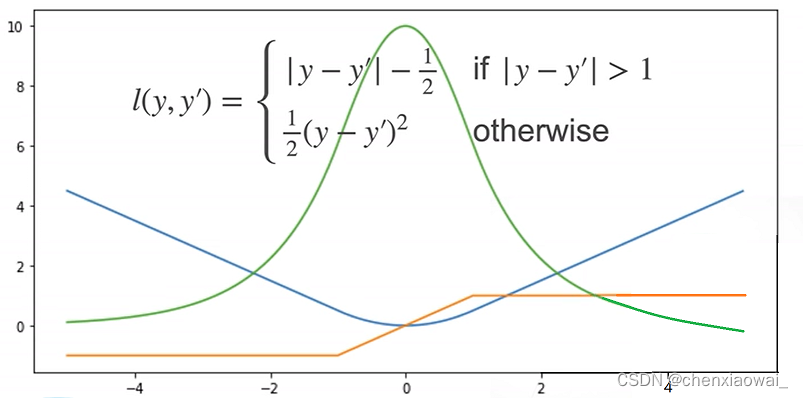
损失函数用来衡量预测值与真实值之间的区别,是机器学习里非常重要的概念。下面介绍三种常用的损失函数。
本节代码文件在源代码文件的chapter_linear-networks/image-classification-dataset.ipynb中
本节代码文件在源代码文件的chapter_linear-networks/softmax-regression-scratch.ipynb中
分类精度即正确预测数量与总预测数量之比
本节代码文件在源代码文件的chapter_linear-networks/softmax-regression-concise.ipynb中
通过深度学习框架的高级API也能更方便地实现softmax回归模型。
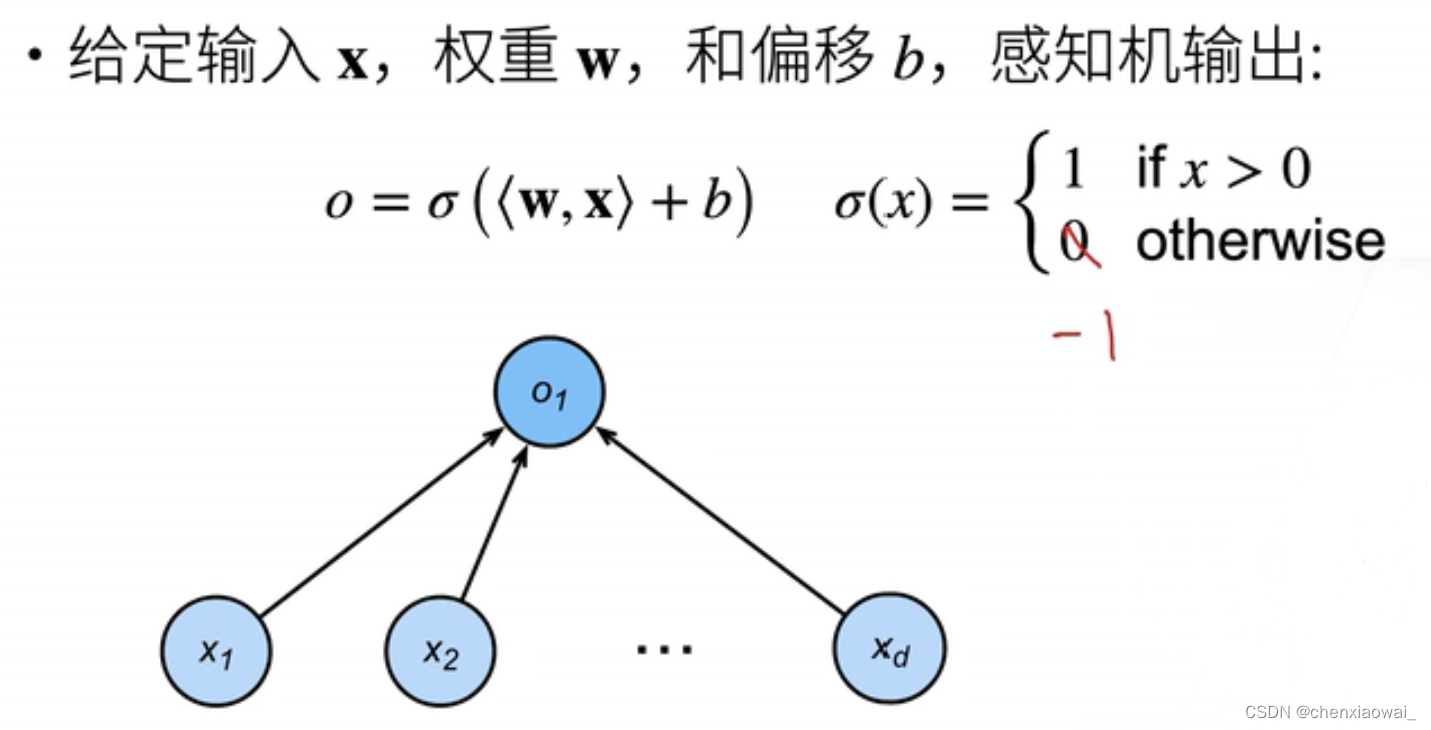

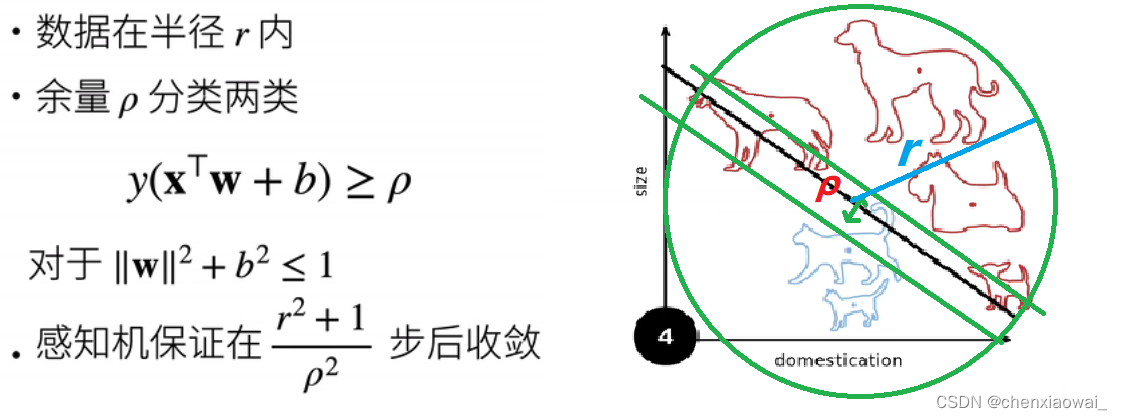
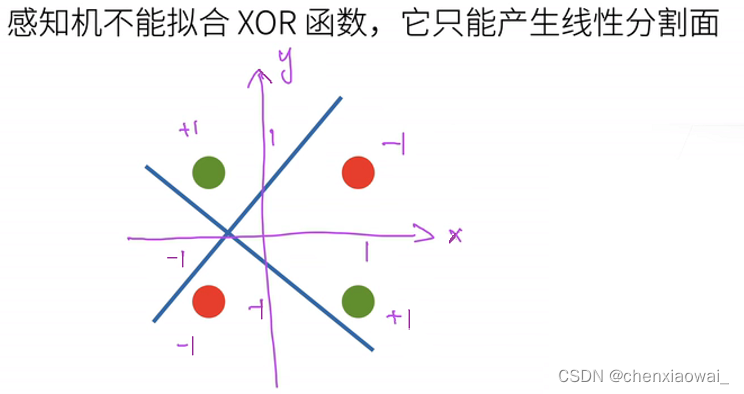

本节代码文件在源代码文件的chapter_multilayer-perceptrons/mlp.ipynb中
学习XOR
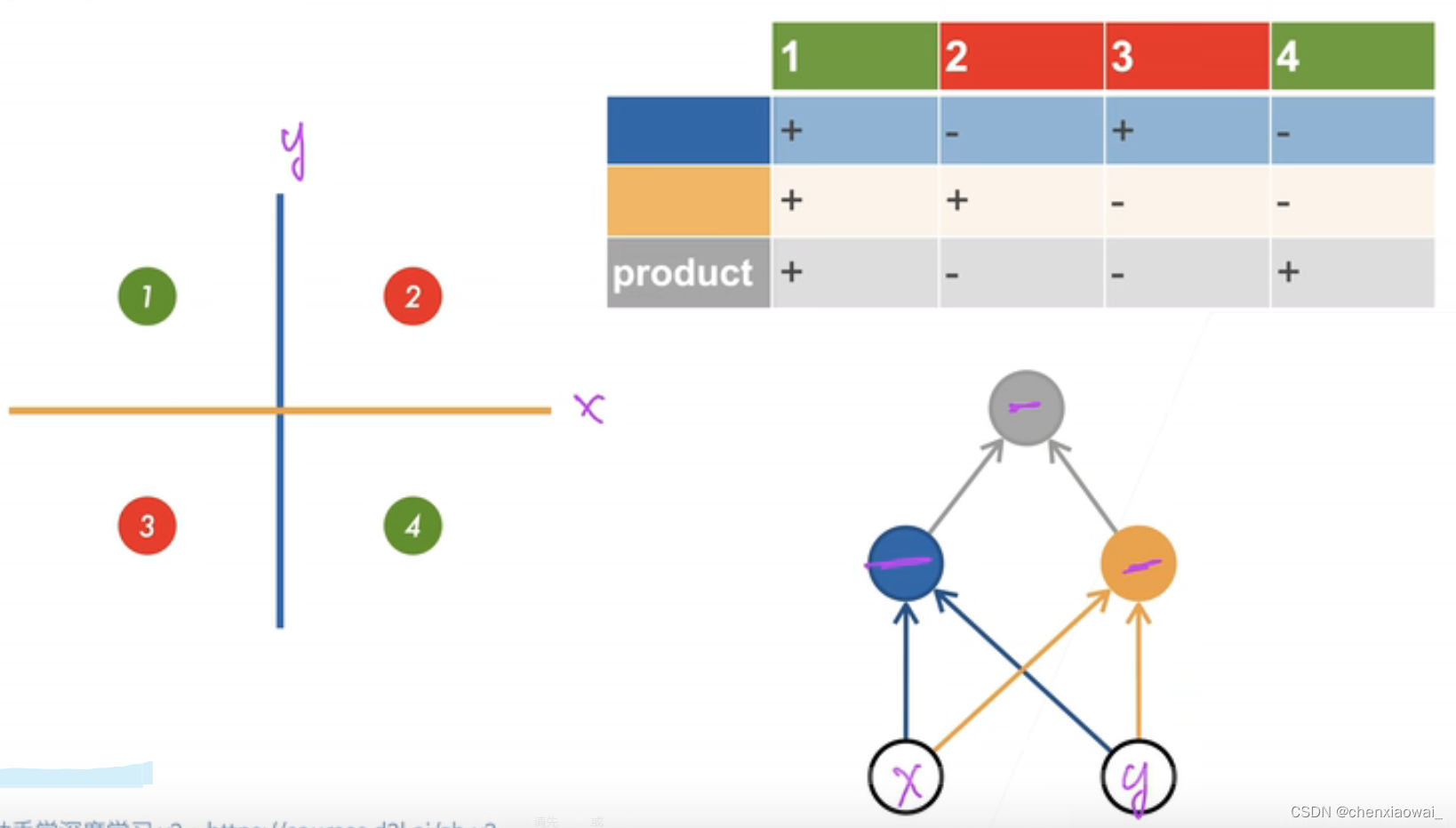
单隐藏层
隐藏层大小是超参数(输入和输出大小由数据决定,输出大小人为决定。)
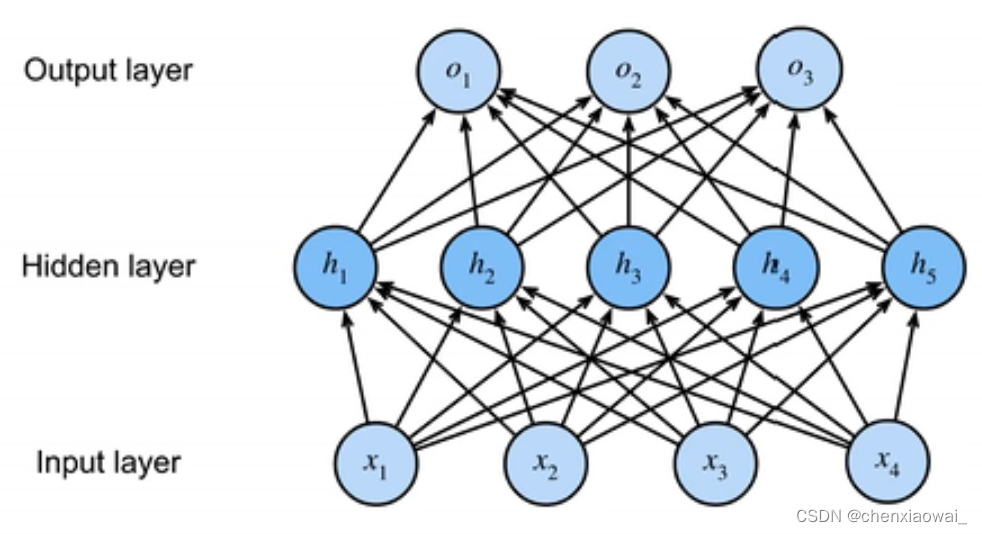
单隐藏层 — 单分类
只有一个输出,即输出是标量。

Q:为什么需要非线性的激活函数?(σ(x)不可以等于x,也不可以等于nx)
A: 如果激活函数是线性的,那么单隐藏层的多层感知机就变成了最简单的线性模型。

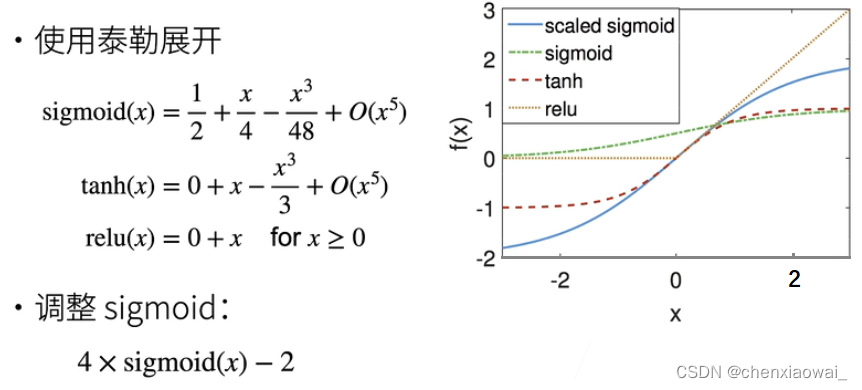
激活函数
①Sigmoid 激活函数
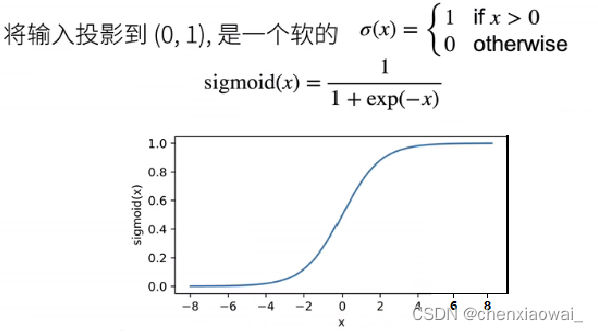
②Tanh 激活函数
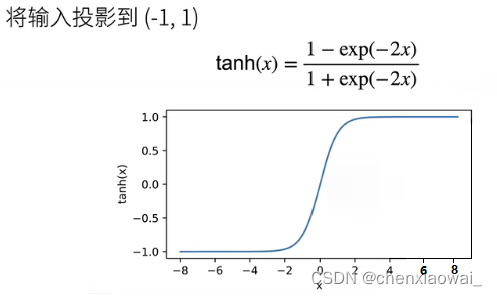
③ReLU 激活函数
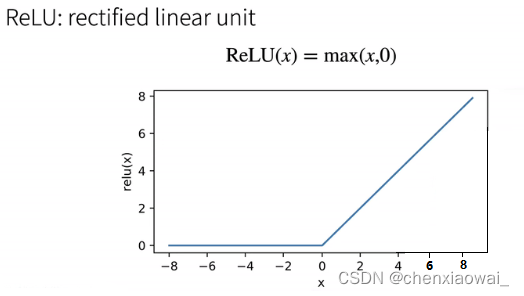
单隐藏层 — 多类分类
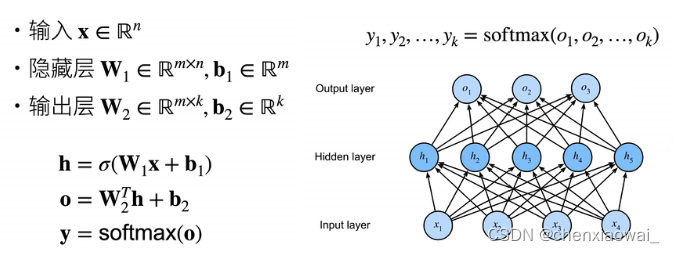
多隐藏层
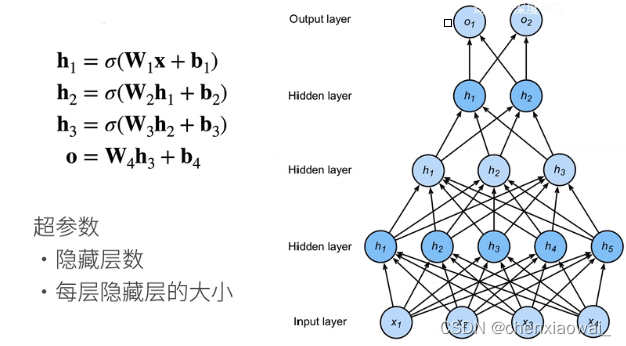
总结

本节代码文件在源代码文件的chapter_multilayer-perceptrons/mlp-scratch.ipynb中
本节代码文件在源代码文件的chapter_multilayer-perceptrons/mlp-concise.ipynb中
本节代码文件在源代码文件的chapter_multilayer-perceptrons/underfit-overfit.ipynb中




本节代码文件在源代码文件的chapter_multilayer-perceptrons/underfit-overfit.ipynb中
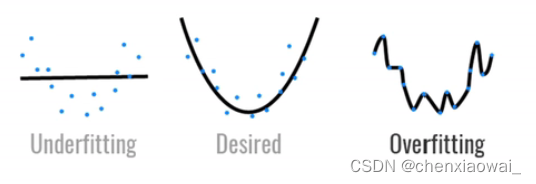

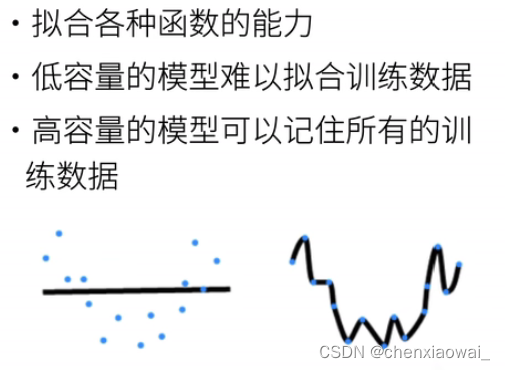
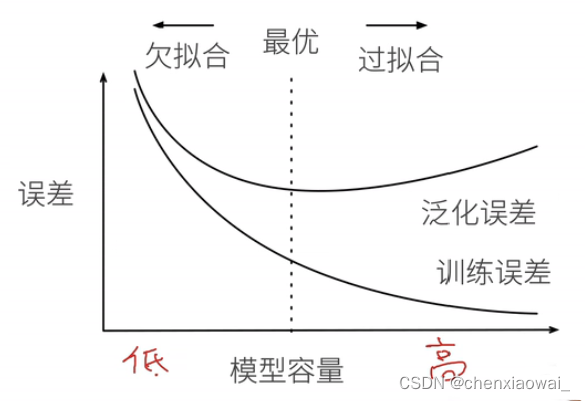
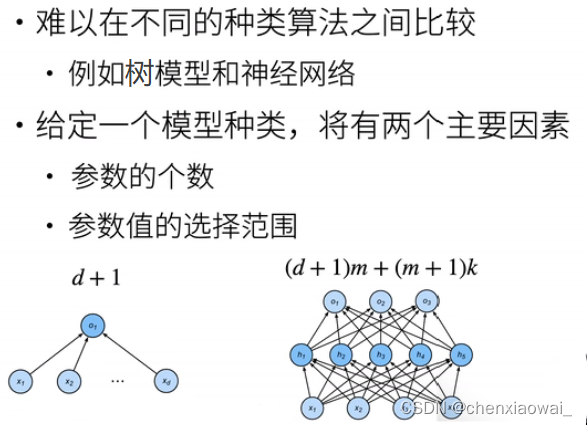

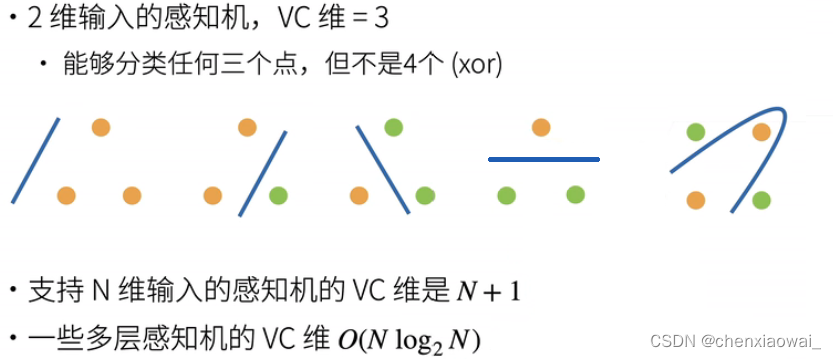


本节代码文件在源代码文件的chapter_multilayer-perceptrons/weight-decay.ipynb中
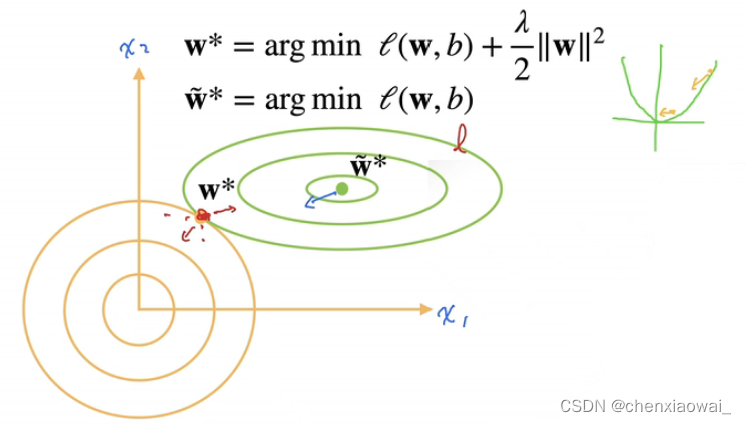
权重衰退是一种常见的处理过拟合(模型复杂度过高)的方法。




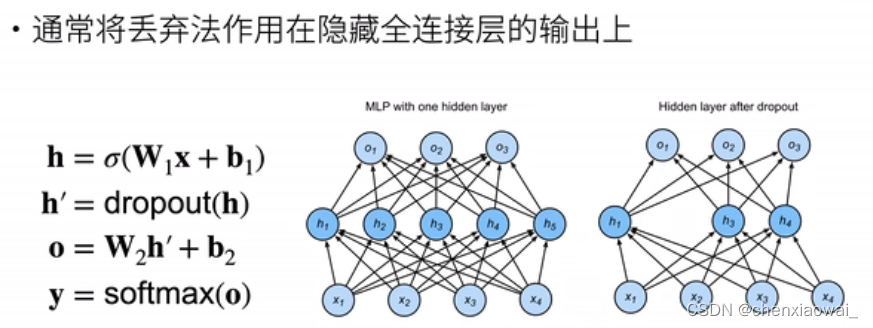
本节代码文件在源代码文件的chapter_multilayer-perceptrons/dropout.ipynb中




本节代码文件在源代码文件的chapter_multilayer-perceptrons/numerical-stability-and-init.ipynb中




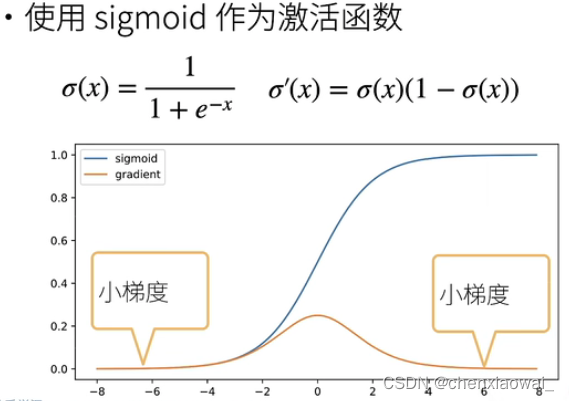
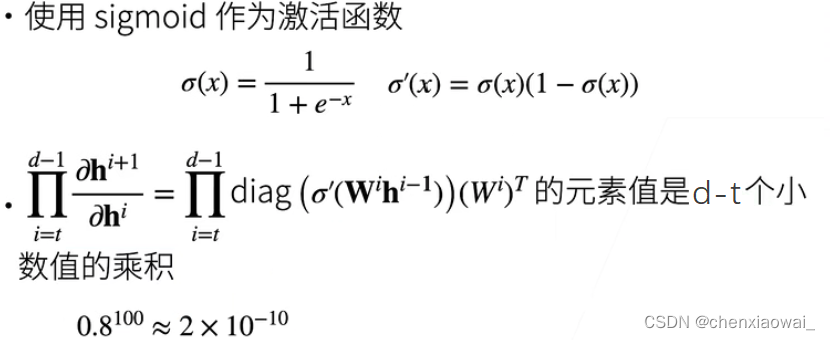



本节代码文件在源代码文件的chapter_multilayer-perceptrons/numerical-stability-and-init.ipynb中

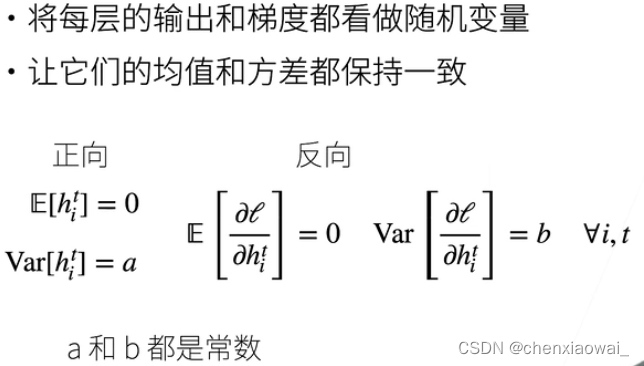

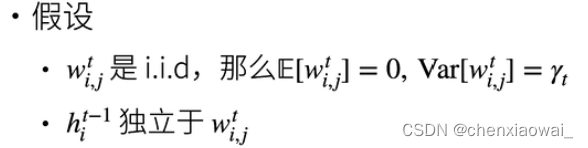
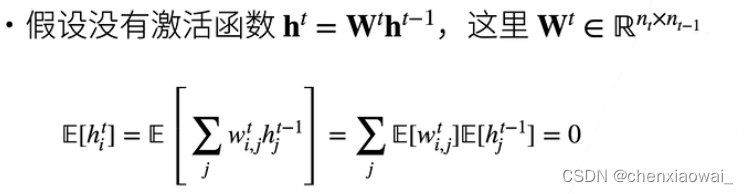
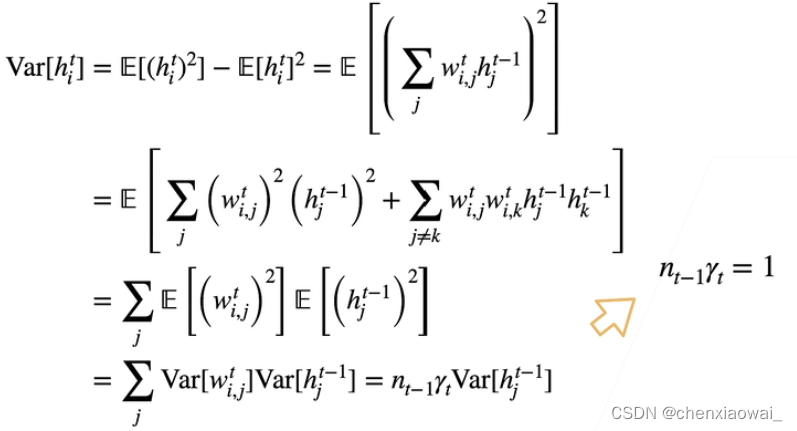

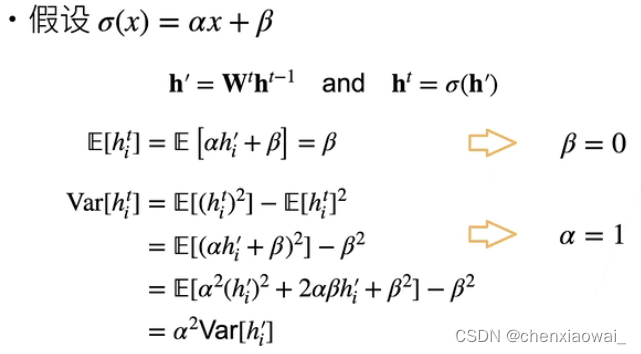



本节代码文件在源代码文件的chapter_deep-learning-computation/model-construction.ipynb中
块的组成
块(block)可以描述单个层、由多个层组成的组件或整个模型本身。 使用块进行抽象的一个好处是可以将一些块组合成更大的组件, 这一过程通常是递归的。
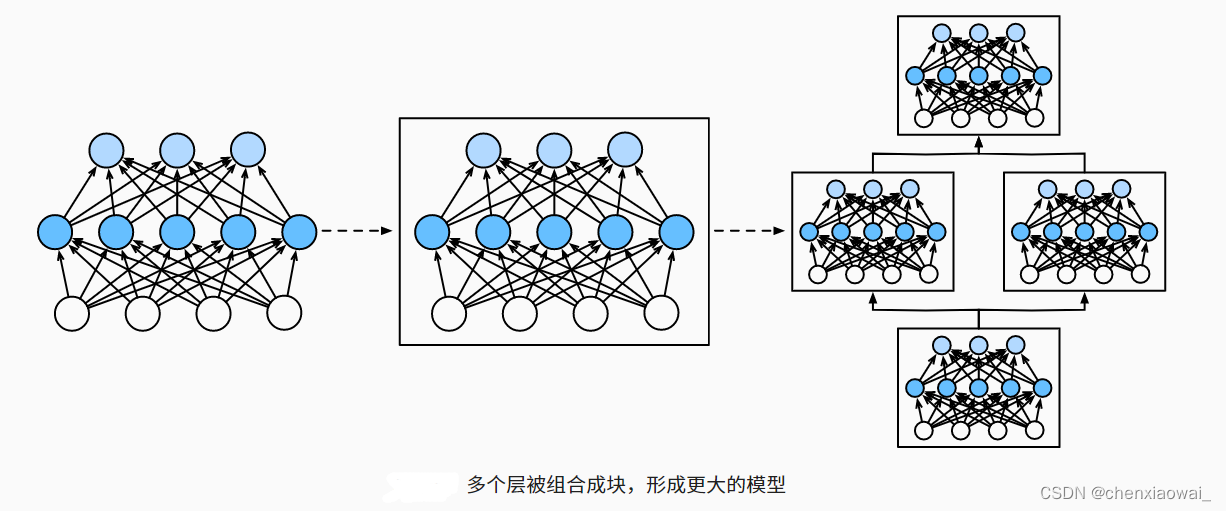
从编程的角度来看,块由类(class)表示。 它的任何子类都必须定义一个将其输入转换为输出的前向传播函数, 并且必须存储任何必需的参数。 注意,有些块不需要任何参数。 最后,为了计算梯度,块必须具有反向传播函数。 在定义我们自己的块时,由于自动微分提供了一些后端实现,我们只需要考虑前向传播函数和必需的参数。
块需要提供的基本功能
①将输入数据作为其前向传播函数的参数。
②通过前向传播函数来生成输出。注:输出的形状可能与输入的形状不同。
③计算其输出关于输入的梯度,可通过其反向传播函数进行访问。通常这是自动发生的。
④存储和访问前向传播计算所需的参数。
⑤根据需要初始化模型参数。
自定义块
在下面的代码片段中,我们从零开始编写一个块。 它包含一个多层感知机,其具有256个隐藏单元的隐藏层和一个10维输出层。 注意,下面的MLP类继承了表示块的类。我们的实现只需要提供我们自己的构造函数(Python中的__init__函数)和前向传播函数。
class MLP(nn.Module): # 用模型参数声明层。这里,我们声明两个全连接的层 def __init__(self): # 调用MLP的父类Module的构造函数来执行必要的初始化。 # 这样,在类实例化时也可以指定其他函数参数,例如模型参数params(稍后将介绍) super().__init__() self.hidden = nn.Linear(20, 256) # 隐藏层 self.out = nn.Linear(256, 10) # 输出层 # 定义模型的前向传播,即如何根据输入X返回所需的模型输出 def forward(self, X): # 注意,这里我们使用ReLU的函数版本,其在nn.functional模块中定义。 return self.out(F.relu(self.hidden(X)))注意一些关键细节: 首先,我们定制的__init__函数通过super().init() 调用父类的__init__函数, 省去了重复编写模版代码的痛苦。 然后,我们实例化两个全连接层, 分别为self.hidden和self.out。 注意,除非我们实现一个新的运算符, 否则我们不必担心反向传播函数或参数初始化, 系统将自动生成这些。
顺序块
回想一下Sequential的设计是为了把其他模块串起来。 为了构建我们自己的简化的MySequential, 我们只需要定义两个关键函数:
①一种将块逐个追加到列表中的函数。
②一种前向传播函数,用于将输入按追加块的顺序传递给块组成的“链条”。
下面的MySequential类提供了与默认Sequential类相同的功能:
class MySequential(nn.Module): def __init__(self, *args): super().__init__() for idx, module in enumerate(args): # 这里,module是Module子类的一个实例。我们把它保存在'Module'类的成员 # 变量_modules中。_module的类型是OrderedDict self._modules[str(idx)] = module def forward(self, X): # OrderedDict保证了按照成员添加的顺序遍历它们 for block in self._modules.values(): X = block(X) return X_modules:__init__函数将每个模块逐个添加到有序字典_modules中,_modules的主要优点是: 在模块的参数初始化过程中, 系统知道在_modules字典中查找需要初始化参数的子块。
本节代码文件在源代码文件的chapter_deep-learning-computation/parameters.ipynb中
import torchfrom torch import nnnet = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))X = torch.rand(size=(2, 4))net(X)print(net[2].state_dict())#OrderedDict([('weight', tensor([[ 0.0251, -0.2952, -0.1204, 0.3436, -0.3450, -0.0372, 0.0462, 0.2307]])), ('bias', tensor([0.2871]))])print(type(net[2].bias))#print(net[2].weight.grad == None)#Trueprint(*[(name, param.shape) for name, param in net[0].named_parameters()])#('weight', torch.Size([8, 4])) ('bias', torch.Size([8]))print(*[(name, param.shape) for name, param in net.named_parameters()])#('0.weight', torch.Size([8, 4])) ('0.bias', torch.Size([8])) ('2.weight', torch.Size([1, 8])) ('2.bias', torch.Size([1]))net.state_dict()['2.bias'].data#tensor([0.2871])def block1(): return nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 4), nn.ReLU())def block2(): net = nn.Sequential() for i in range(4): # 在这里嵌套 net.add_module(f'block {i}', block1()) return netrgnet = nn.Sequential(block2(), nn.Linear(4, 1))rgnet(X)#tensor([[0.1713],# [0.1713]], grad_fn=) print(rgnet)'''Sequential( (0): Sequential( (block 0): Sequential( (0): Linear(in_features=4, out_features=8, bias=True) (1): ReLU() (2): Linear(in_features=8, out_features=4, bias=True) (3): ReLU() ) (block 1): Sequential( (0): Linear(in_features=4, out_features=8, bias=True) (1): ReLU() (2): Linear(in_features=8, out_features=4, bias=True) (3): ReLU() ) (block 2): Sequential( (0): Linear(in_features=4, out_features=8, bias=True) (1): ReLU() (2): Linear(in_features=8, out_features=4, bias=True) (3): ReLU() ) (block 3): Sequential( (0): Linear(in_features=4, out_features=8, bias=True) (1): ReLU() (2): Linear(in_features=8, out_features=4, bias=True) (3): ReLU() ) ) (1): Linear(in_features=4, out_features=1, bias=True))'''rgnet[0][1][0].bias.data#tensor([-0.0444, -0.4451, -0.4149, 0.0549, -0.0969, 0.2053, -0.2514, 0.0220])def init_normal(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, mean=0, std=0.01) nn.init.zeros_(m.bias)net.apply(init_normal)net[0].weight.data[0], net[0].bias.data[0]#(tensor([-0.0017, 0.0232, -0.0026, 0.0026]), tensor(0.))def init_constant(m): if type(m) == nn.Linear: nn.init.constant_(m.weight, 1) nn.init.zeros_(m.bias)net.apply(init_constant)net[0].weight.data[0], net[0].bias.data[0]#(tensor([1., 1., 1., 1.]), tensor(0.))def xavier(m): if type(m) == nn.Linear: nn.init.xavier_uniform_(m.weight)def init_42(m): if type(m) == nn.Linear: nn.init.constant_(m.weight, 42)net[0].apply(xavier)net[2].apply(init_42)print(net[0].weight.data[0])#tensor([-0.4645, 0.0062, -0.5186, 0.3513])print(net[2].weight.data)#tensor([[42., 42., 42., 42., 42., 42., 42., 42.]])def my_init(m): if type(m) == nn.Linear: print("Init", *[(name, param.shape) for name, param in m.named_parameters()][0]) nn.init.uniform_(m.weight, -10, 10) m.weight.data *= m.weight.data.abs() >= 5'''Init weight torch.Size([8, 4])Init weight torch.Size([1, 8])'''net.apply(my_init)net[0].weight[:2]'''tensor([[ 8.8025, 6.4078, 0.0000, -8.4598], [-0.0000, 9.0582, 8.8258, 7.4997]], grad_fn=)''' net[0].weight.data[:] += 1net[0].weight.data[0, 0] = 42net[0].weight.data[0]#tensor([42.0000, 7.4078, 1.0000, -7.4598])# 我们需要给共享层一个名称,以便可以引用它的参数shared = nn.Linear(8, 8)net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), shared, nn.ReLU(), shared, nn.ReLU(), nn.Linear(8, 1))net(X)# 检查参数是否相同print(net[2].weight.data[0] == net[4].weight.data[0])'''tensor([True, True, True, True, True, True, True, True])'''net[2].weight.data[0, 0] = 100# 确保它们实际上是同一个对象,而不只是有相同的值print(net[2].weight.data[0] == net[4].weight.data[0])'''tensor([True, True, True, True, True, True, True, True])'''本节代码文件在源代码文件的chapter_deep-learning-computation/custom-layer.ipynb中
不带参数的层
下面的CenteredLayer类要从其输入中减去均值。 要构建它,我们只需继承基础层类并实现前向传播功能。
import torchimport torch.nn.functional as Ffrom torch import nnclass CenteredLayer(nn.Module): def __init__(self): super().__init__() def forward(self, X): return X - X.mean()让我们向该层提供一些数据,验证它是否能按预期工作。
layer = CenteredLayer()layer(torch.FloatTensor([1, 2, 3, 4, 5]))#tensor([-2., -1., 0., 1., 2.])我们可以将层作为组件合并到更复杂的模型中,比如:
net = nn.Sequential(nn.Linear(8, 128), CenteredLayer())带参数的层
下面我们定义具有参数的层, 这些参数可以通过训练进行调整。 我们可以使用内置函数来创建参数,这些函数提供一些基本的管理功能。 比如管理访问、初始化、共享、保存和加载模型参数。 这样做的好处之一是:我们不需要为每个自定义层编写自定义的序列化程序。
现在,让我们实现自定义版本的全连接层。该层需要两个参数,一个用于表示权重,另一个用于表示偏置项。 在此实现中,我们使用修正线性单元作为激活函数。该层需要输入参数:in_units和units,分别表示输入数(输入维度)和输出数(输出维度)。
class MyLinear(nn.Module): def __init__(self, in_units, units): super().__init__() self.weight = nn.Parameter(torch.randn(in_units, units)) self.bias = nn.Parameter(torch.randn(units,)) def forward(self, X): linear = torch.matmul(X, self.weight.data) + self.bias.data return F.relu(linear)linear = MyLinear(5, 3)linear.weight'''Parameter containing:tensor([[ 1.9054, -3.4102, -0.9792], [ 1.5522, 0.8707, 0.6481], [ 1.0974, 0.2568, 0.4034], [ 0.1416, -1.1389, 0.5875], [-0.7209, 0.4432, 0.1222]], requires_grad=True)'''我们可以使用自定义层直接执行前向传播计算:
linear(torch.rand(2, 5))'''tensor([[2.4784, 0.0000, 0.8991], [3.6132, 0.0000, 1.1160]])'''我们还可以使用自定义层构建模型,就像使用内置的全连接层一样使用自定义层:
net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1))net(torch.rand(2, 64))'''tensor([[0.], [0.]])'''本节代码文件在源代码文件的chapter_deep-learning-computation/read-write.ipynb中
有时我们希望保存训练的模型, 以备将来在各种环境中使用(比如在部署中进行预测)。 此外,当运行一个耗时较长的训练过程时, 最佳的做法是定期保存中间结果, 以确保在服务器电源被不小心断掉时,我们不会损失几天的计算结果。
加载和保存张量
对于单个张量,我们可以直接调用load和save函数分别读写它们。 这两个函数都要求我们提供一个名称,save要求将要保存的变量作为输入。
import torchfrom torch import nnfrom torch.nn import functional as Fx = torch.arange(4)torch.save(x, 'x-file')我们现在可以将存储在文件中的数据读回内存。
x2 = torch.load('x-file')x2#tensor([0, 1, 2, 3])我们可以存储一个张量列表,然后把它们读回内存。
y = torch.zeros(4)torch.save([x, y],'x-files')x2, y2 = torch.load('x-files')(x2, y2)#(tensor([0, 1, 2, 3]), tensor([0., 0., 0., 0.]))我们甚至可以写入或读取从字符串映射到张量的字典。 当我们要读取或写入模型中的所有权重时,这很方便。
mydict = {'x': x, 'y': y}torch.save(mydict, 'mydict')mydict2 = torch.load('mydict')mydict2#{'x': tensor([0, 1, 2, 3]), 'y': tensor([0., 0., 0., 0.])}加载和保存模型参数
保存单个权重向量(或其他张量)确实有用, 但是如果我们想保存整个模型,并在以后加载它们, 单独保存每个向量则会变得很麻烦。 毕竟,我们可能有数百个参数散布在各处。 因此,深度学习框架提供了内置函数来保存和加载整个网络。 需要注意的一个重要细节是,这将保存模型的参数而不是保存整个模型。 例如,如果我们有一个3层多层感知机,我们需要单独指定架构。 因为模型本身可以包含任意代码,所以模型本身难以序列化。 因此,为了恢复模型,我们需要用代码生成架构, 然后从磁盘加载参数。 让我们从熟悉的多层感知机开始尝试一下。
class MLP(nn.Module): def __init__(self): super().__init__() self.hidden = nn.Linear(20, 256) self.output = nn.Linear(256, 10) def forward(self, x): return self.output(F.relu(self.hidden(x)))net = MLP()X = torch.randn(size=(2, 20))Y = net(X)接下来,我们将模型的参数存储在一个叫做“mlp.params”的文件中。
torch.save(net.state_dict(), 'mlp.params')为了恢复模型,我们实例化了原始多层感知机模型的一个备份。 这里我们不需要随机初始化模型参数,而是直接读取文件中存储的参数。
clone = MLP()clone.load_state_dict(torch.load('mlp.params'))clone.eval()'''MLP( (hidden): Linear(in_features=20, out_features=256, bias=True) (output): Linear(in_features=256, out_features=10, bias=True))'''由于两个实例具有相同的模型参数,在输入相同的X时, 两个实例的计算结果应该相同。 让我们来验证一下。
Y_clone = clone(X)Y_clone == Y'''tensor([[True, True, True, True, True, True, True, True, True, True], [True, True, True, True, True, True, True, True, True, True]])'''本节代码文件在源代码文件的chapter_convolutional-neural-networks/why-conv.ipynb中




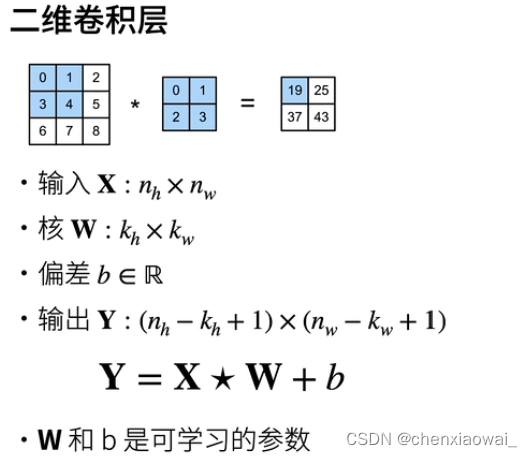
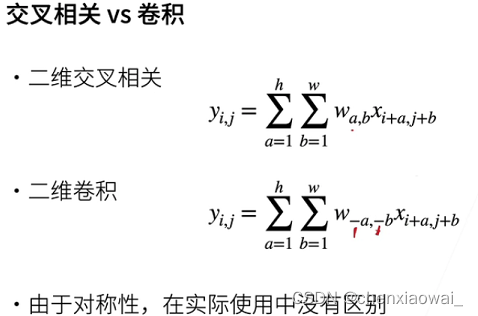
本节代码文件在源代码文件的chapter_convolutional-neural-networks/conv-layer.ipynb中
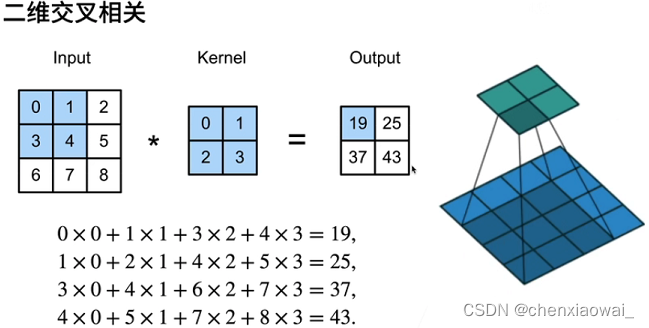



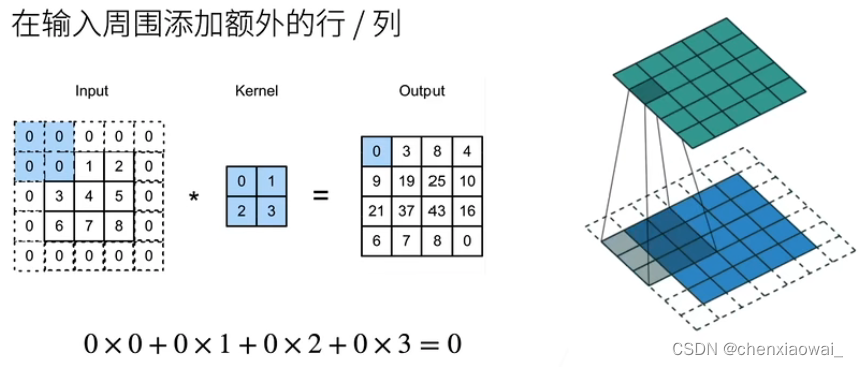
本节代码文件在源代码文件的chapter_convolutional-neural-networks/padding-and-strides.ipynb中
填充和步幅是卷积层的两个控制输出大小的超参数



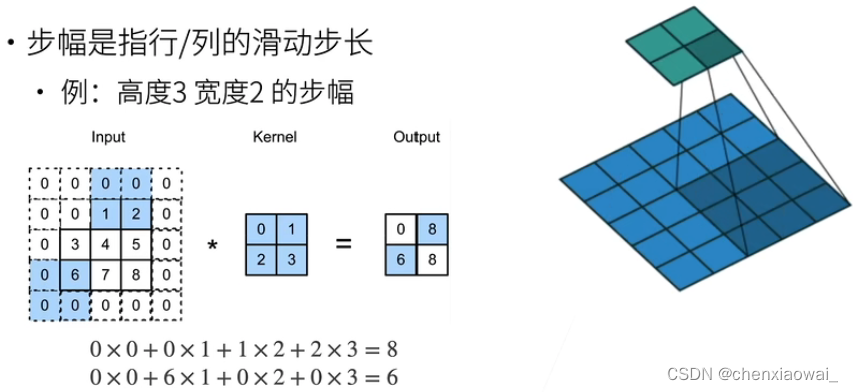


本节代码文件在源代码文件的chapter_convolutional-neural-networks/channels.ipynb中

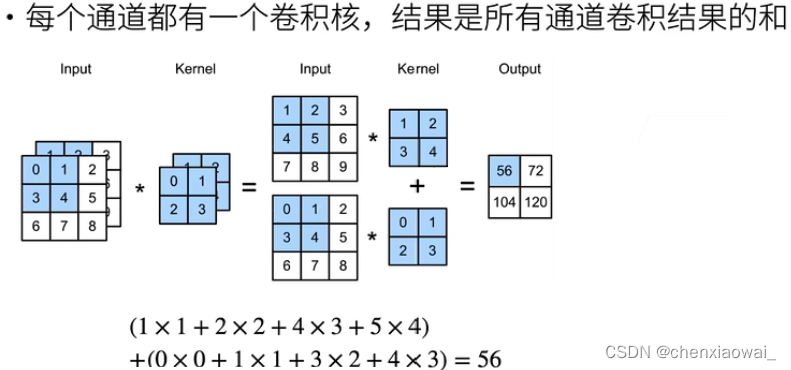
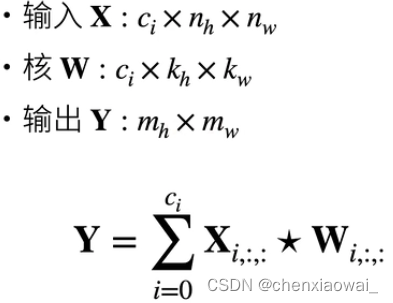


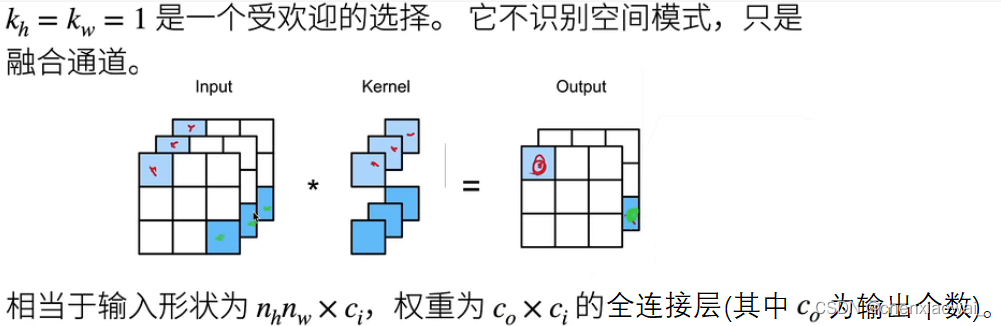


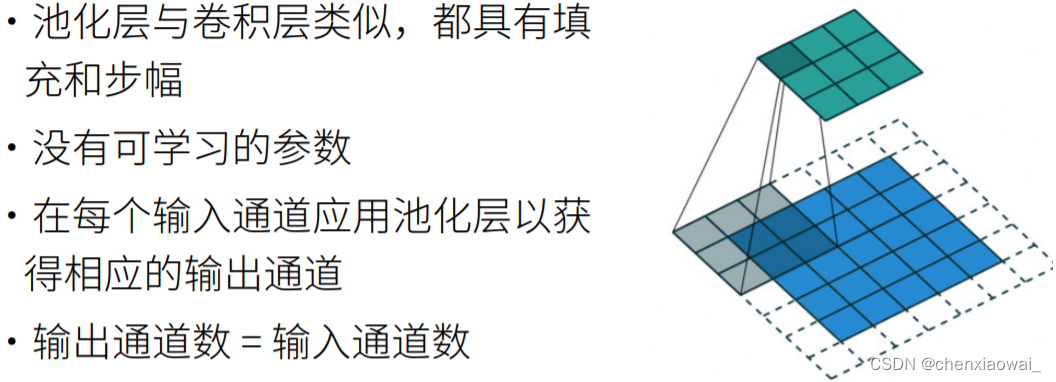
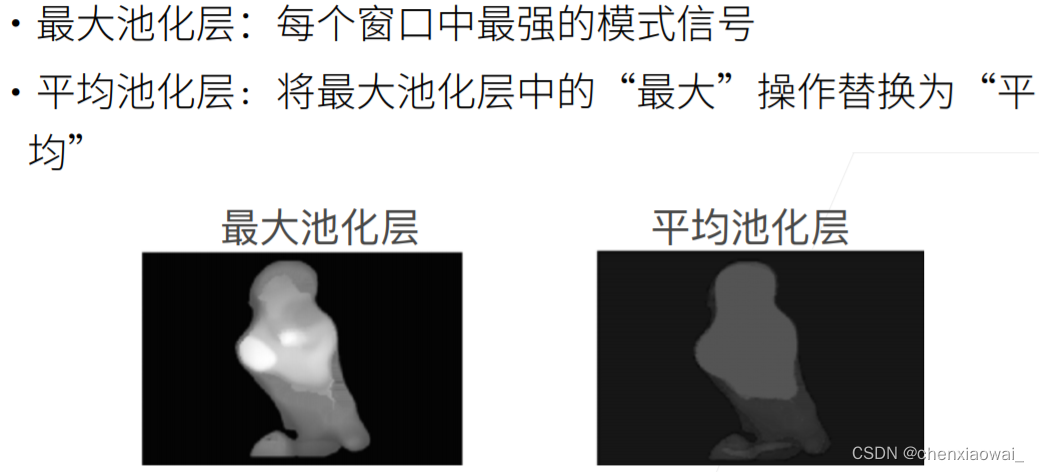
本节代码文件在源代码文件的chapter_convolutional-neural-networks/pooling.ipynb中

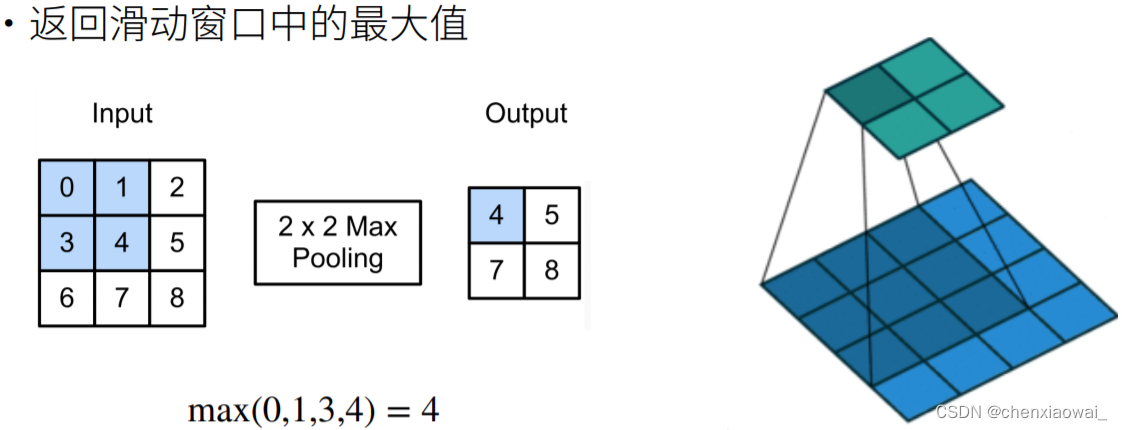


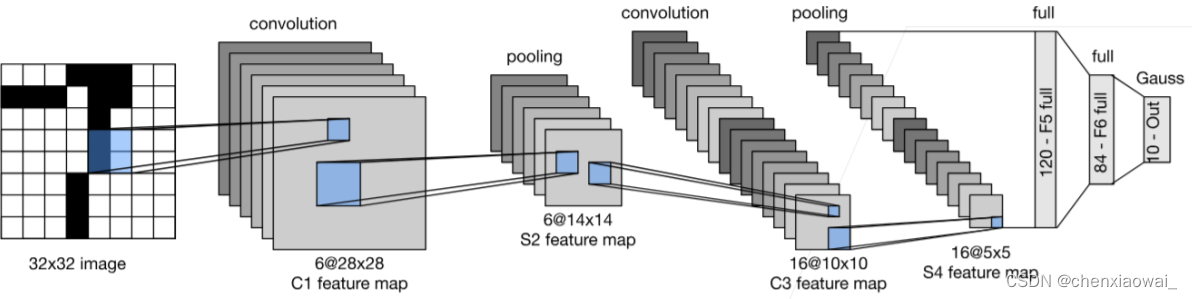
本节代码文件在源代码文件的chapter_convolutional-neural-networks/lenet.ipynb中



本节代码文件在源代码文件的chapter_convolutional-modern/alexnet.ipynb中
机器学习VS神经网路
在上世纪90年代初到2012年之间的大部分时间里,神经网络往往被其他机器学习方法超越,如支持向量机(support vector Machines)。

计算机视觉与几何学
卷积神经网络通常用在计算机视觉,在2000年时,计算机视觉的知识主要来源于几何学。

计算机视觉与特征工程
15年前,计算机视觉中,最重要的是特征工程。

深度学习的崛起原因
尽管一直有一群执着的研究者不断钻研,试图学习视觉数据的逐级表征,然而很长一段时间里这些尝试都未有突破。深度卷积神经网络的突破出现在2012年。突破可归因于两个关键因素。
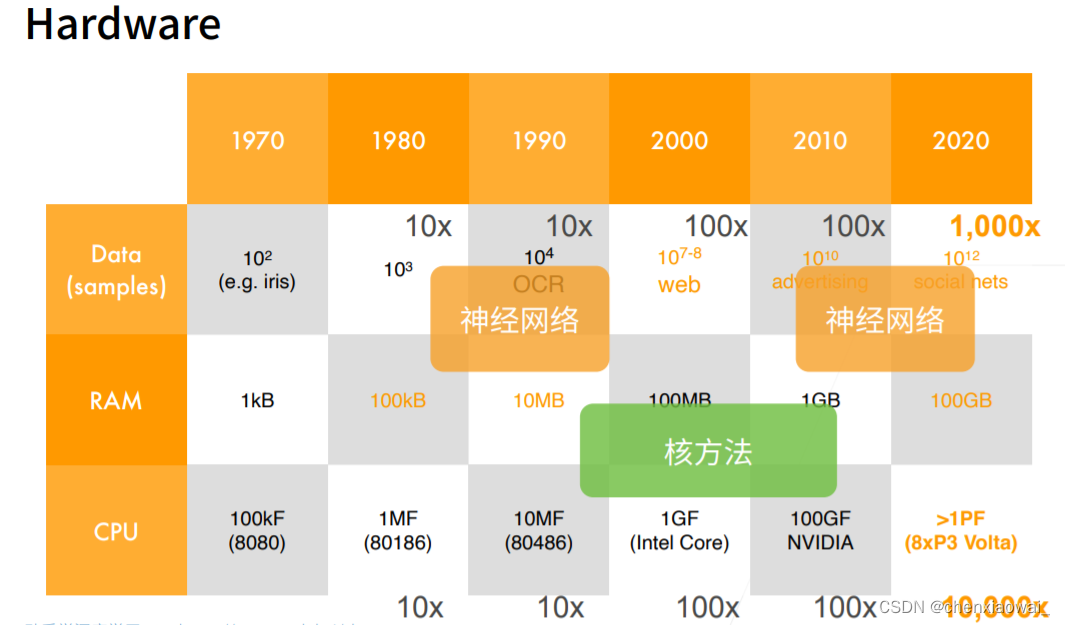
①硬件
2012年,当Alex Krizhevsky和Ilya Sutskever实现了可以在GPU硬件上运行的深度卷积神经网络时,一个重大突破出现了。他们意识到卷积神经网络中的计算瓶颈:卷积和矩阵乘法,都是可以在硬件上并行化的操作。 于是,他们使用两个显存为3GB的NVIDIA GTX580 GPU实现了快速卷积运算。他们的创新cuda-convnet几年来它一直是行业标准,并推动了深度学习热潮。
②数据
2009年,ImageNet数据集发布,并发起ImageNet挑战赛:要求研究人员从100万个样本中训练模型,以区分1000个不同类别的对象。ImageNet数据集由斯坦福教授李飞飞小组的研究人员开发,利用谷歌图像搜索(Google Image Search)对每一类图像进行预筛选,并利用亚马逊众包(Amazon Mechanical Turk)来标注每张图片的相关类别。这种规模是前所未有的。这项被称为ImageNet的挑战赛推动了计算机视觉和机器学习研究的发展,挑战研究人员确定哪些模型能够在更大的数据规模下表现最好。
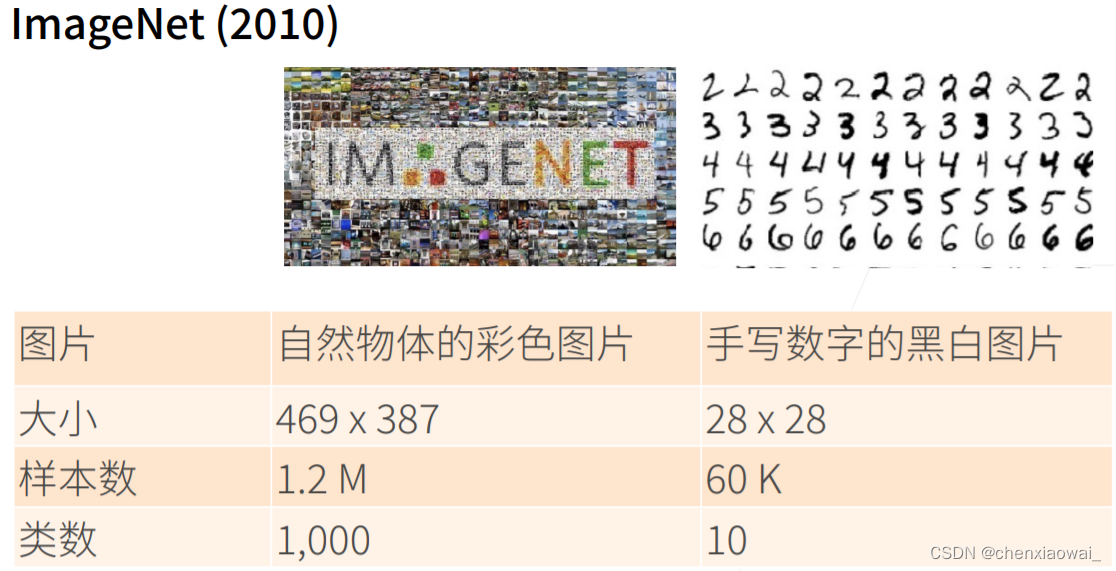
AlexNet vs LeNet

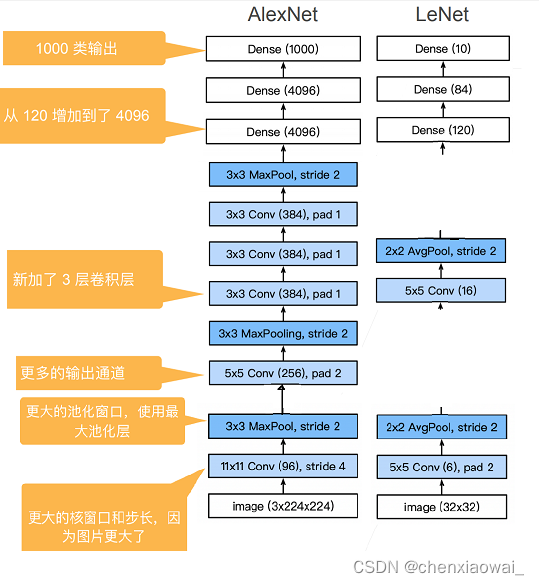
AlexNet

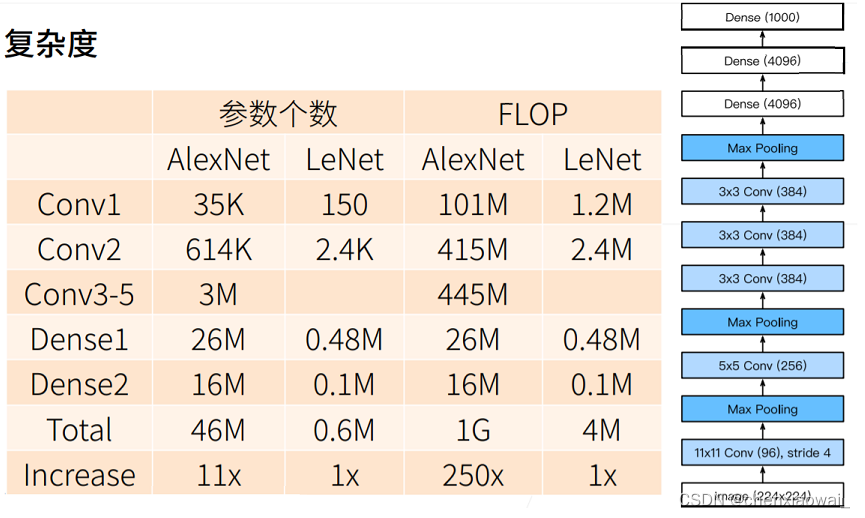
总结

本节代码文件在源代码文件的chapter_convolutional-modern/vgg.ipynb中
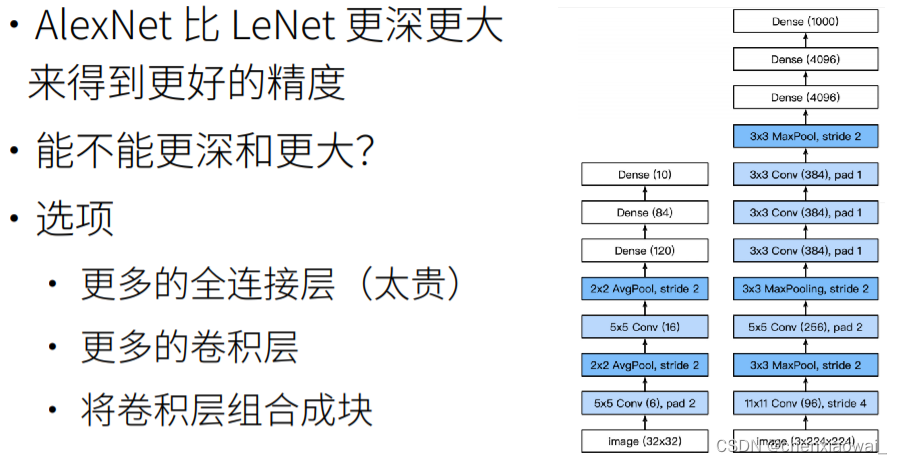
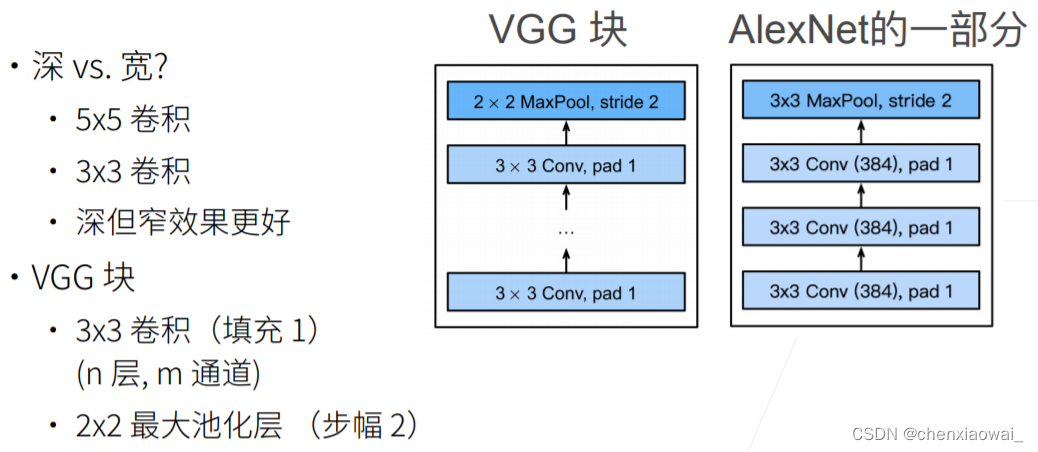
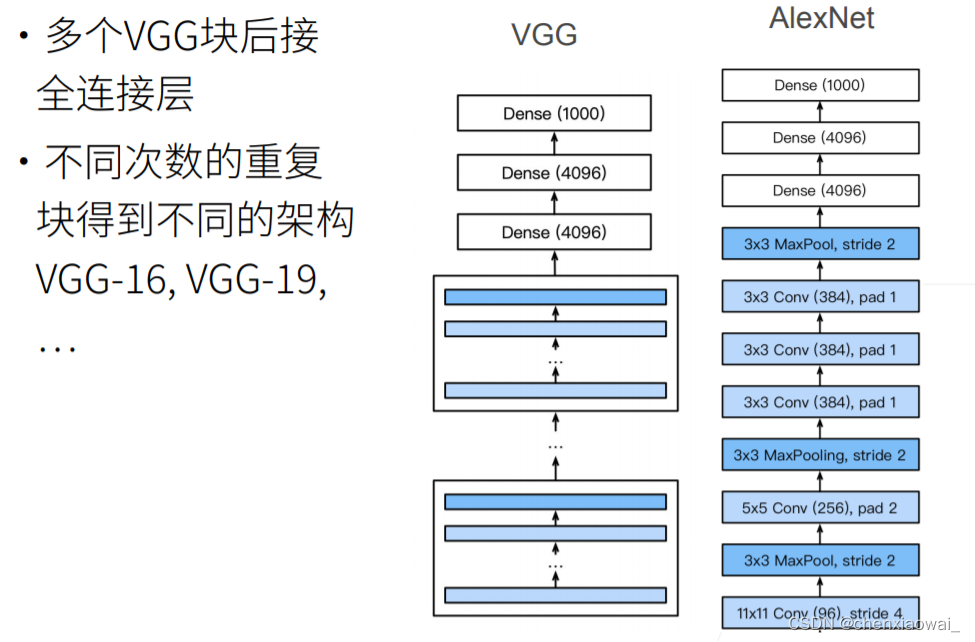
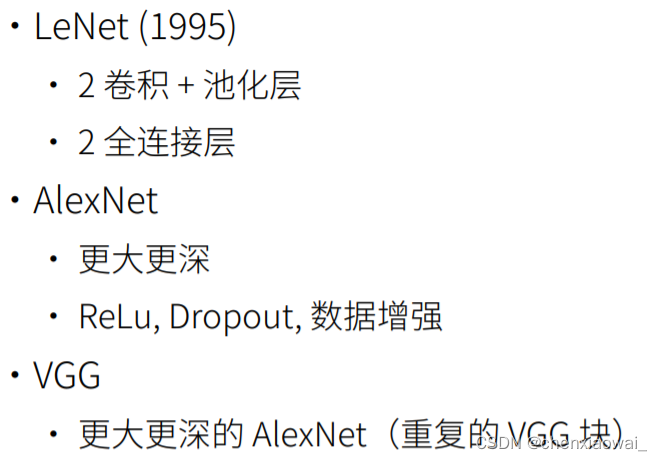
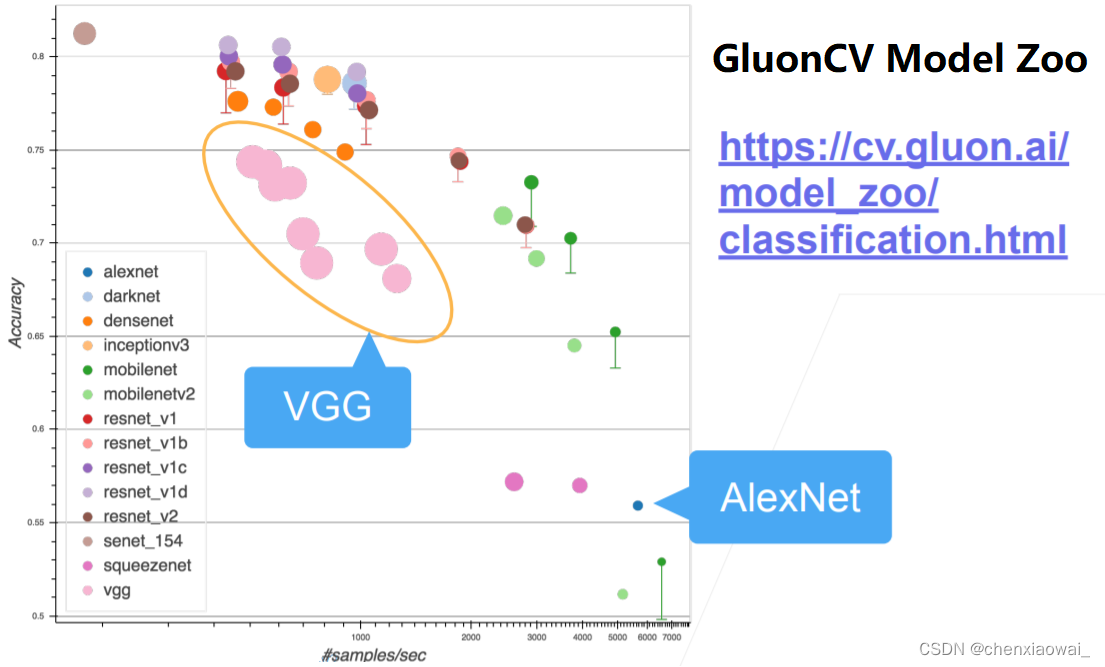

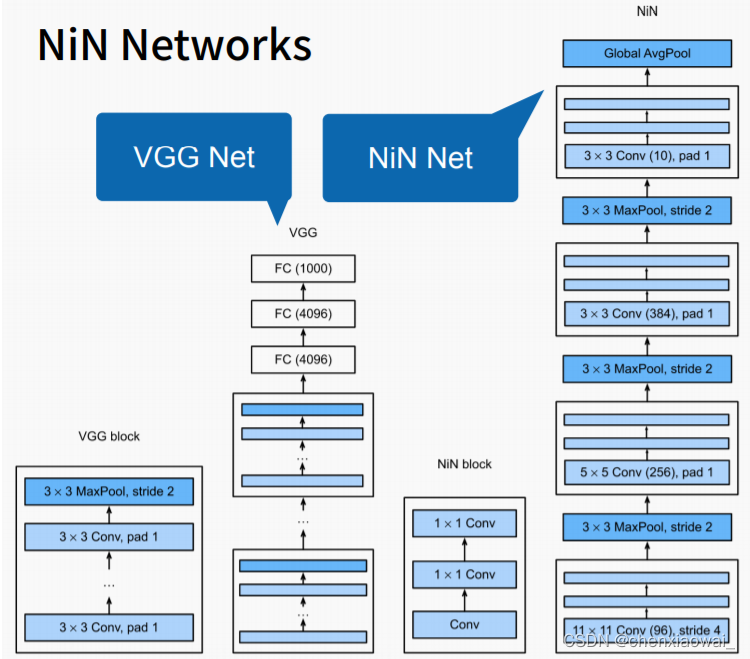
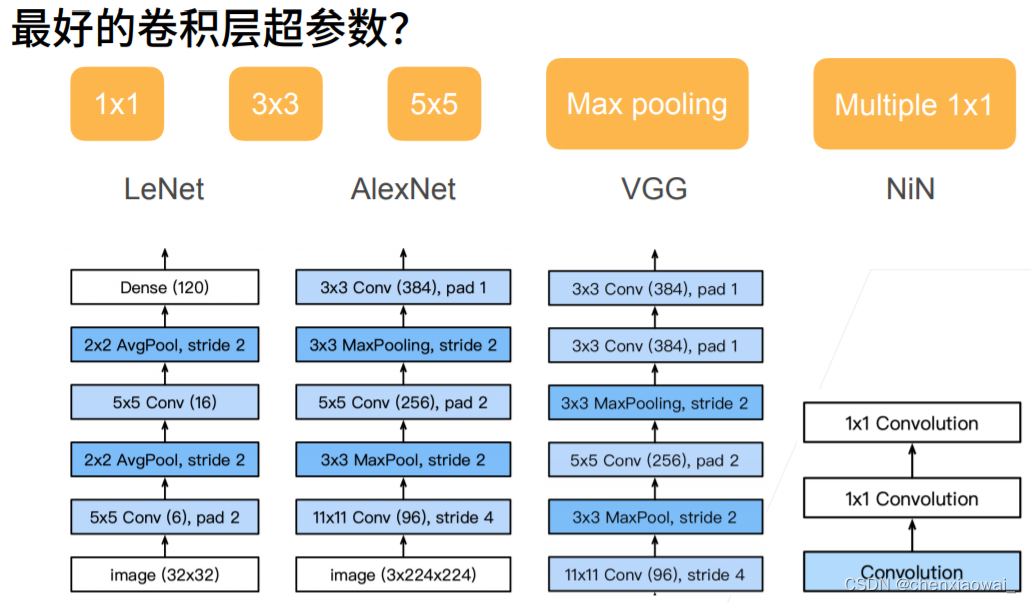
本节代码文件在源代码文件的chapter_convolutional-modern/nin.ipynb中

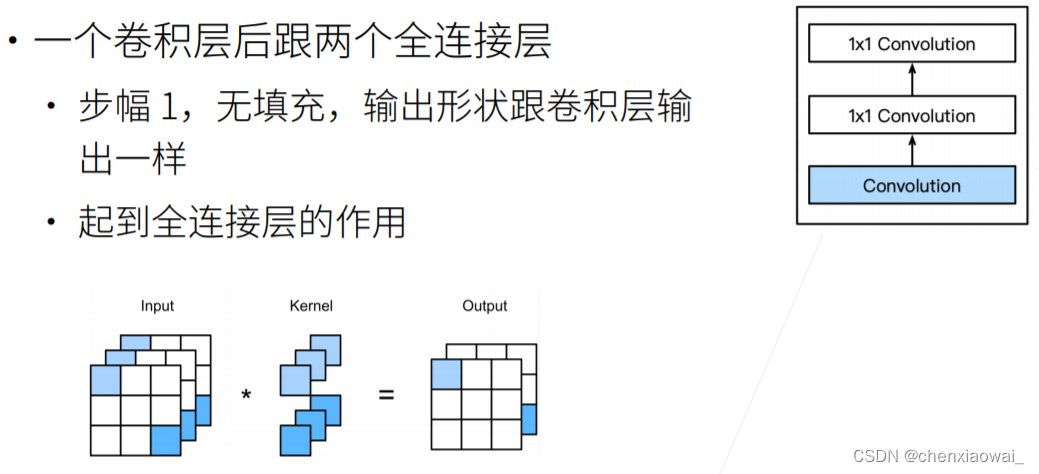

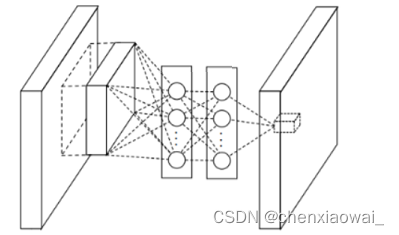

本节代码文件在源代码文件的chapter_convolutional-modern/googlenet.ipynb中
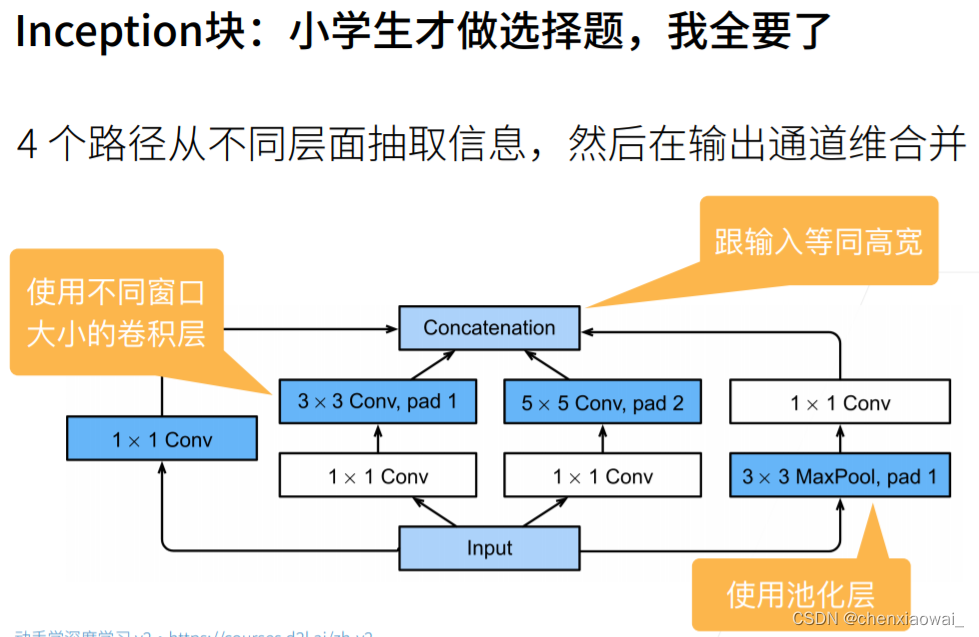
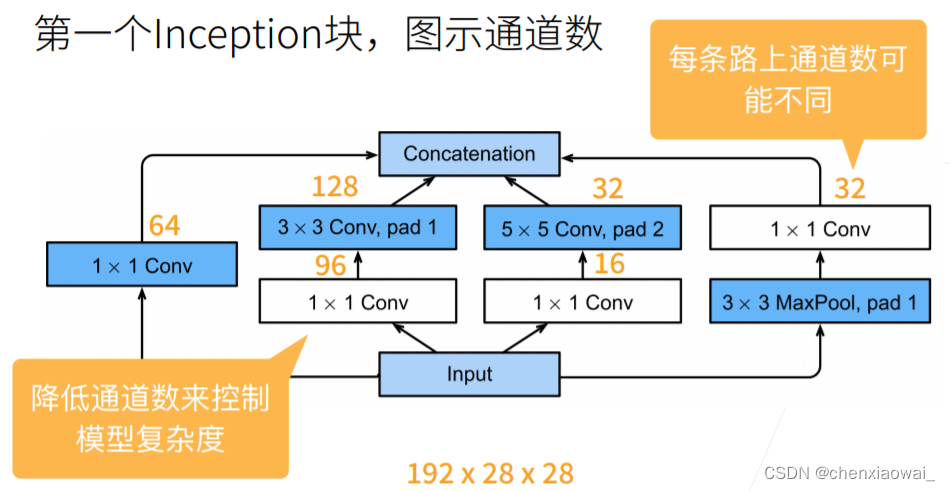
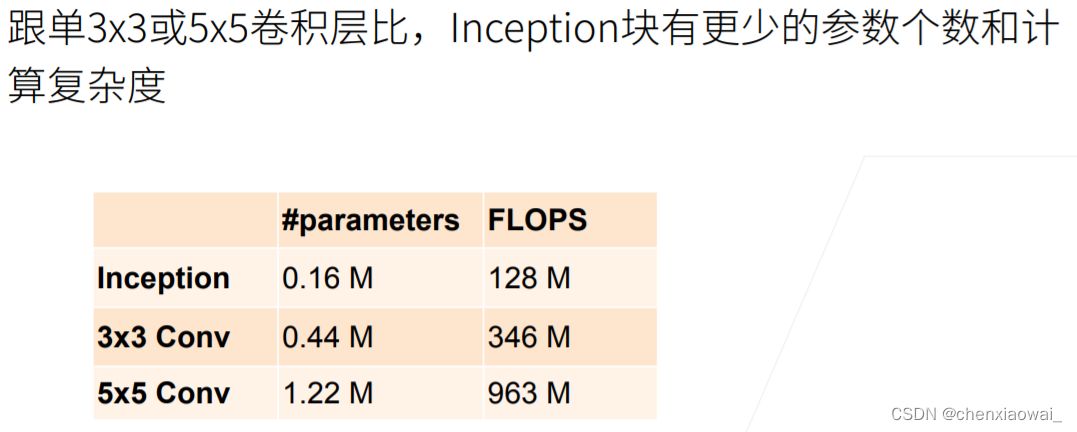
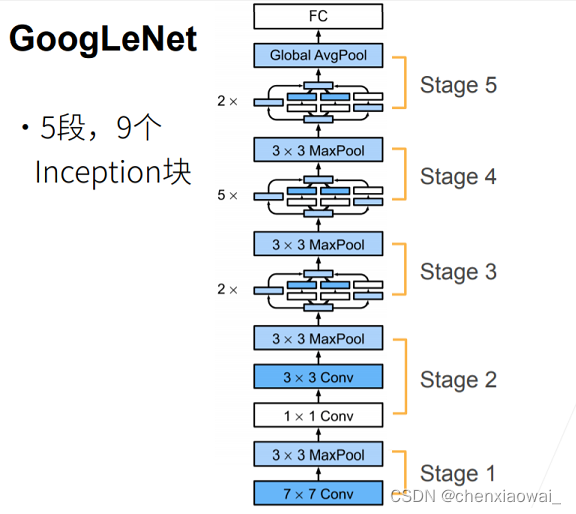
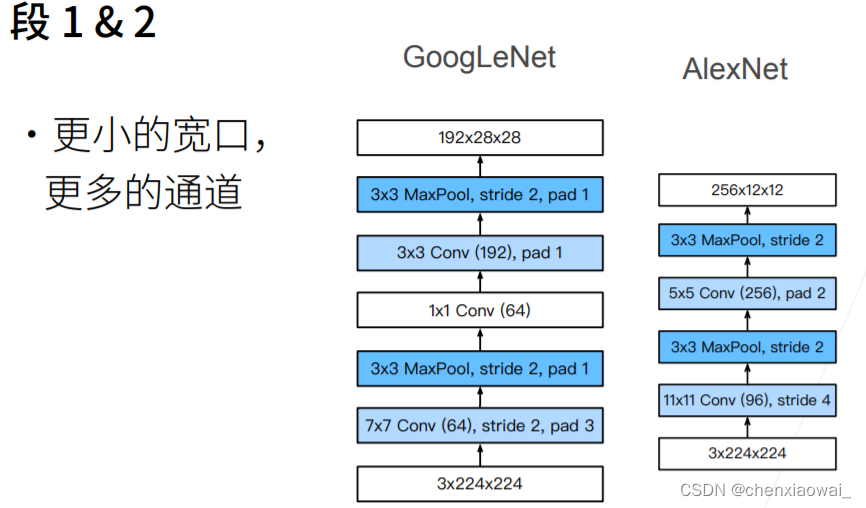
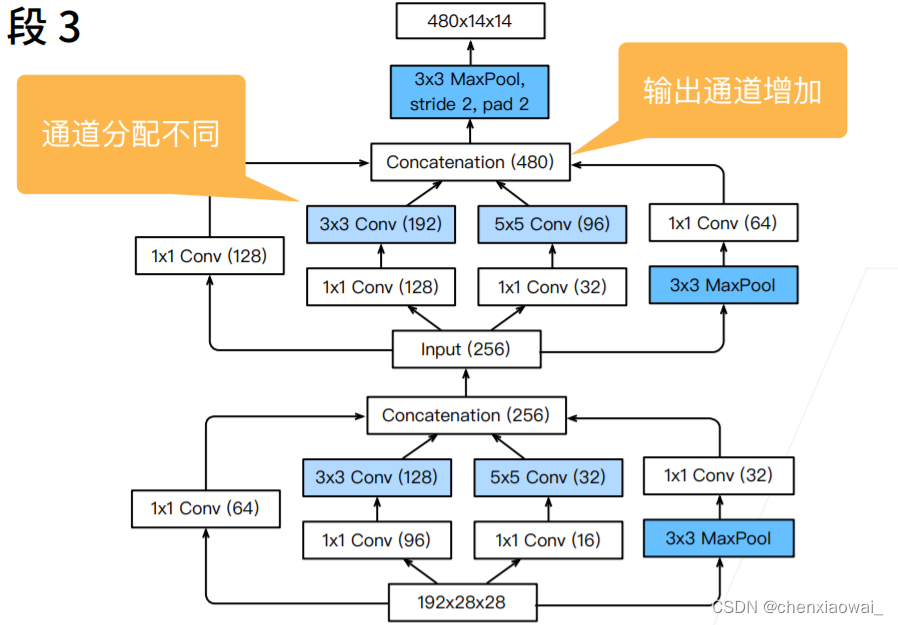
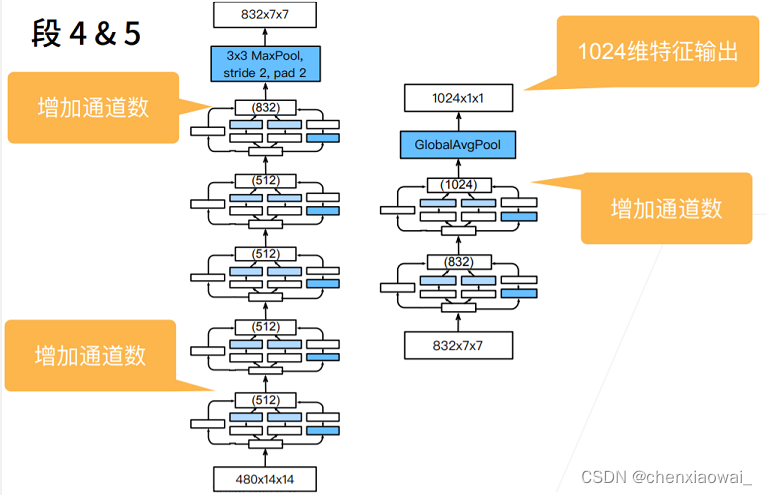

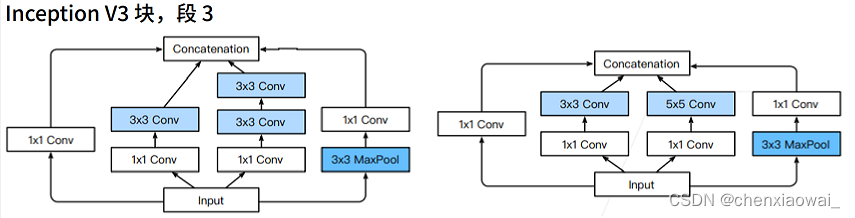
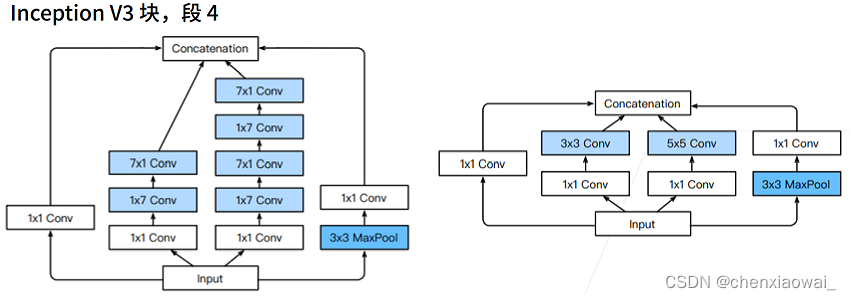
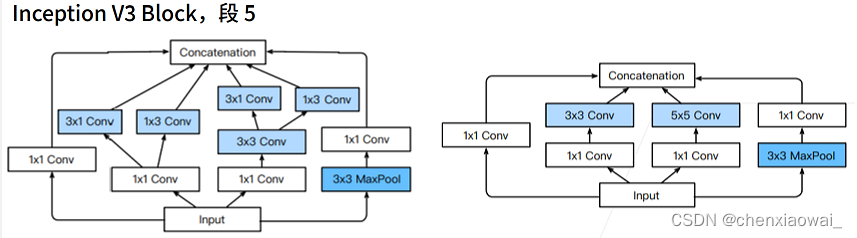

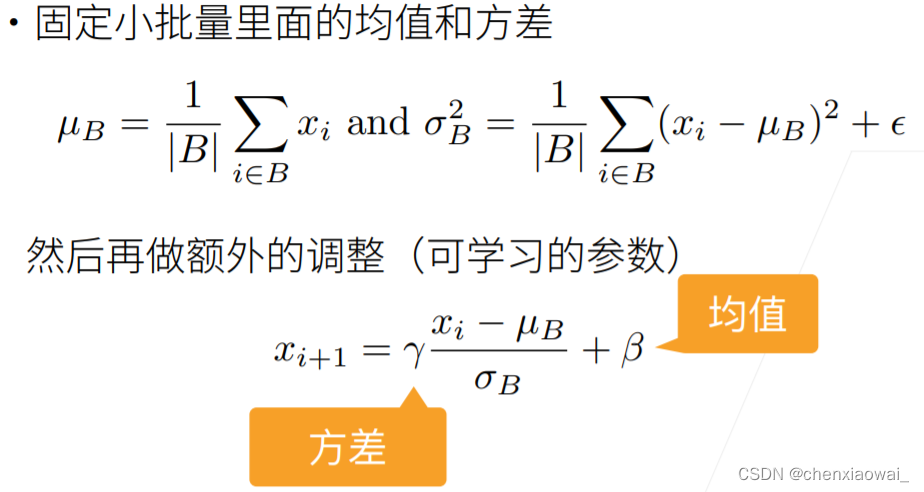
本节代码文件在源代码文件的chapter_convolutional-modern/batch-norm.ipynb中




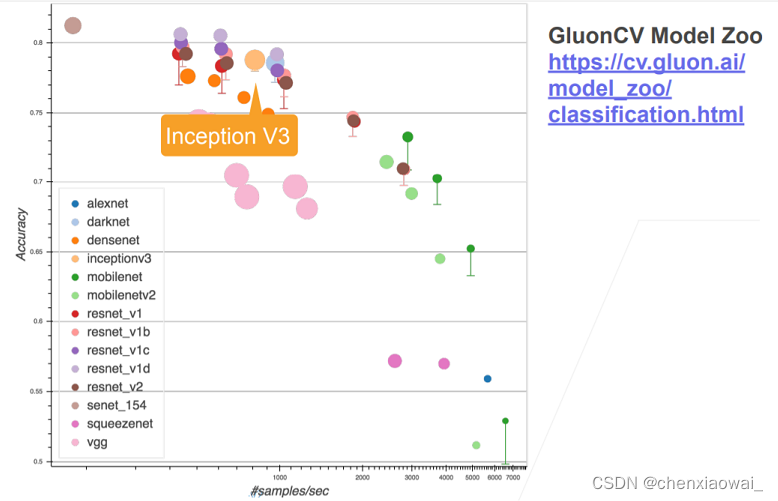
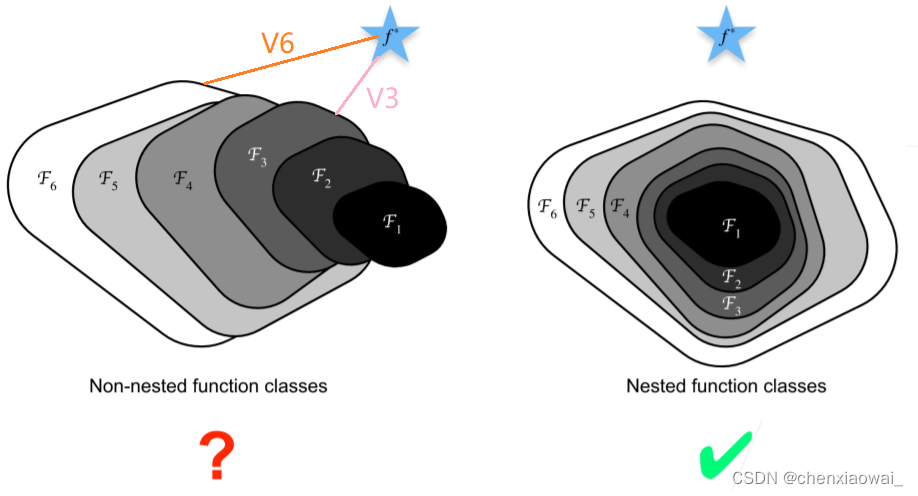
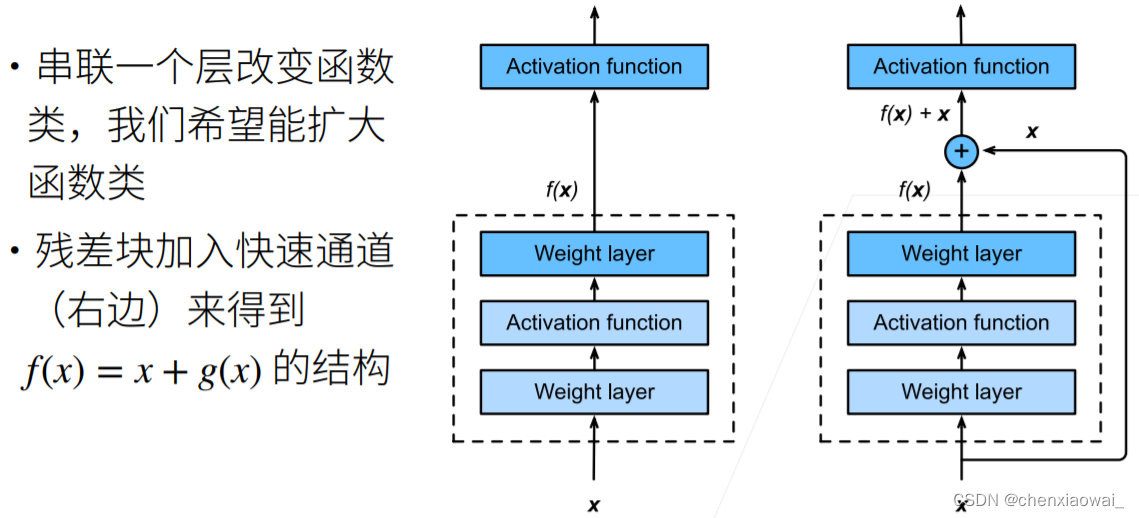
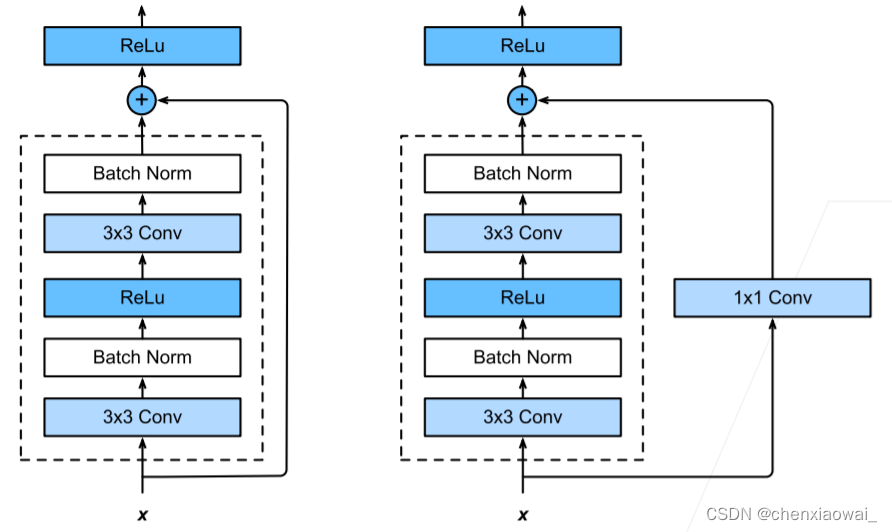
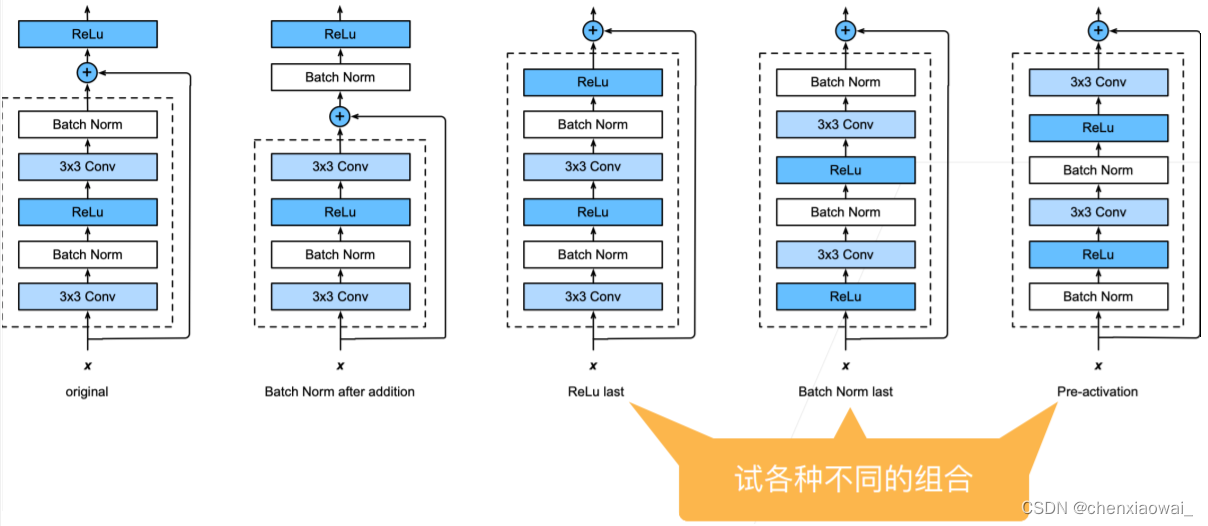
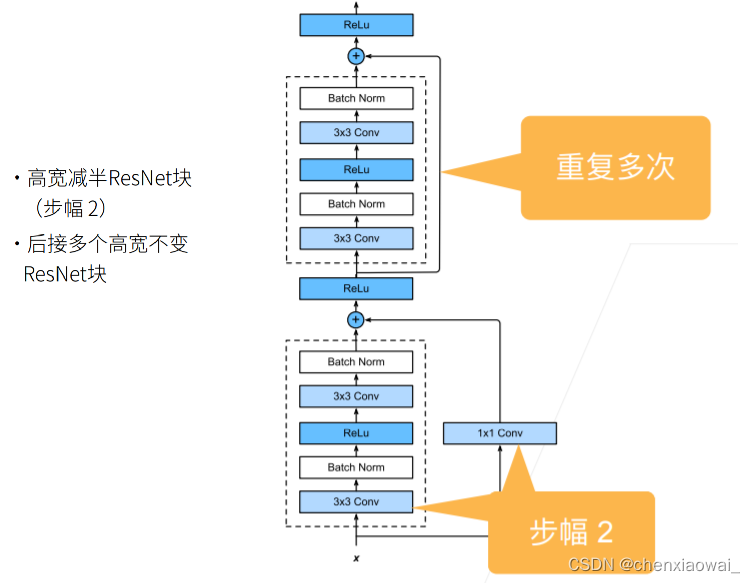
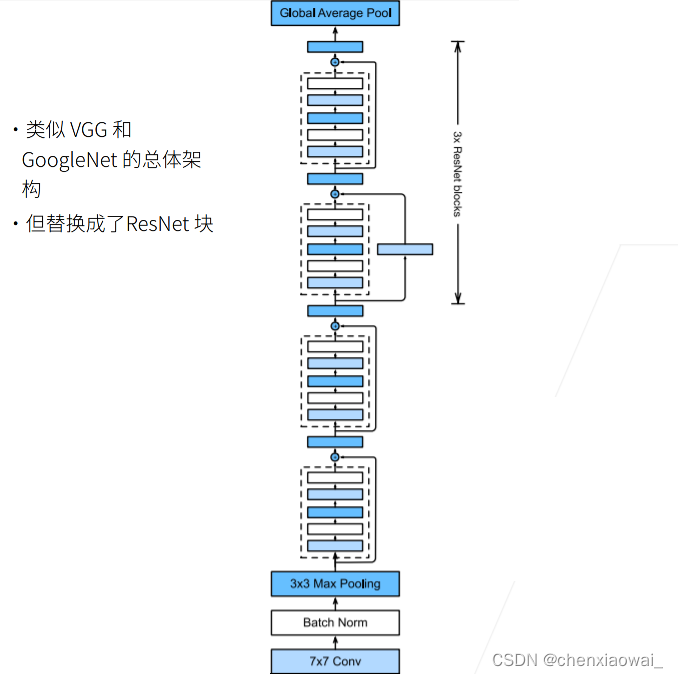
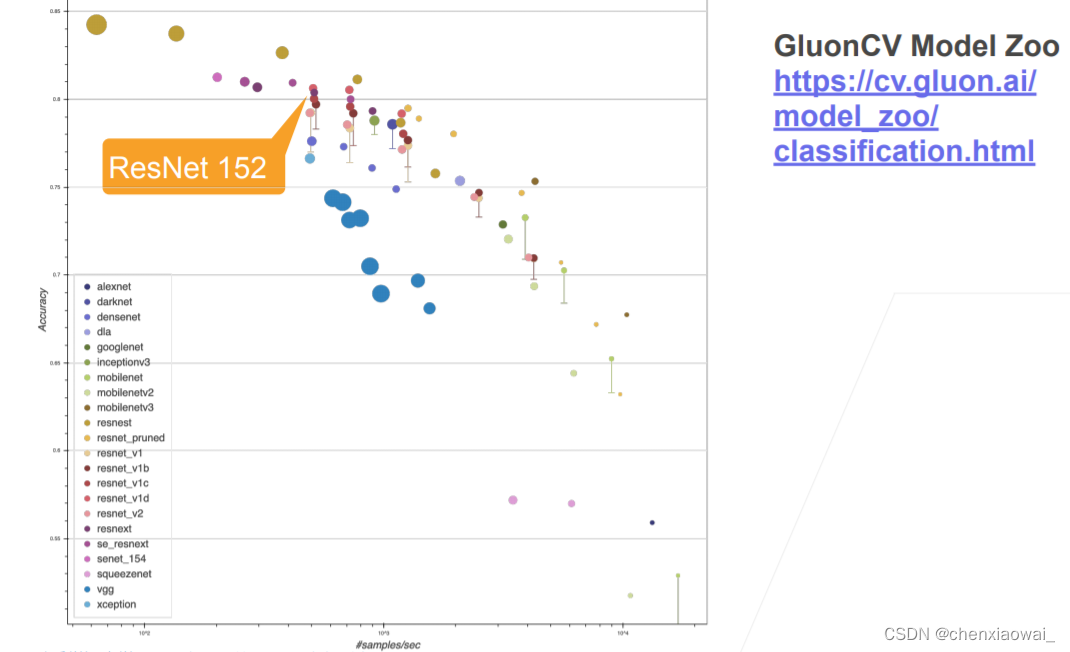
本节代码文件在源代码文件的chapter_convolutional-modern/resnet.ipynb中
















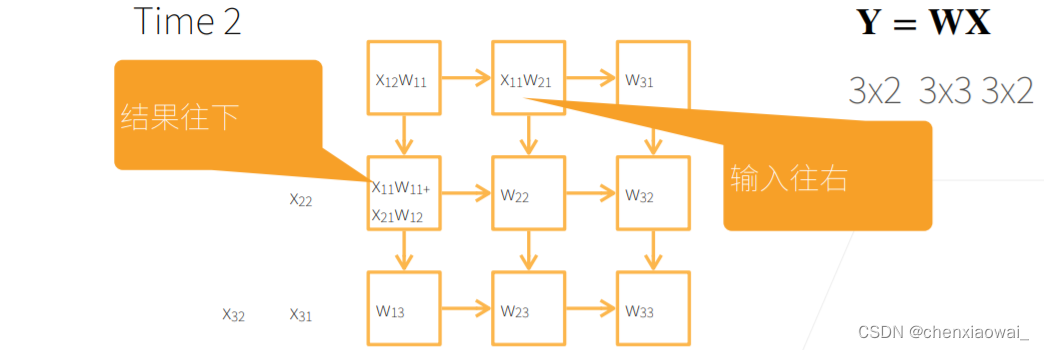
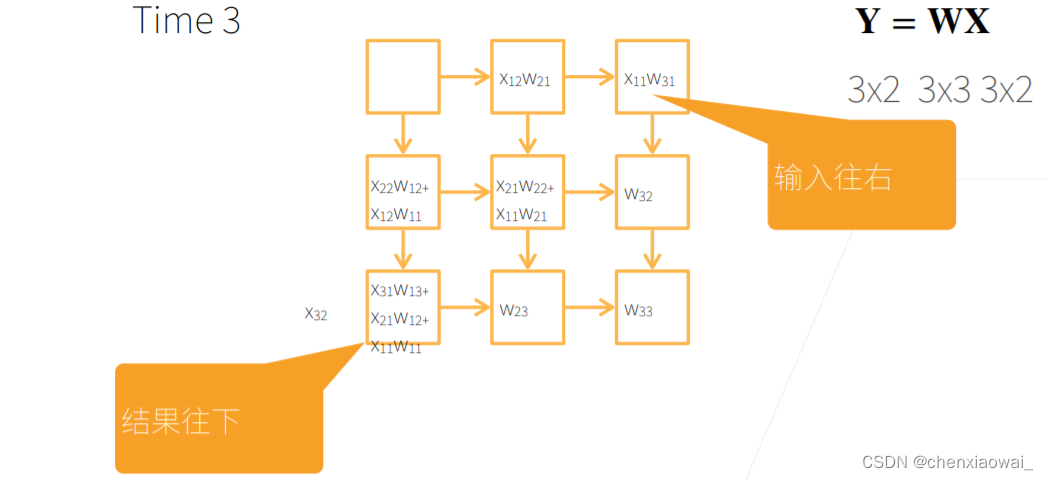
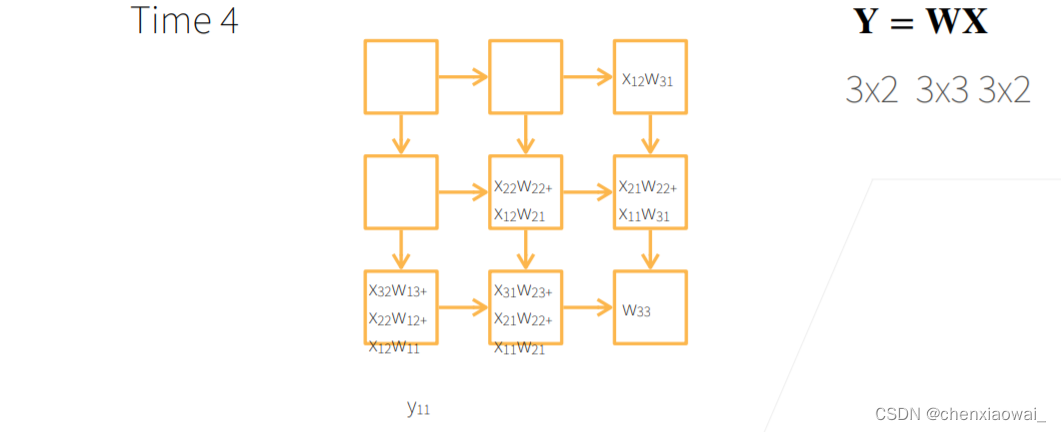
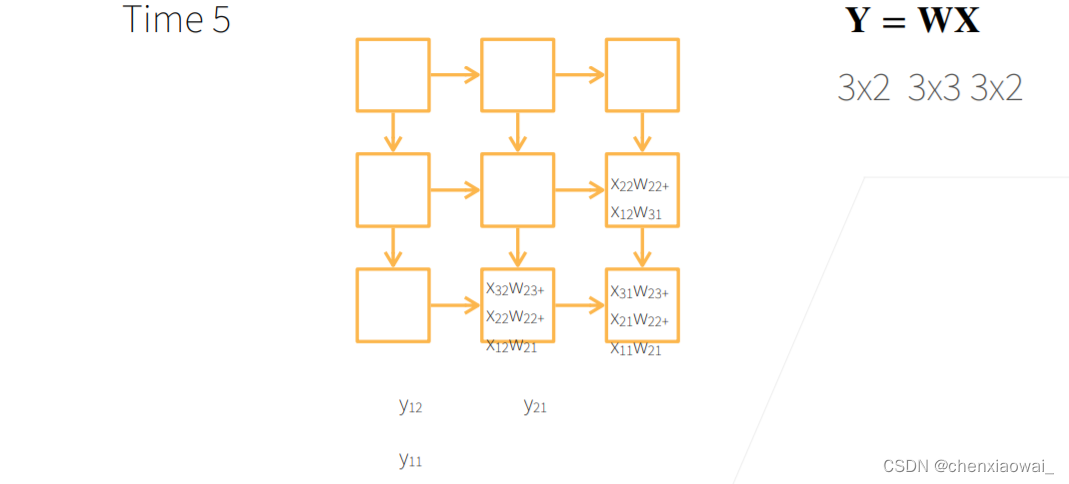








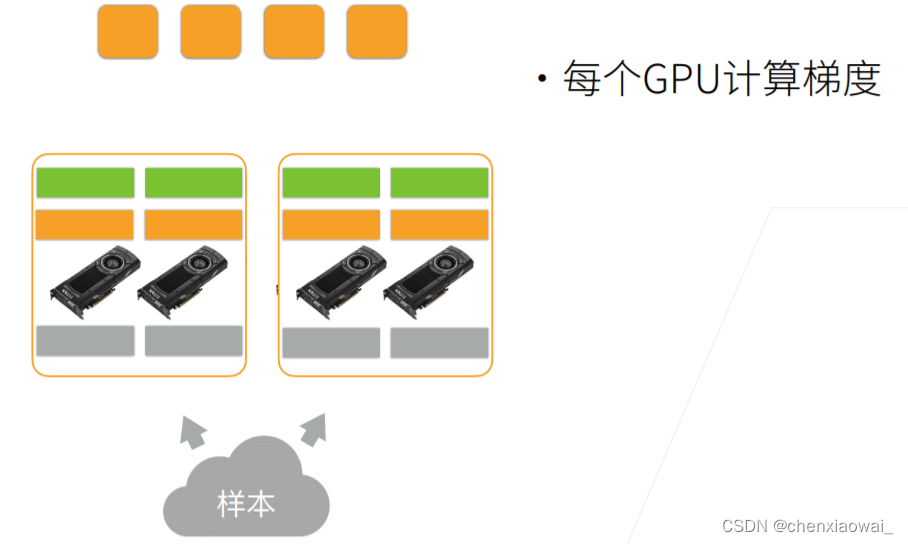
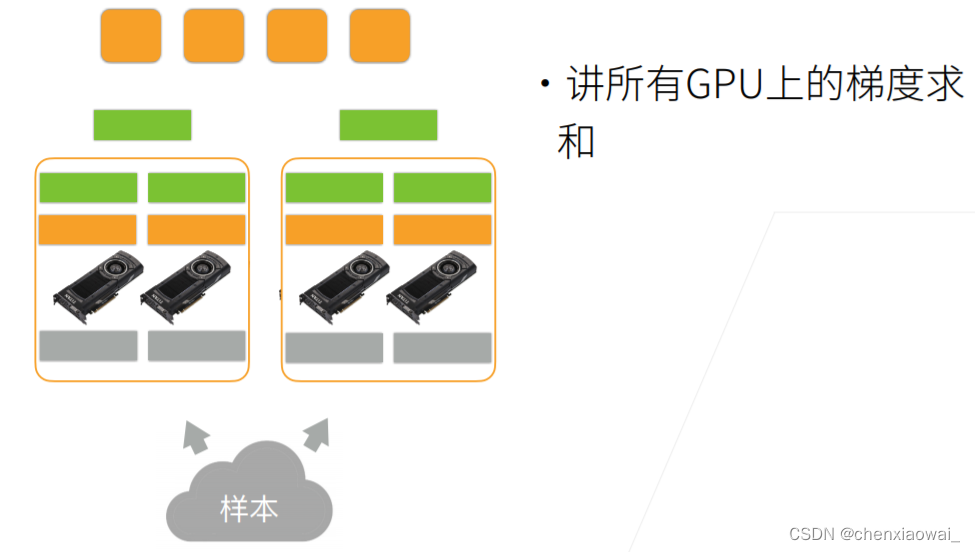
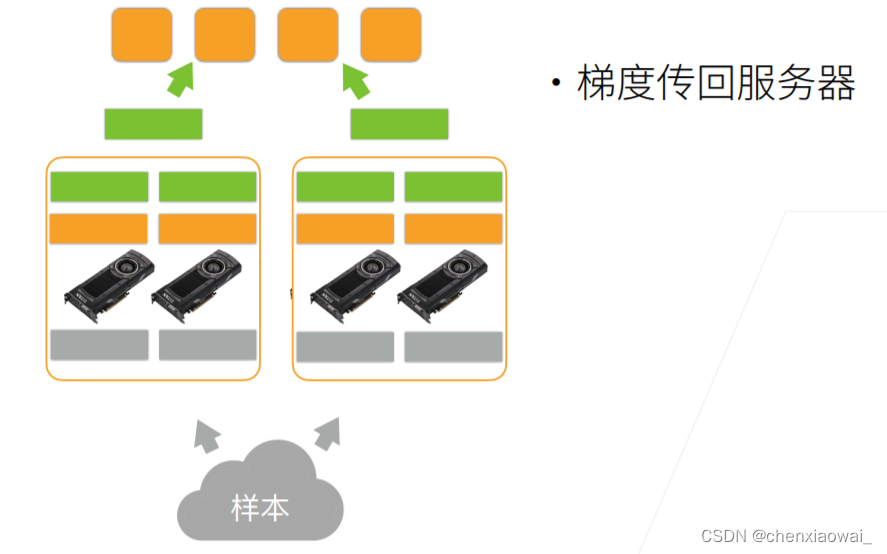
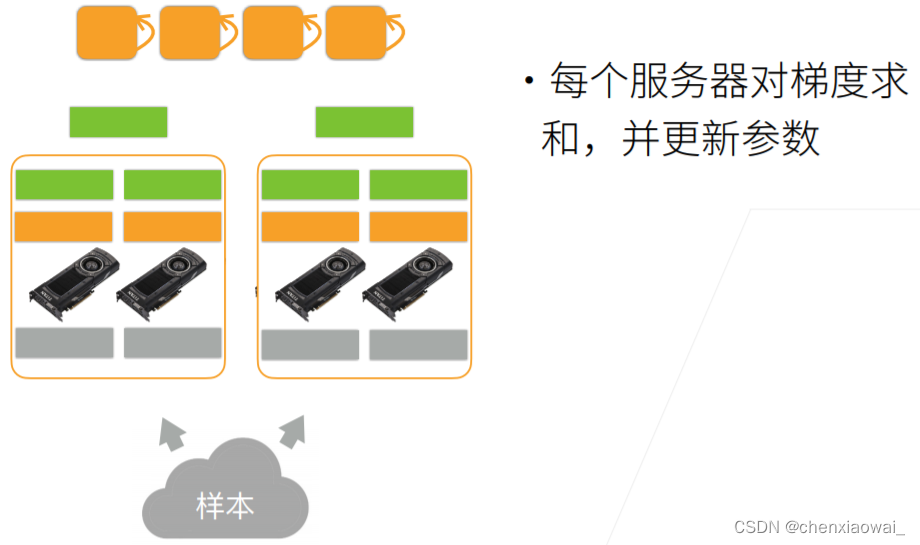


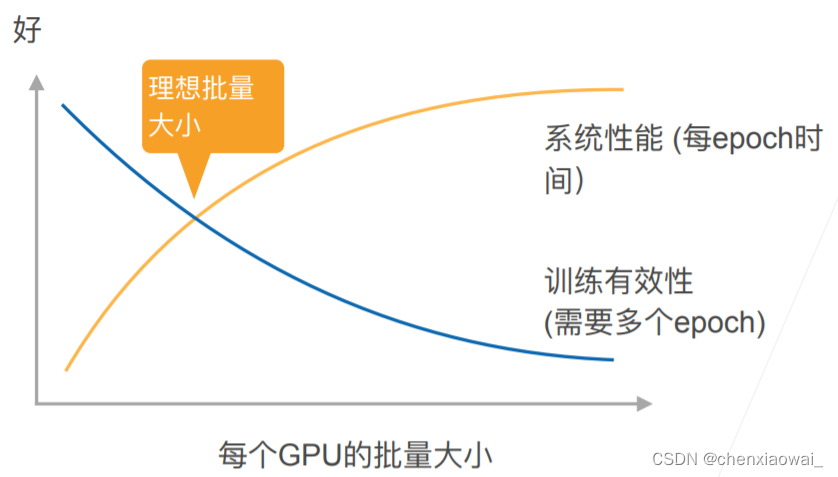


本节代码文件在源代码文件的chapter_computer-vision/image-augmentation.ipynb中
数据增广


数据增强

使用增强数据训练
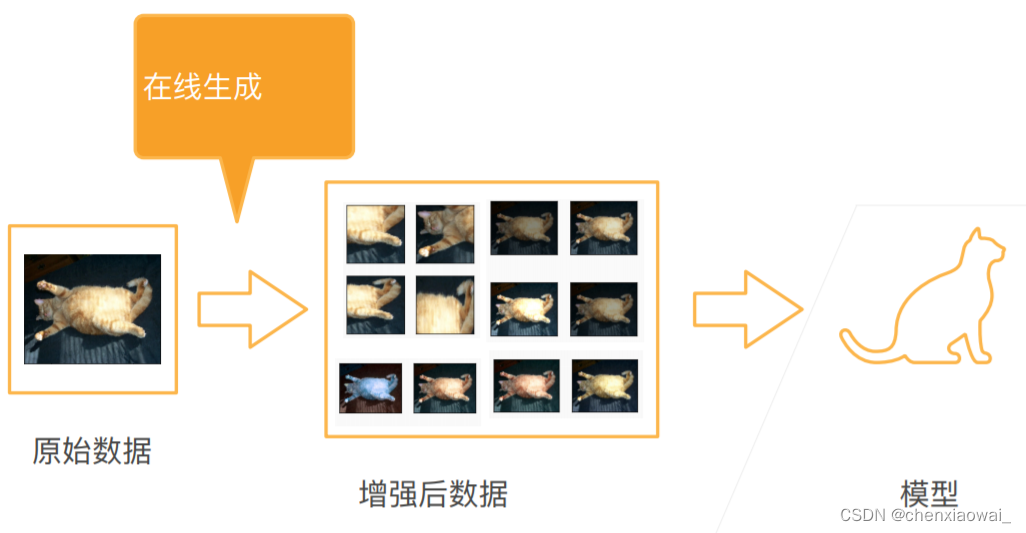
翻转

切割

颜色

几十种其他办法

总结

本节代码文件在源代码文件的chapter_computer-vision/fine-tuning.ipynb中
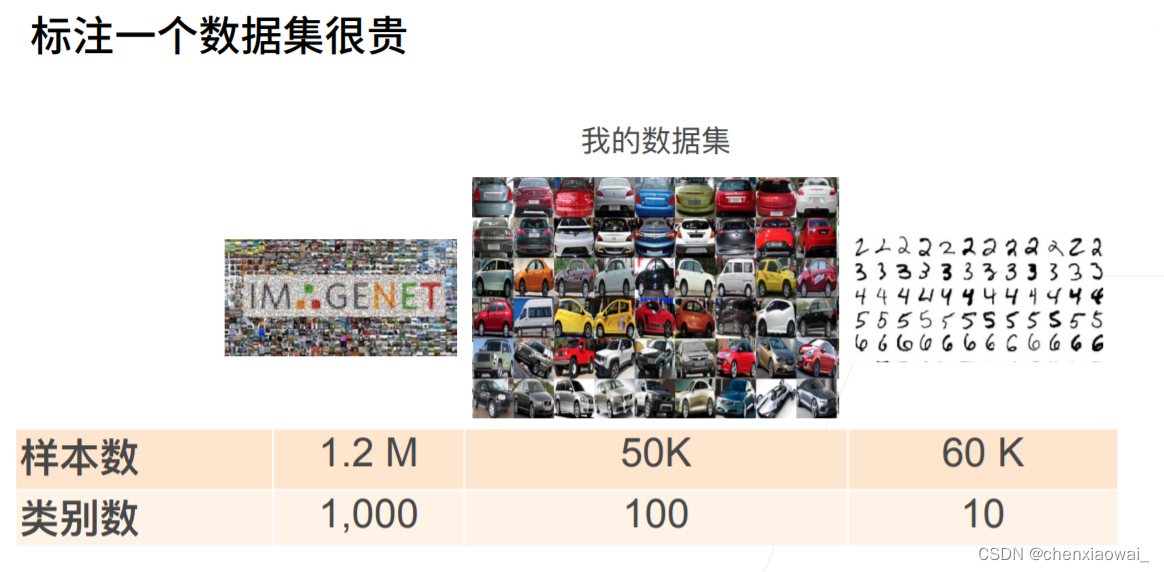
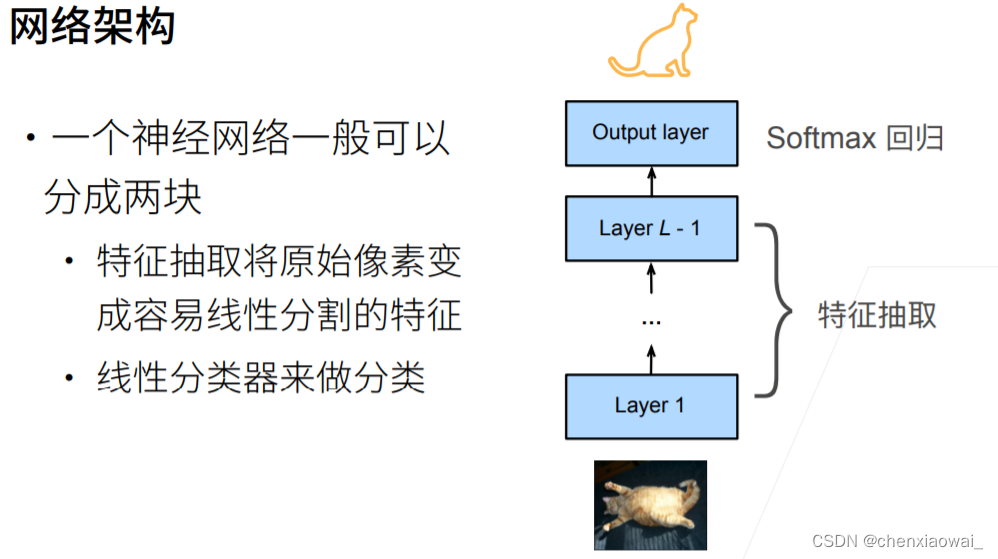
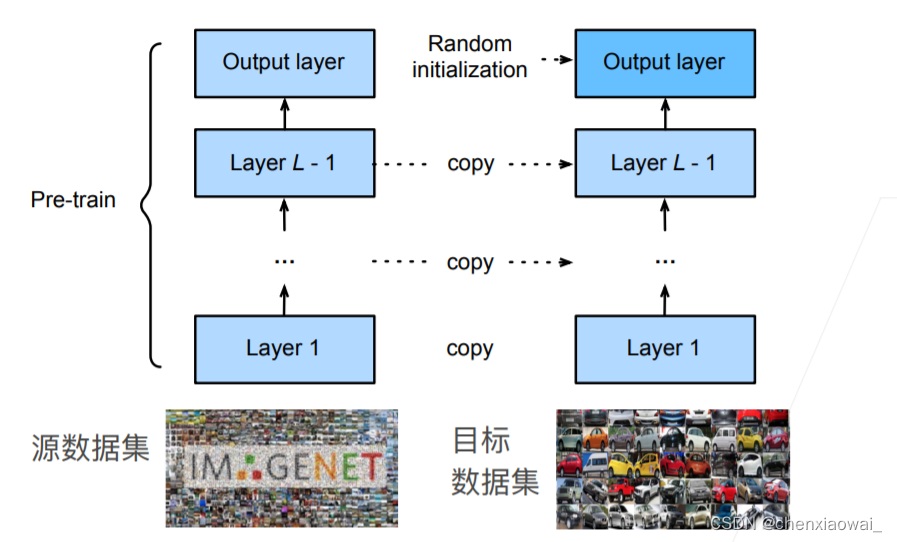




本节代码文件在源代码文件的chapter_computer-vision/bounding-box.ipynb中
图片分类与目标检测的区别
目标检测更加复杂,需要进行多个物体的识别,还要找出每个物体的位置。目标检测的应用场景也更多。
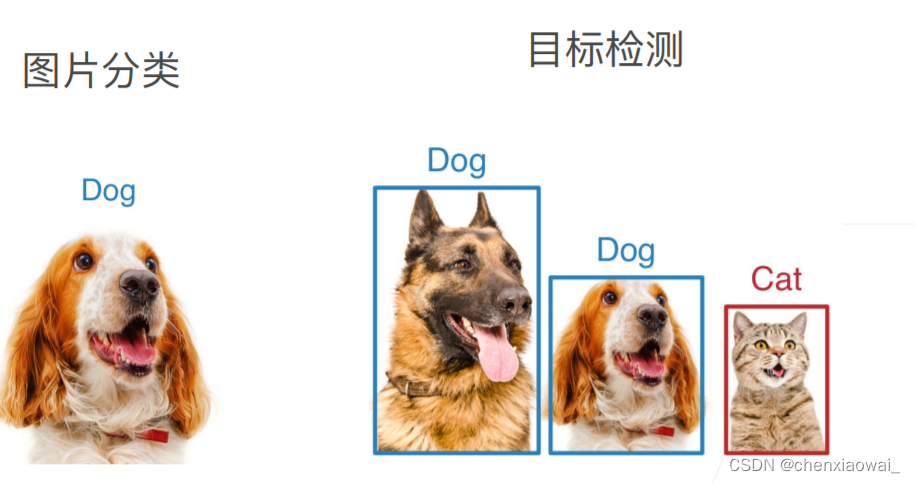
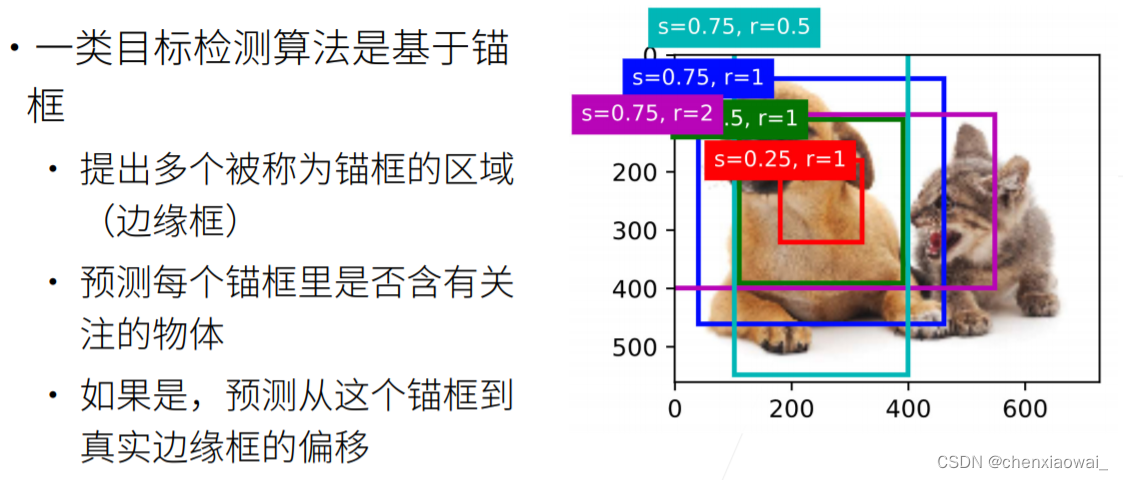
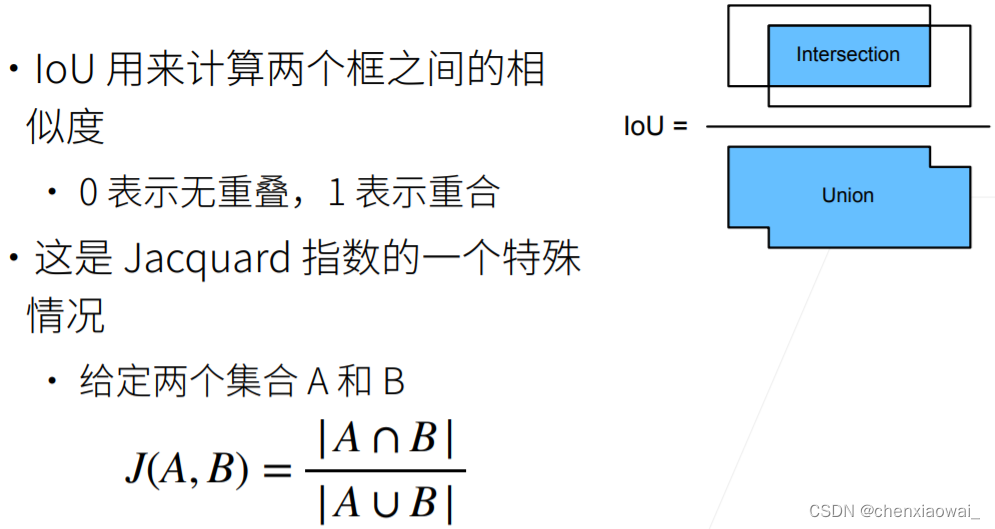
边缘框
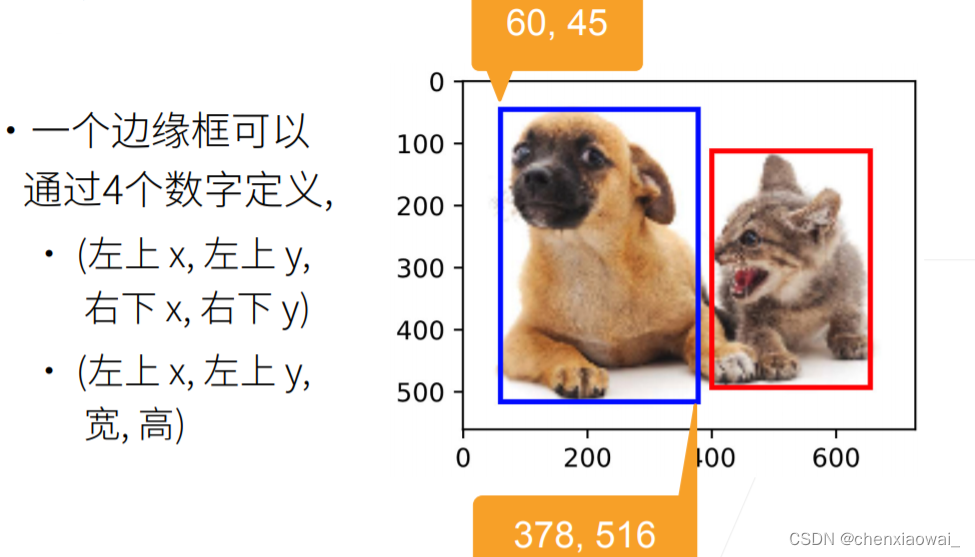
目标检测数据集

总结

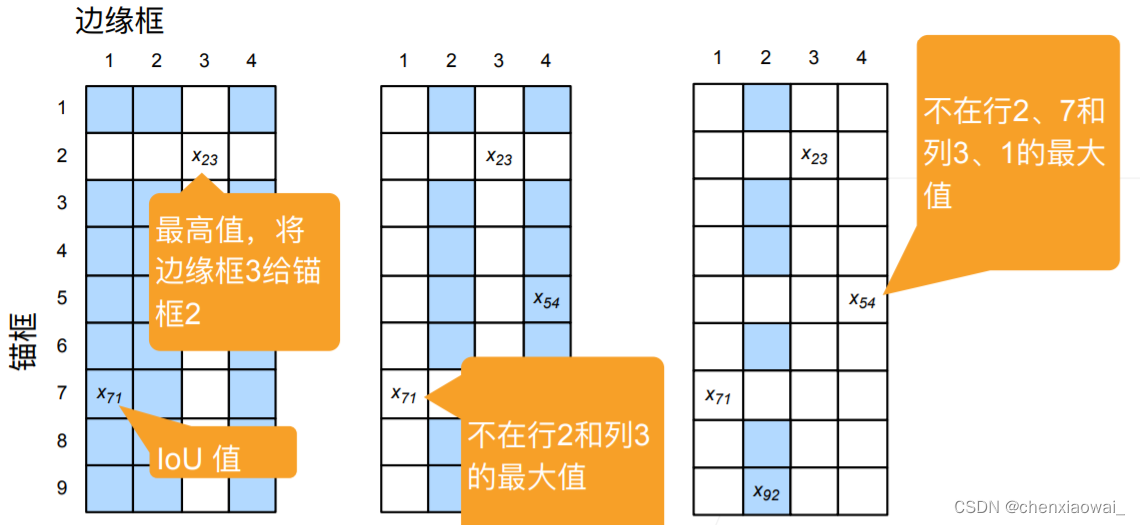
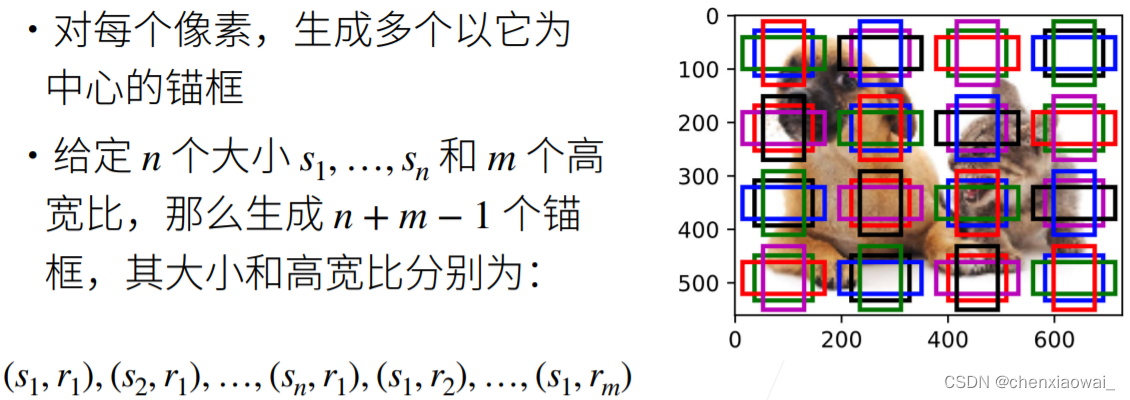
本节代码文件在源代码文件的chapter_computer-vision/anchor.ipynb中



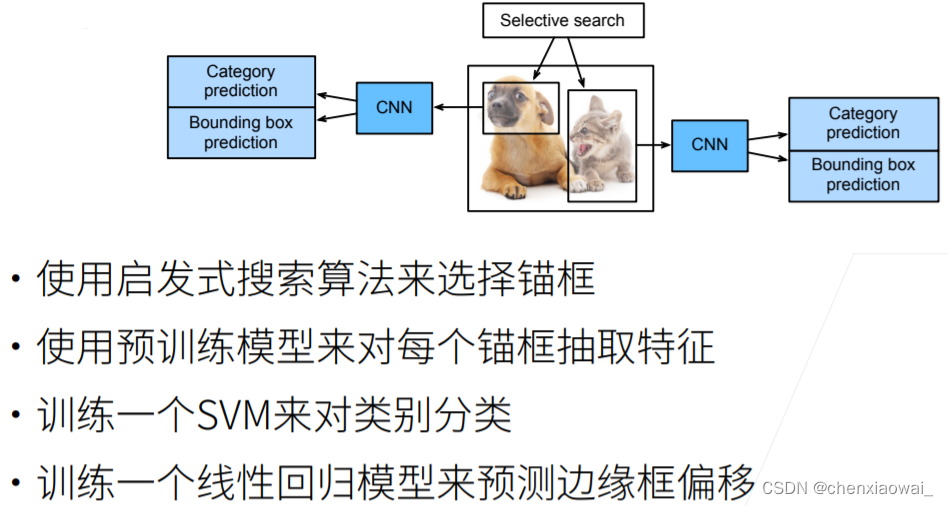
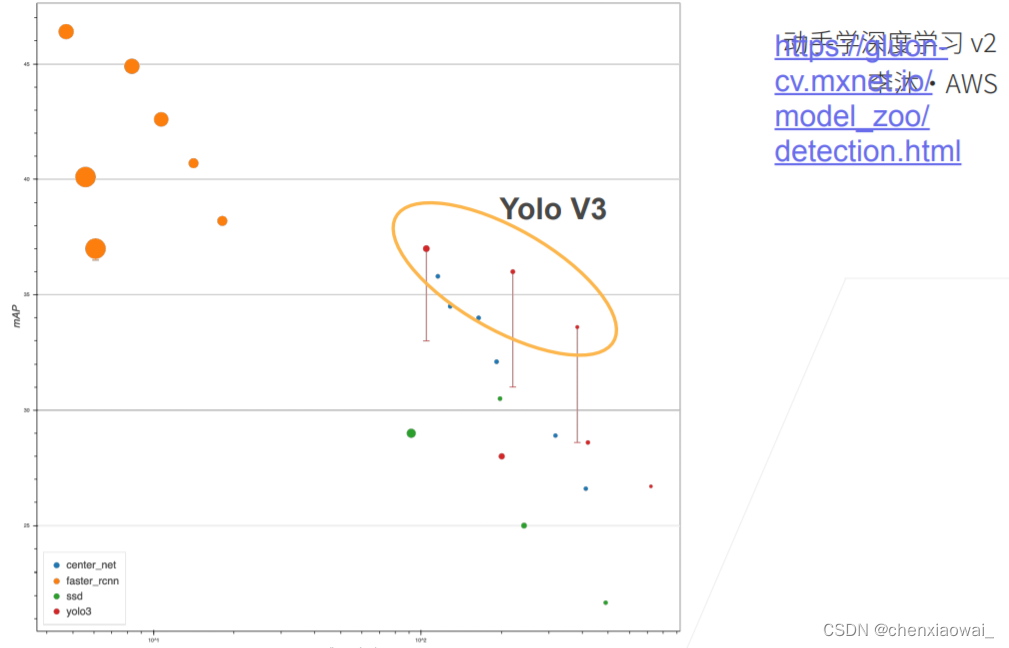
本节代码文件在源代码文件的chapter_computer-vision/rcnn.ipynb中
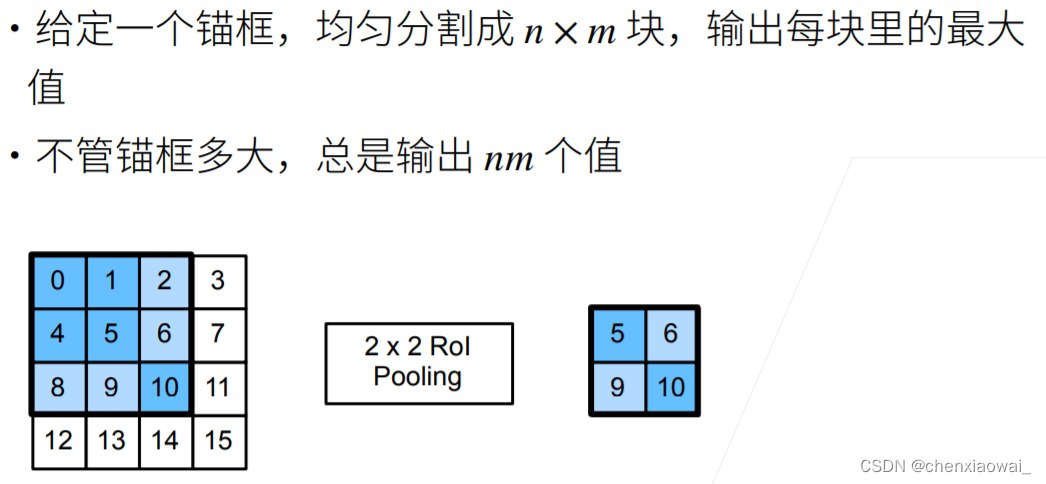
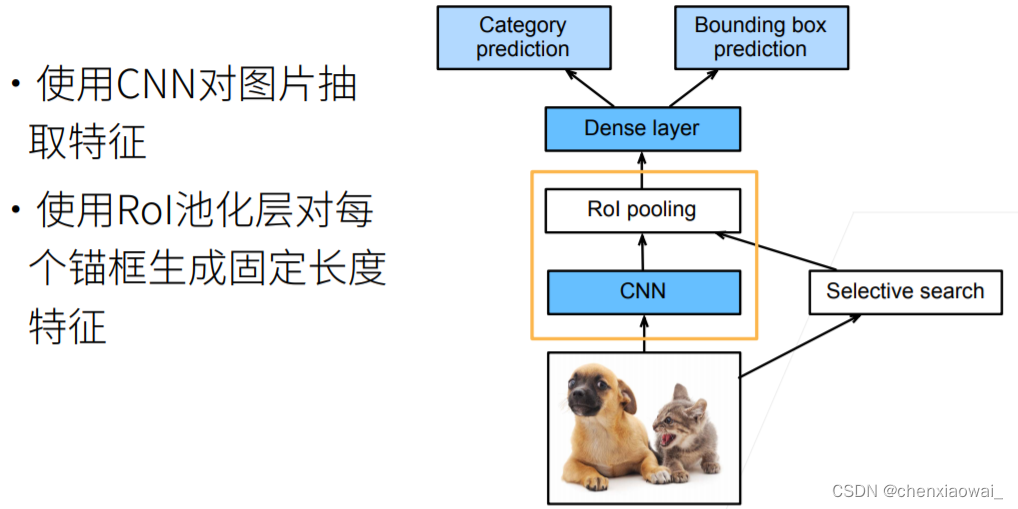
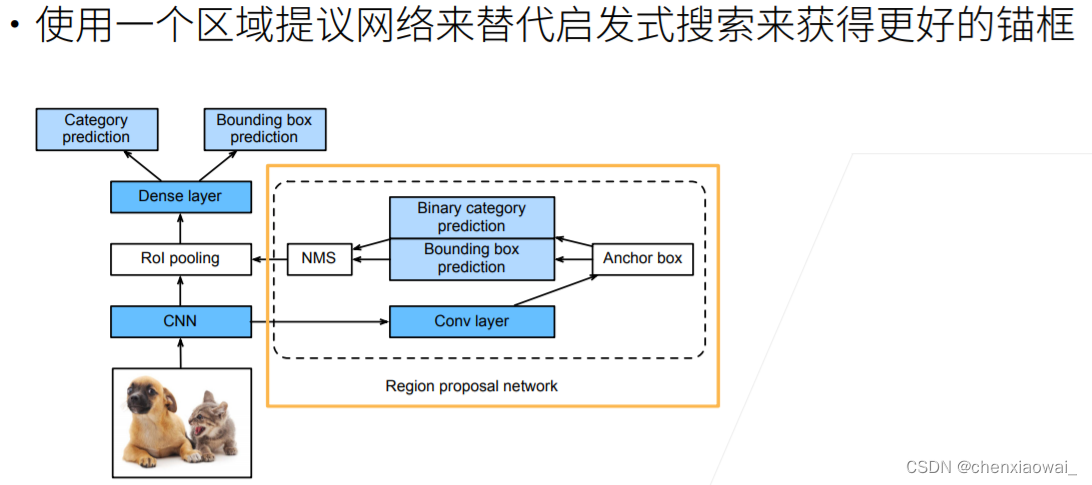
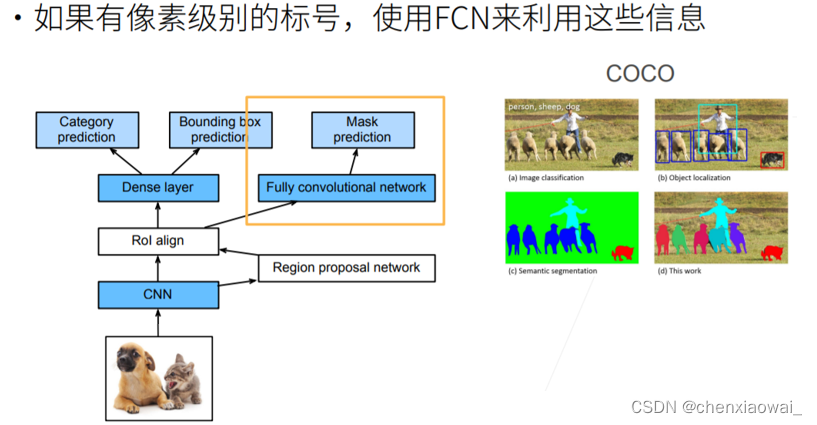
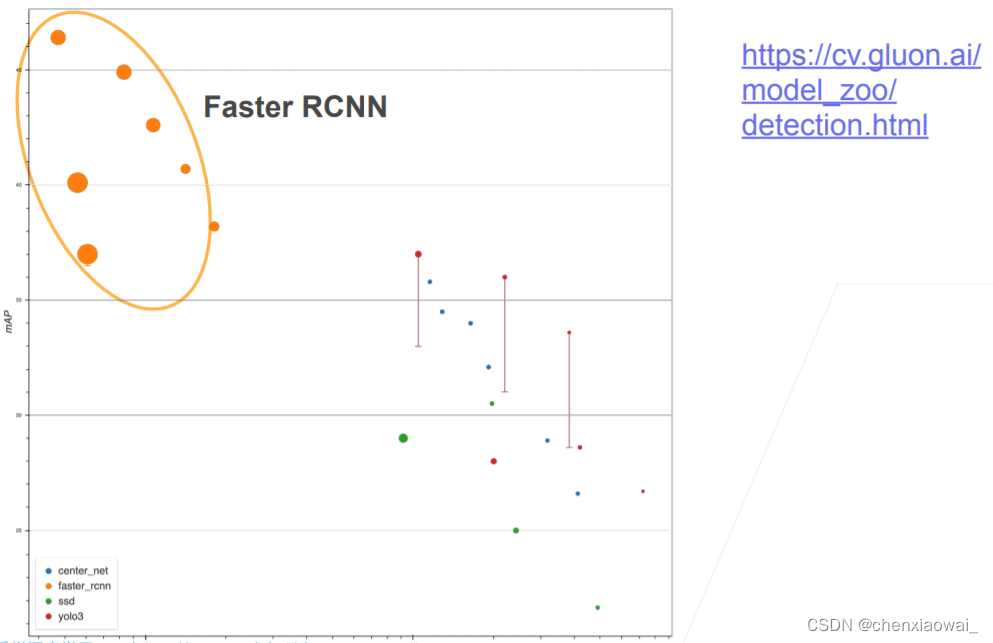

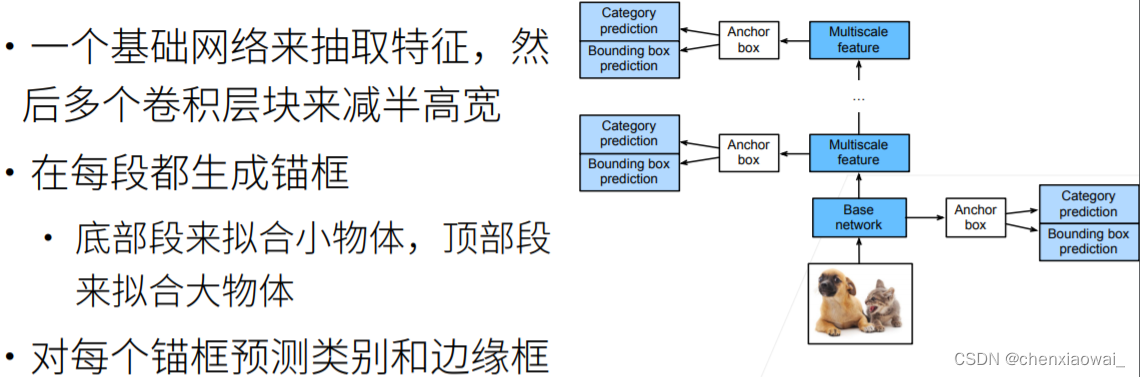
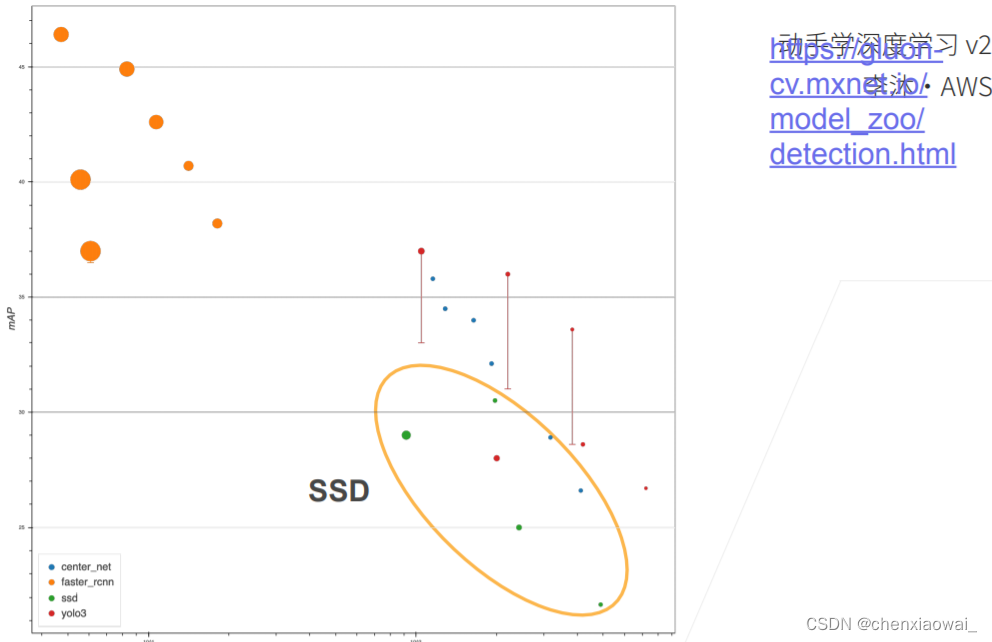
本节代码文件在源代码文件的chapter_computer-vision/ssd.ipynb中


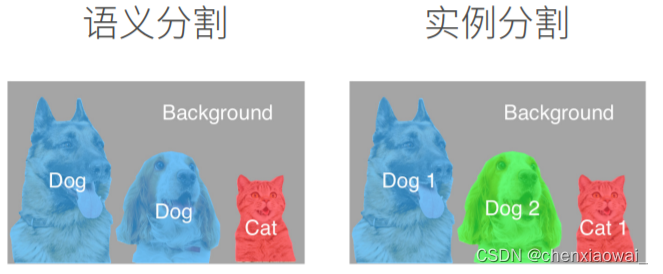
本节代码文件在源代码文件的chapter_computer-vision/semantic-segmentation-and-dataset.ipynb中



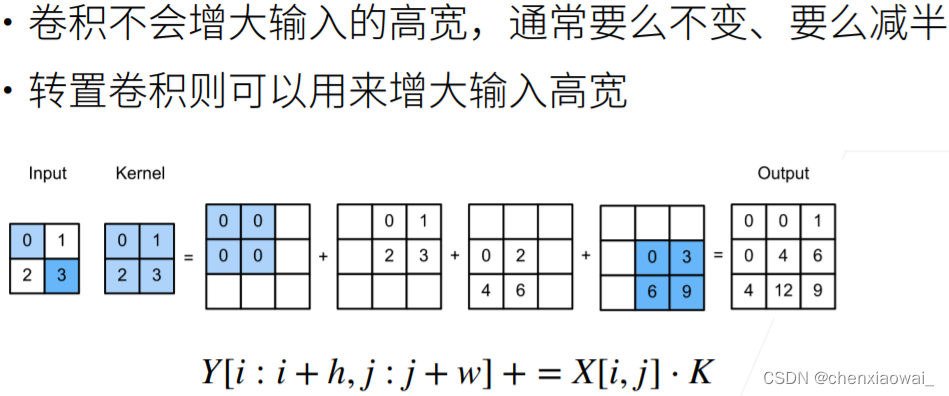
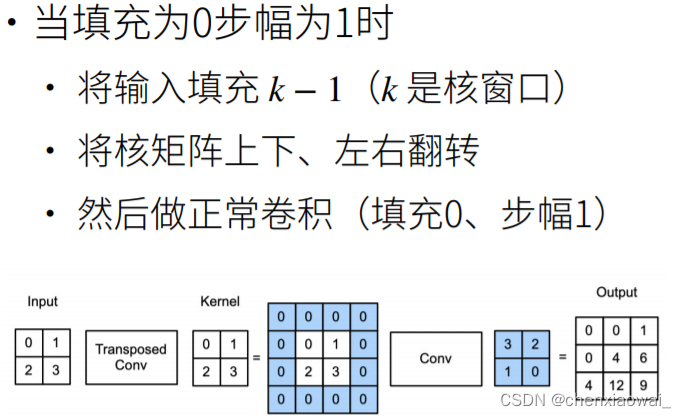
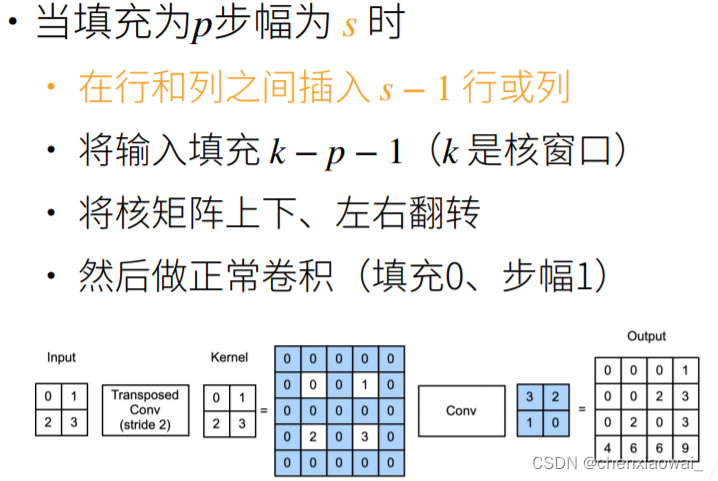
本节代码文件在源代码文件的chapter_computer-vision/transposed-conv.ipynb中






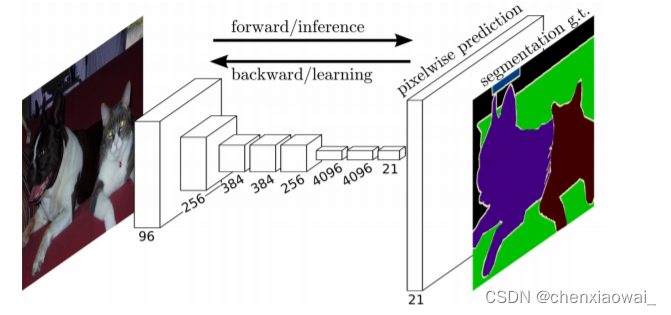
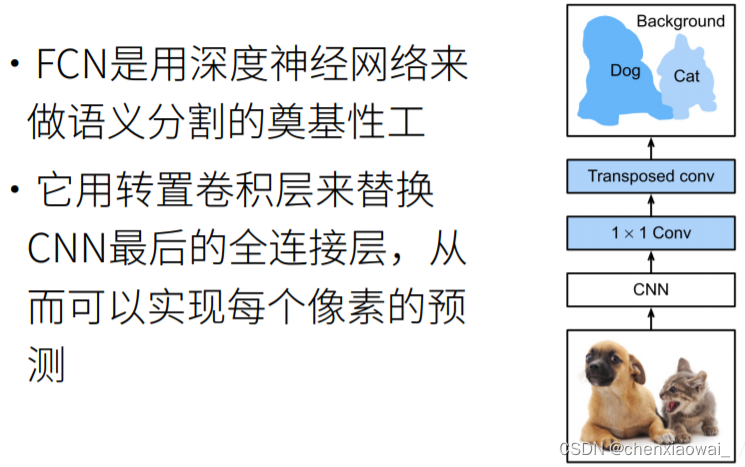
本节代码文件在源代码文件的chapter_computer-vision/fcn.ipynb中
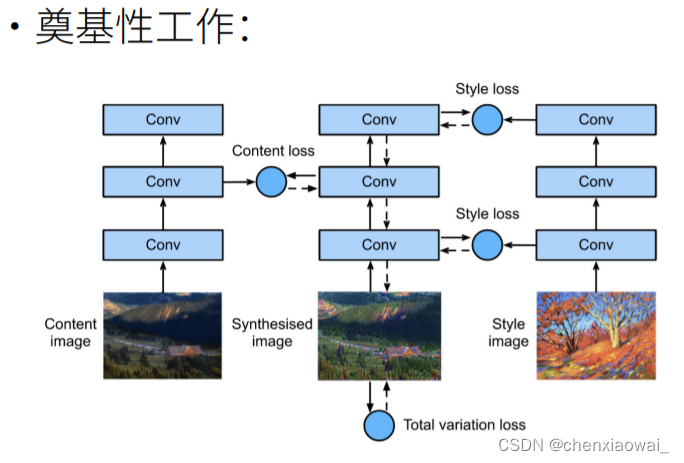
本节代码文件在源代码文件的chapter_computer-vision/neural-style.ipynb中


本节代码文件在源代码文件的chapter_recurrent-neural-networks/sequence.ipynb中



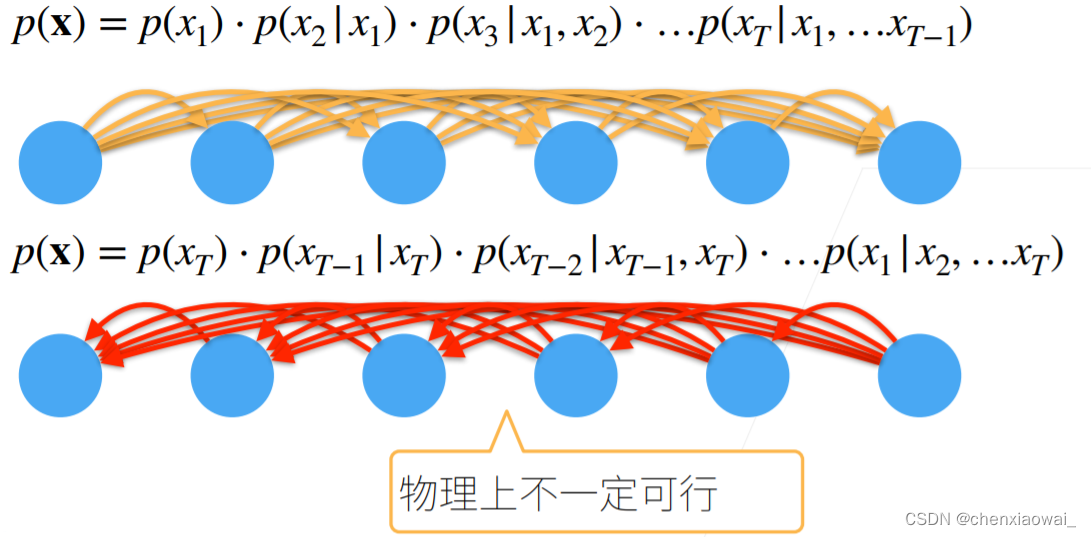


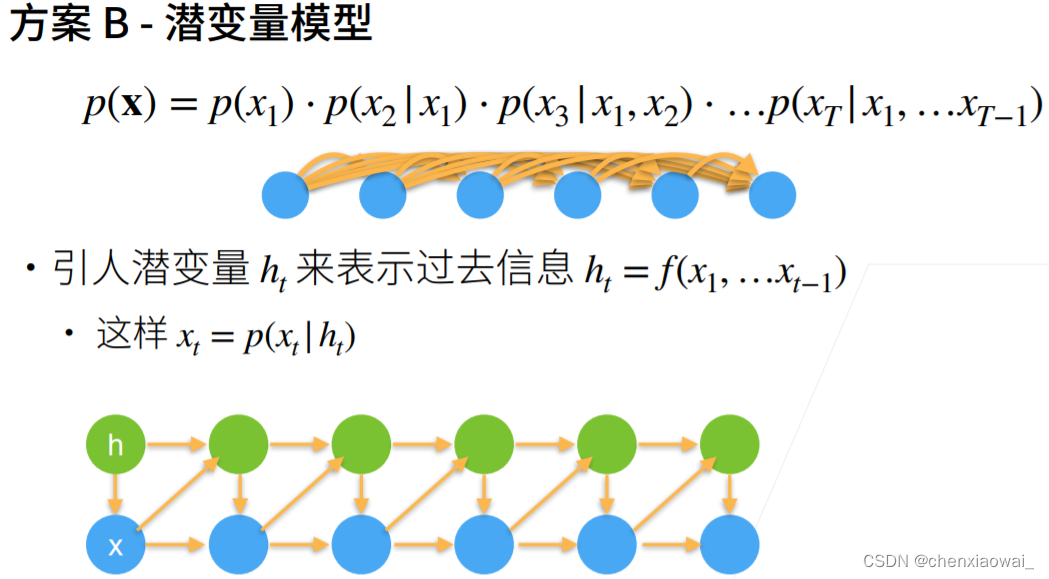

本节代码文件在源代码文件的chapter_recurrent-neural-networks/language-models-and-dataset.ipynb中



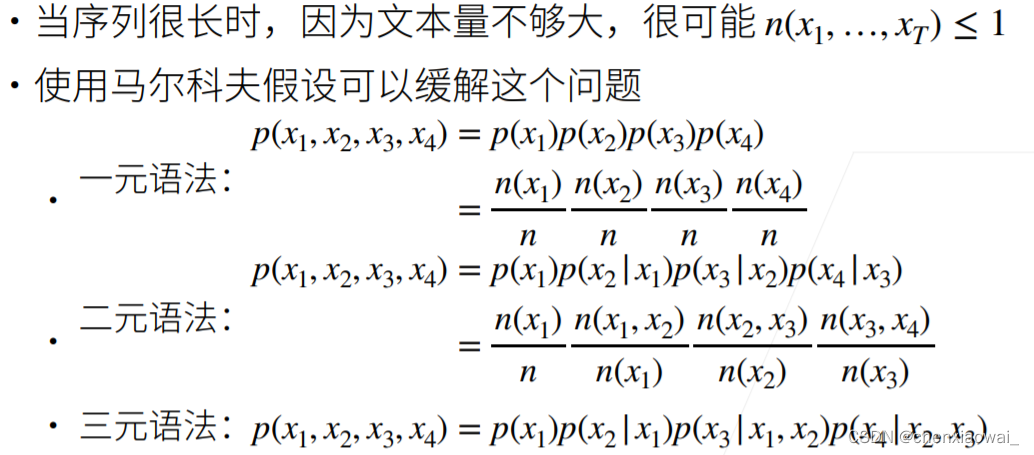

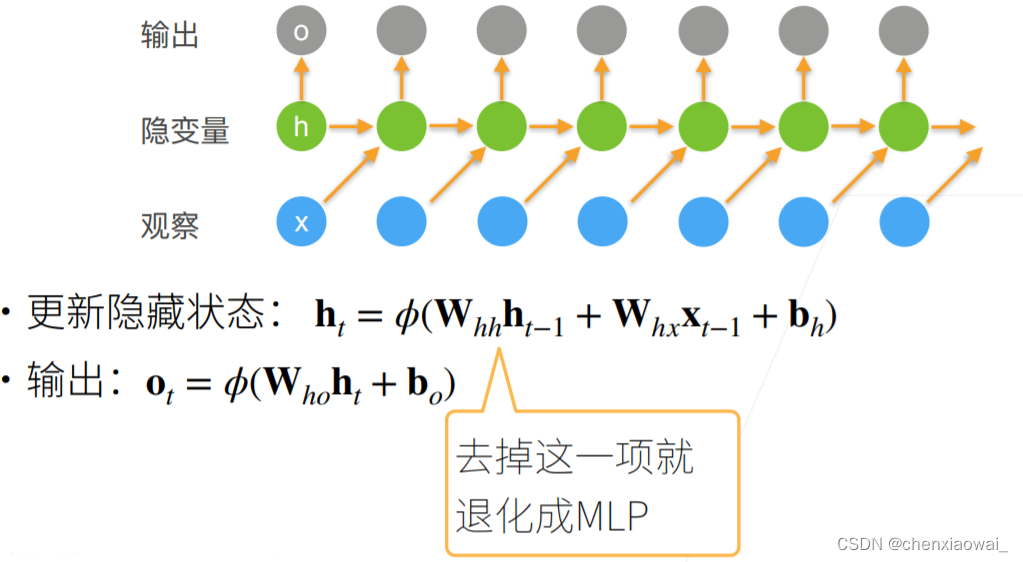
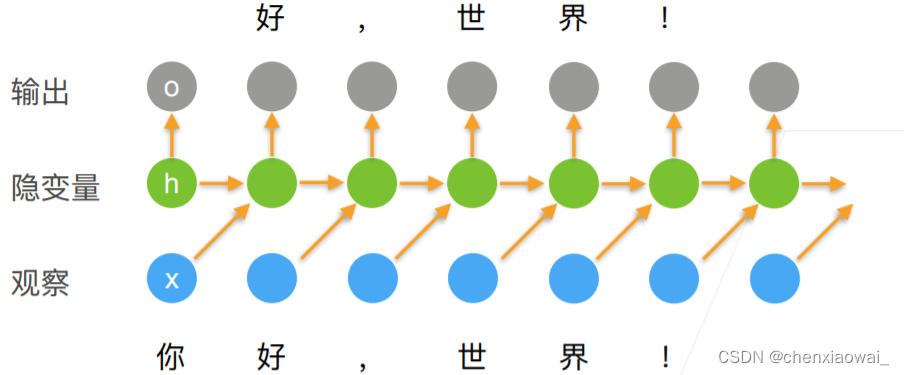
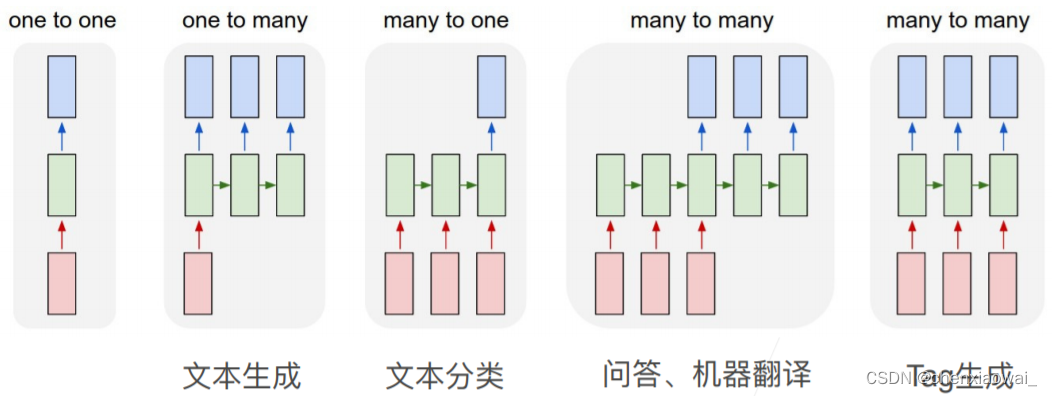
本节代码文件在源代码文件的chapter_recurrent-neural-networks/rnn.ipynb中
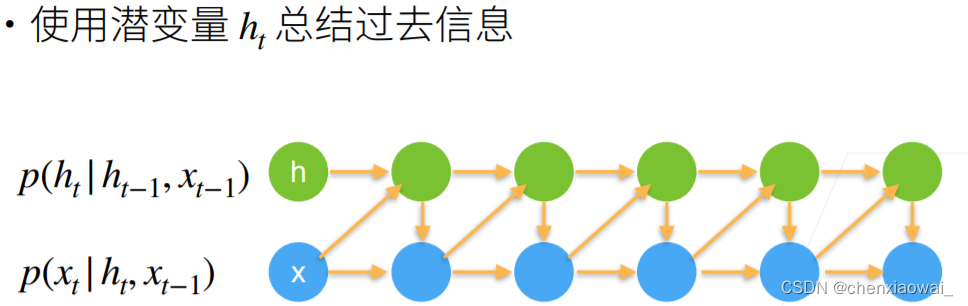



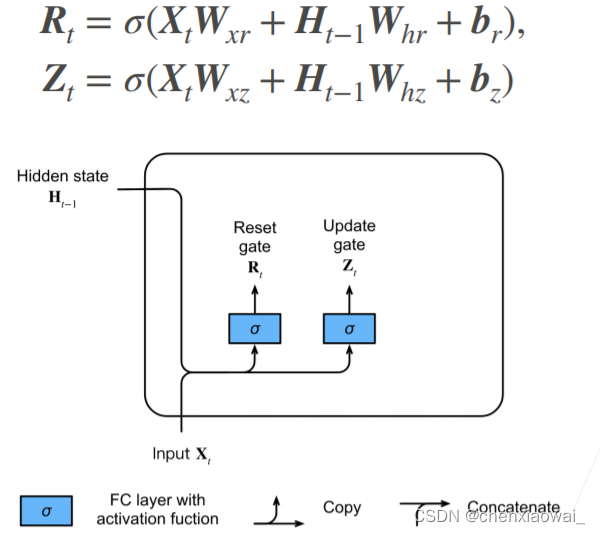
本节代码文件在源代码文件的chapter_recurrent-modern/gru.ipynb中


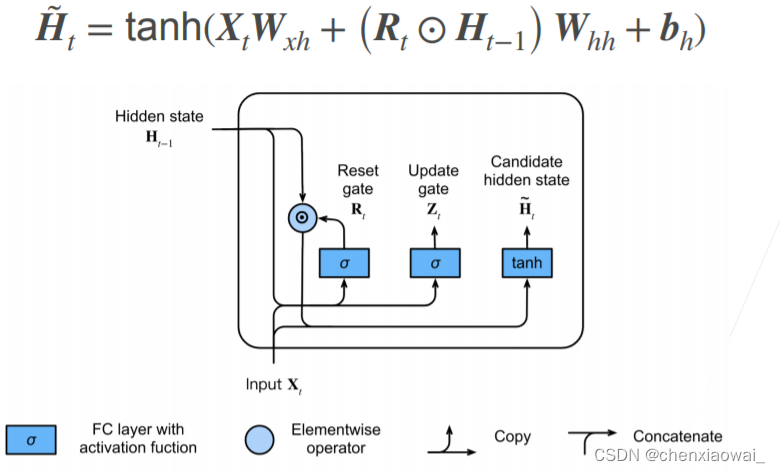
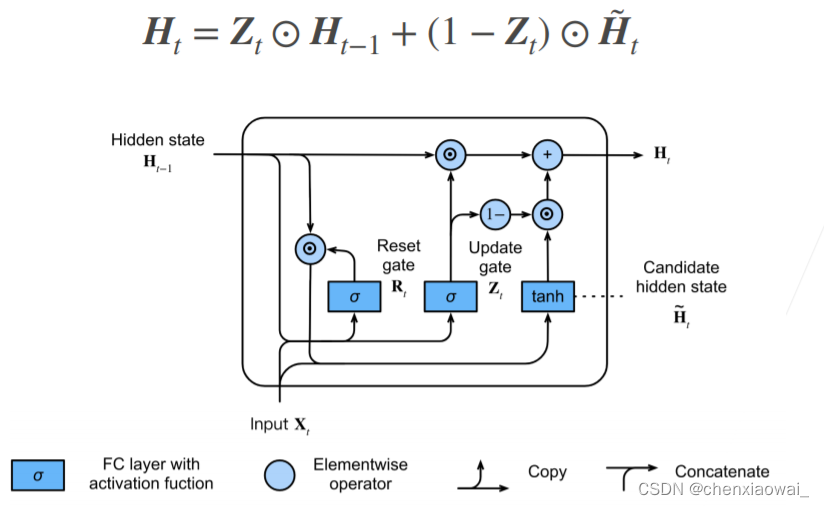
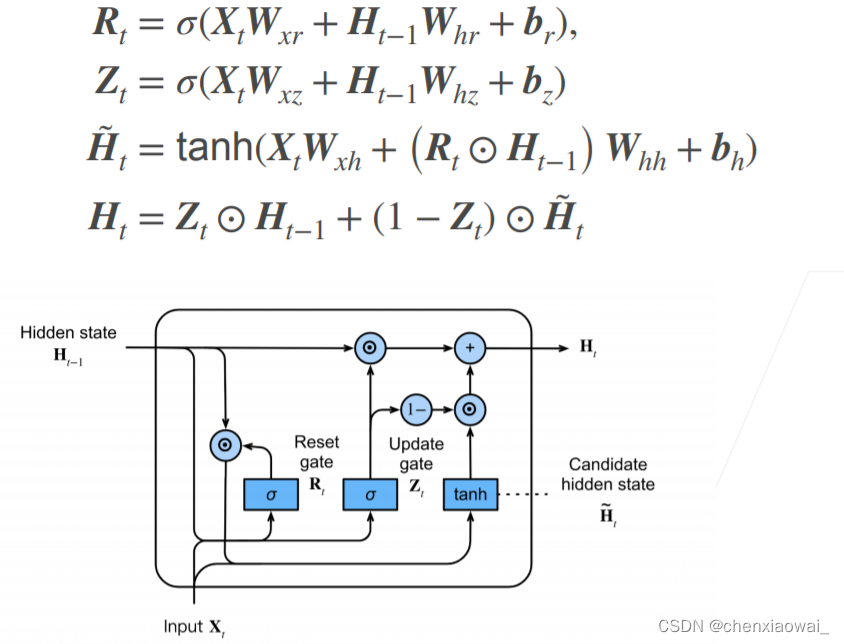
本节代码文件在源代码文件的chapter_recurrent-modern/lstm.ipynb中

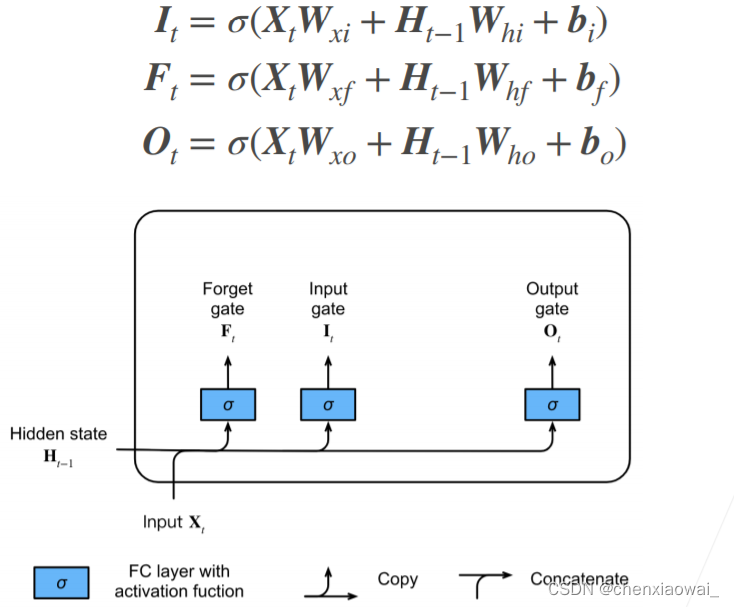
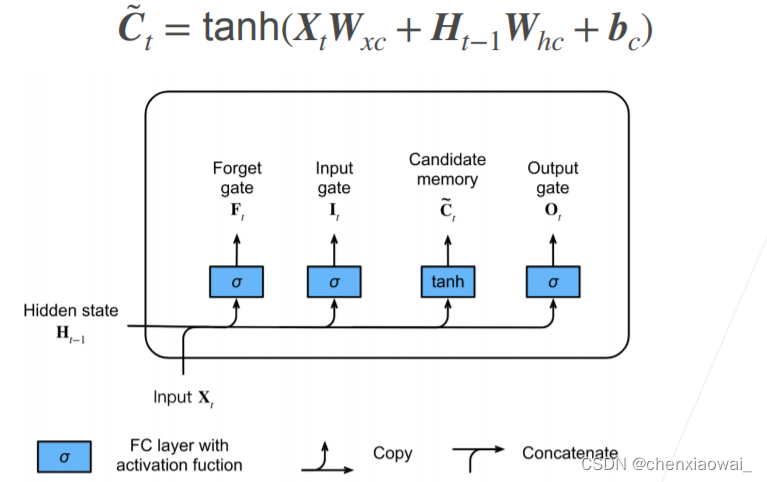
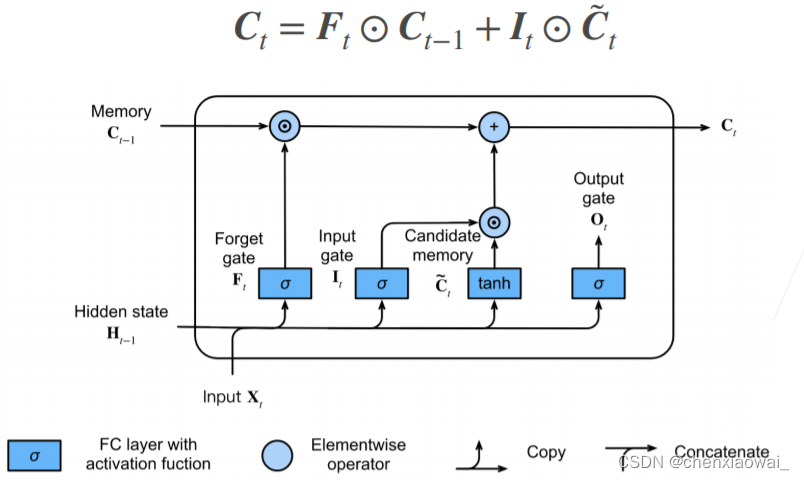
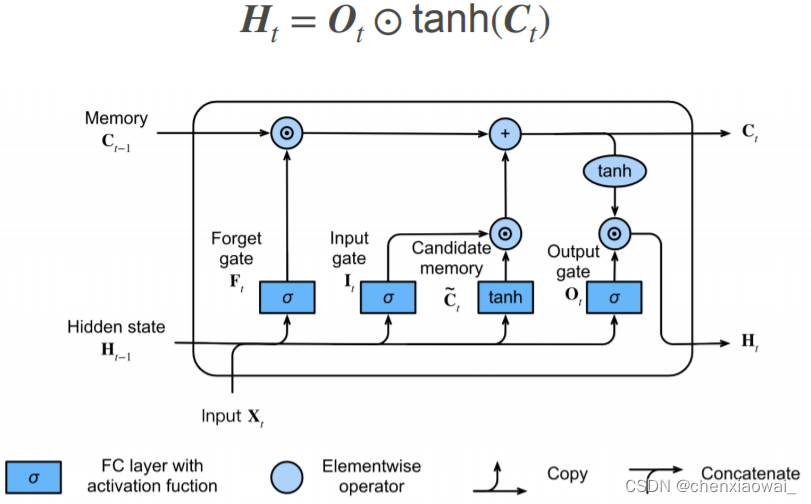
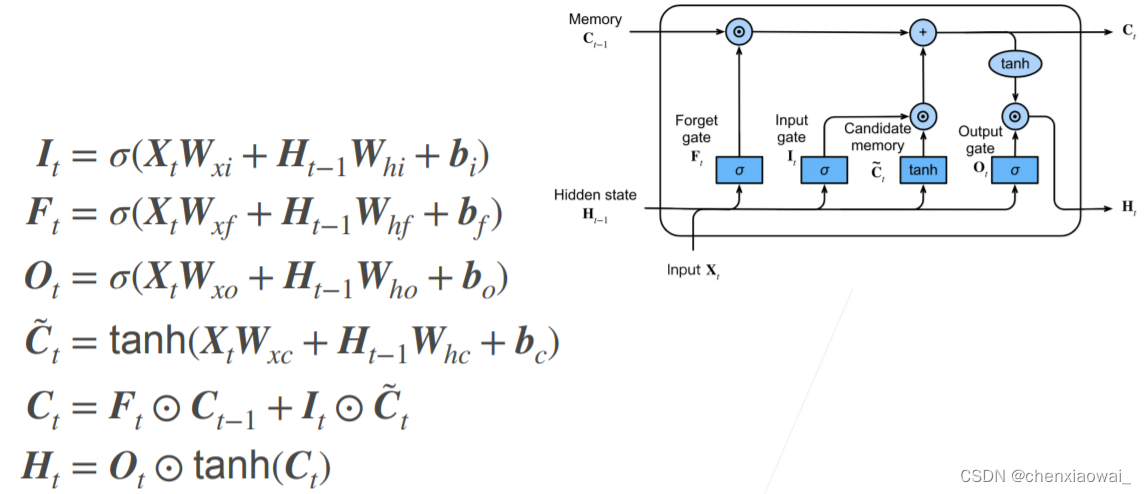
本节代码文件在源代码文件的chapter_recurrent-modern/deep-rnn.ipynb中
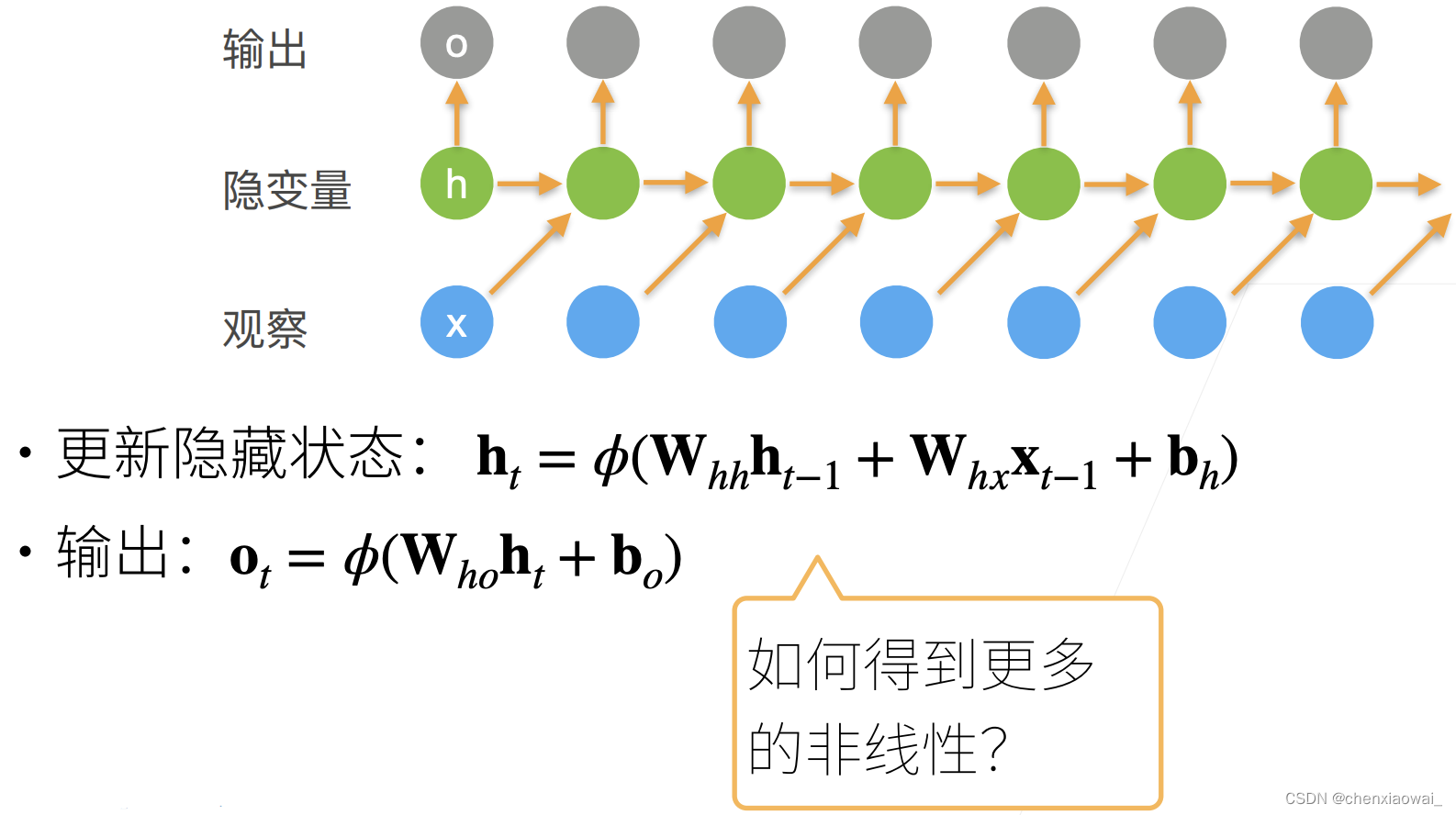
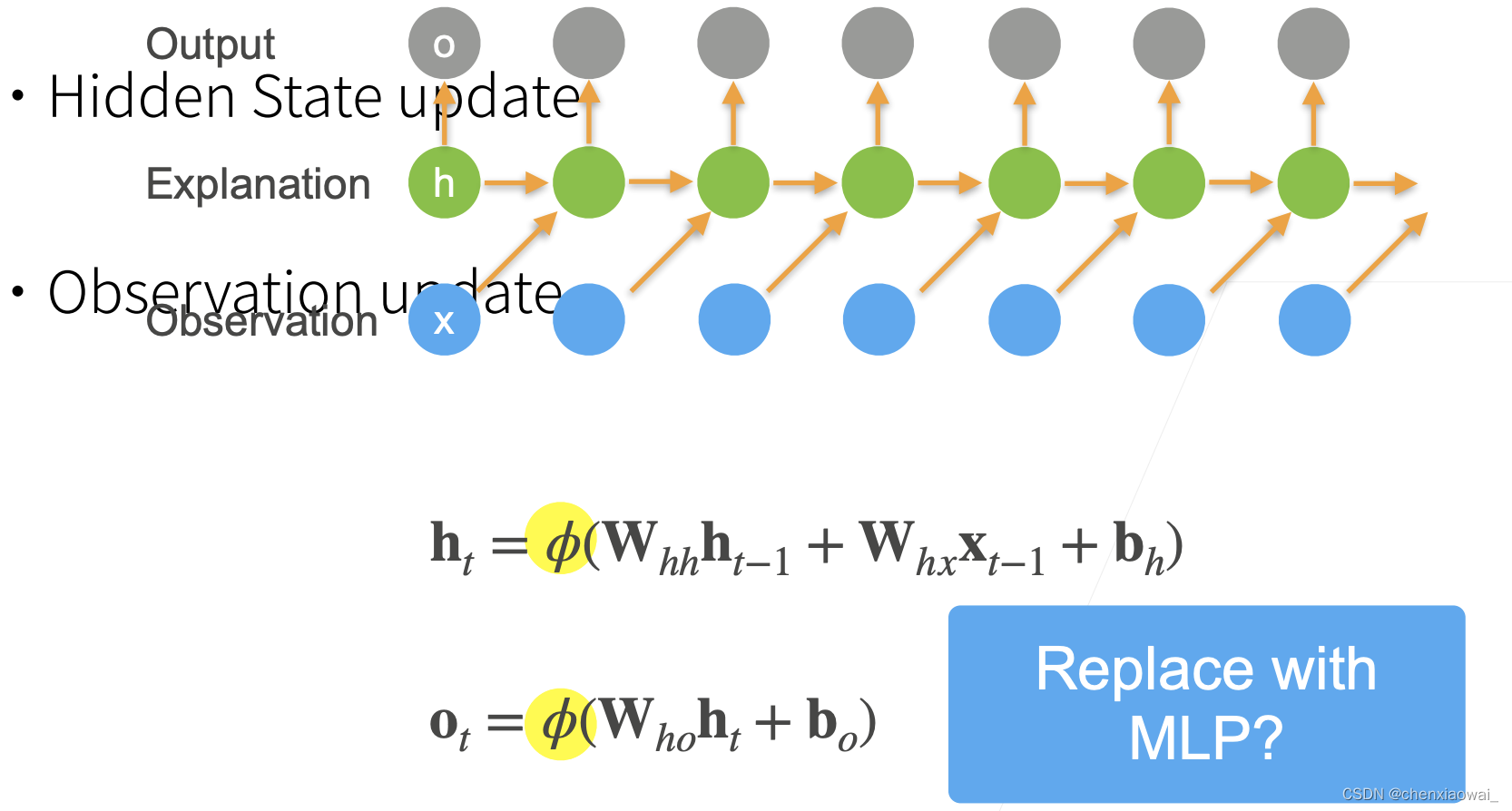
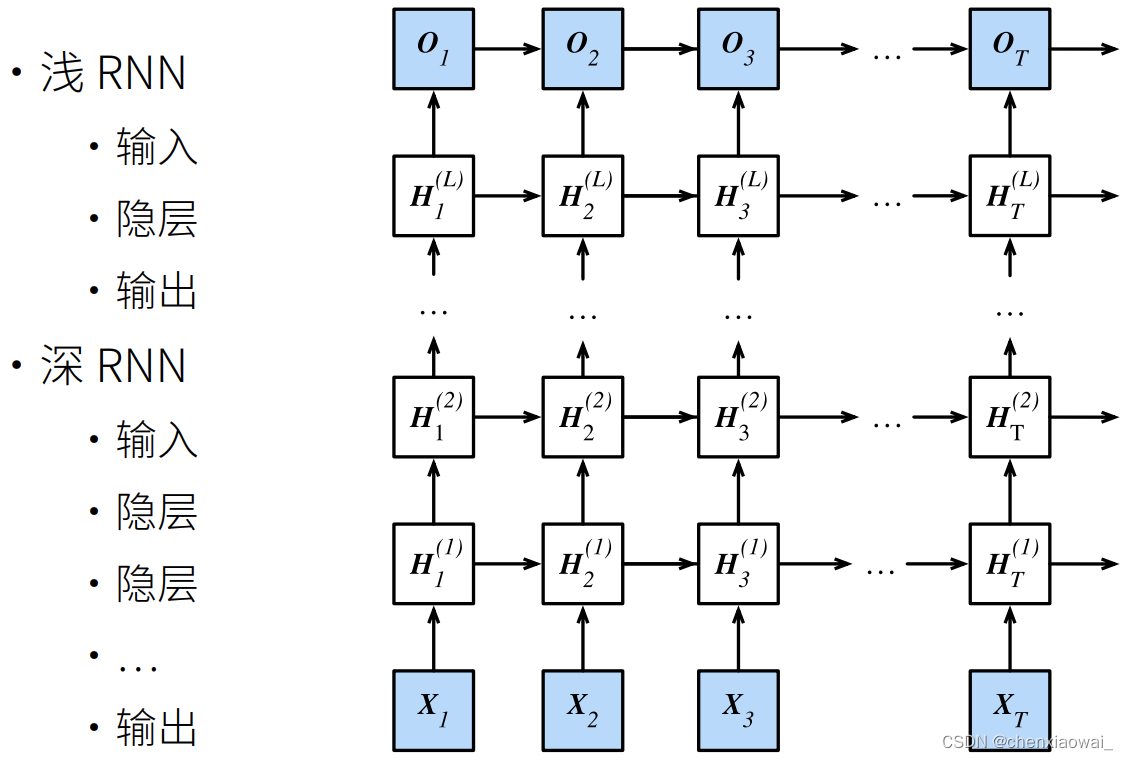
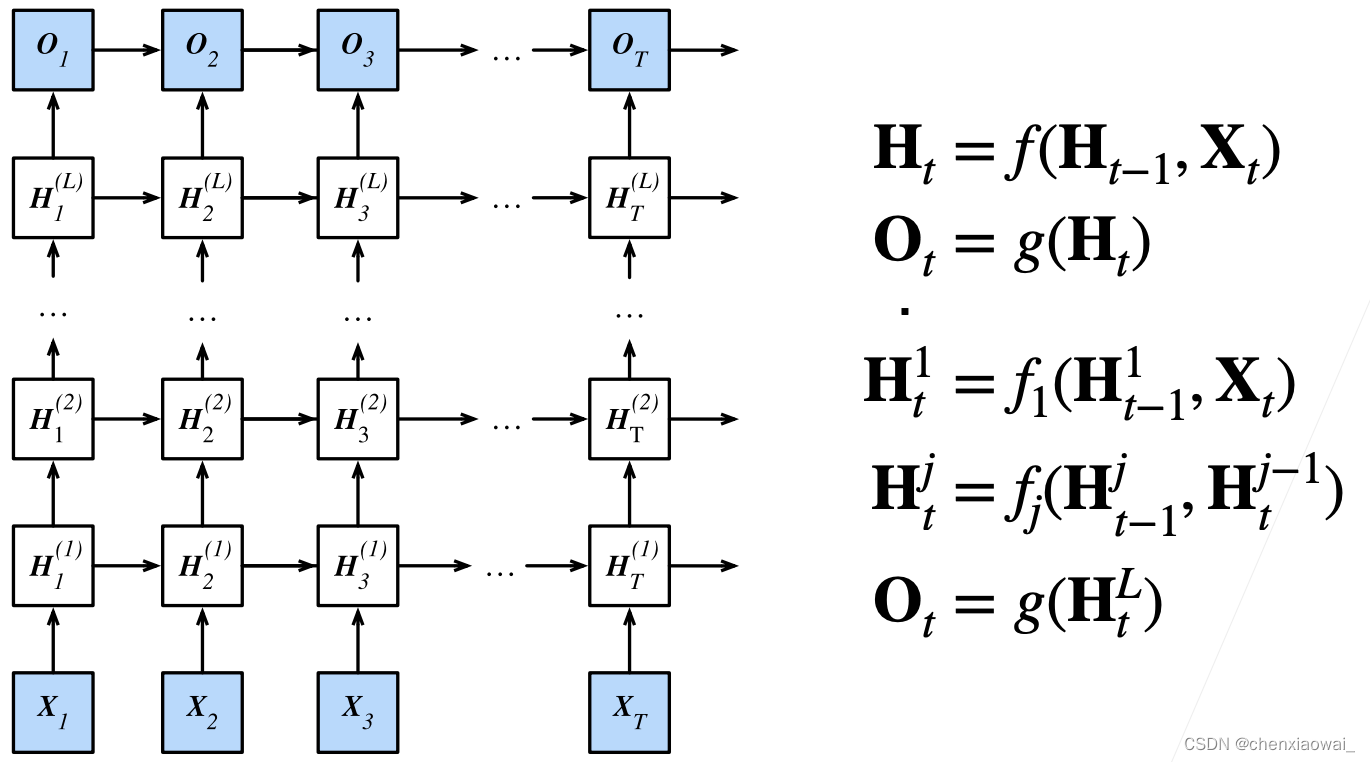

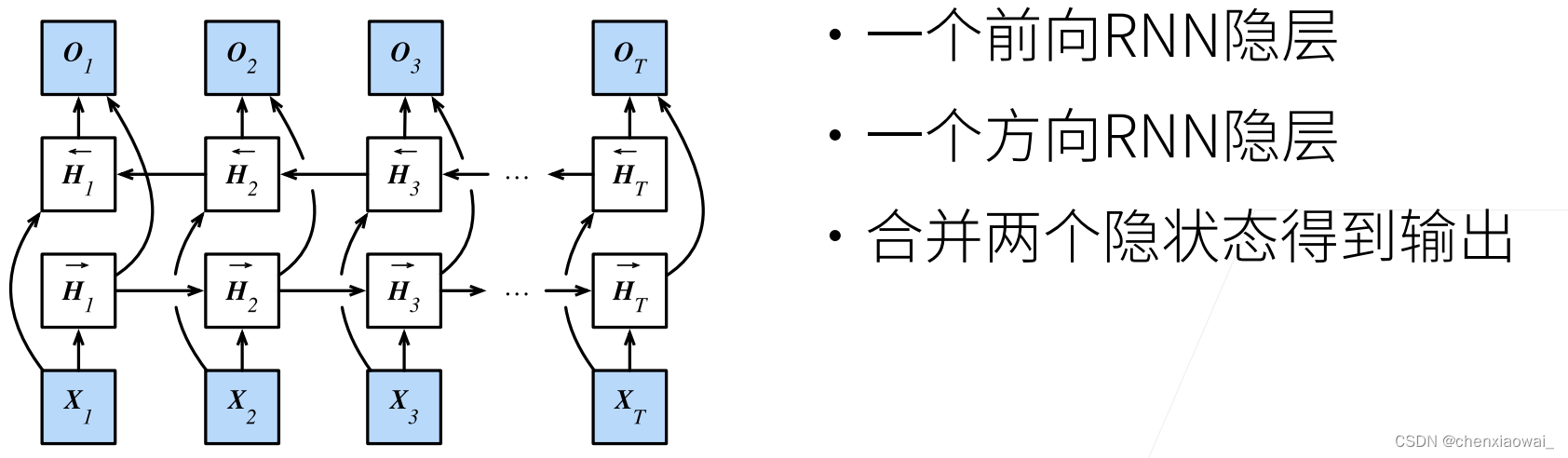
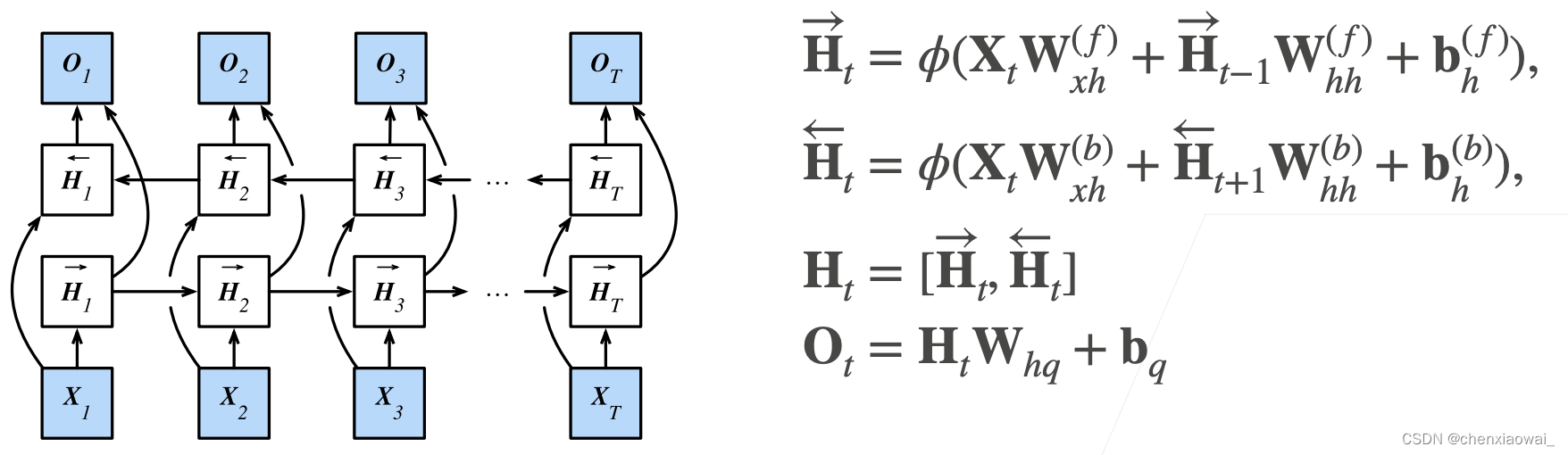
本节代码文件在源代码文件的chapter_recurrent-modern/bi-rnn.ipynb中


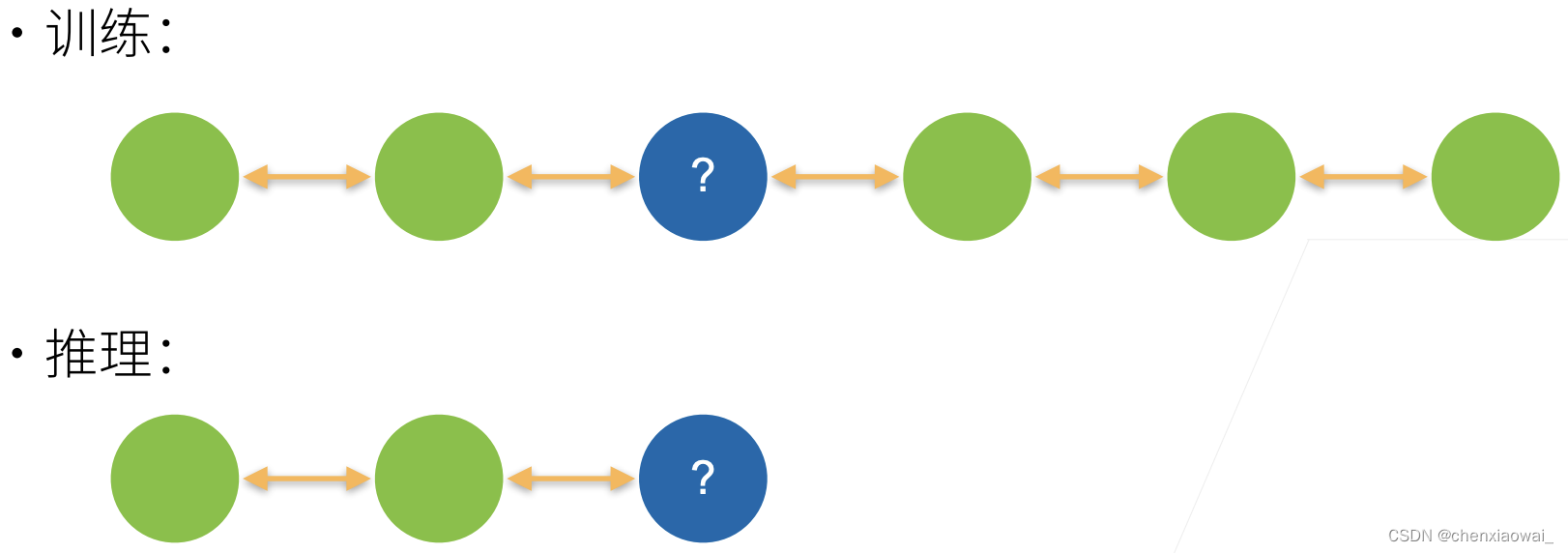

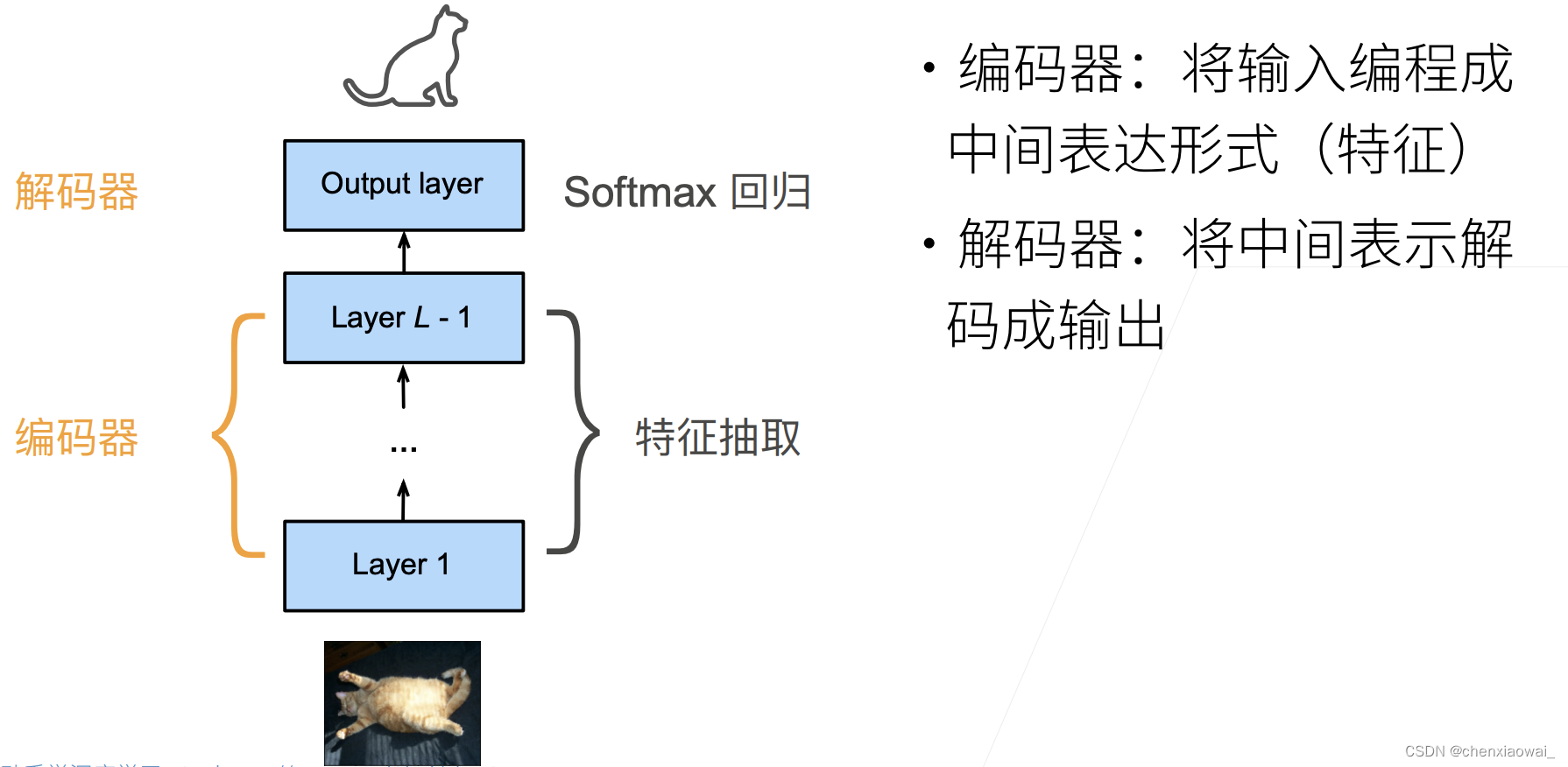
本节代码文件在源代码文件的chapter_recurrent-modern/encoder-decoder.ipynb中
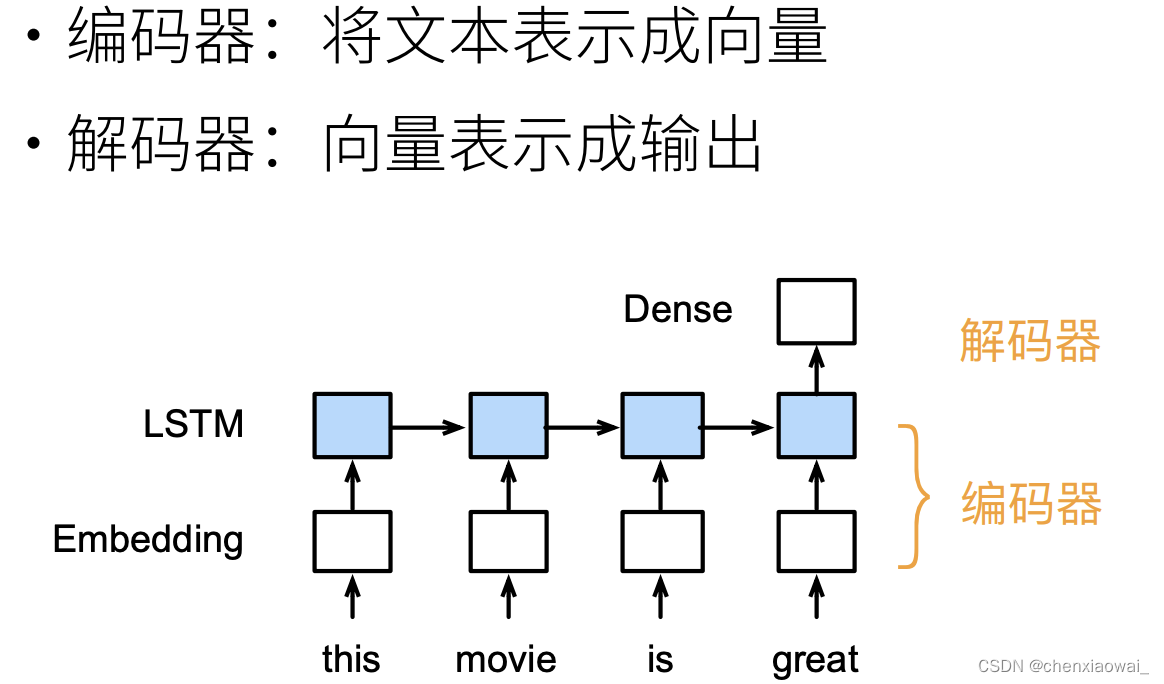
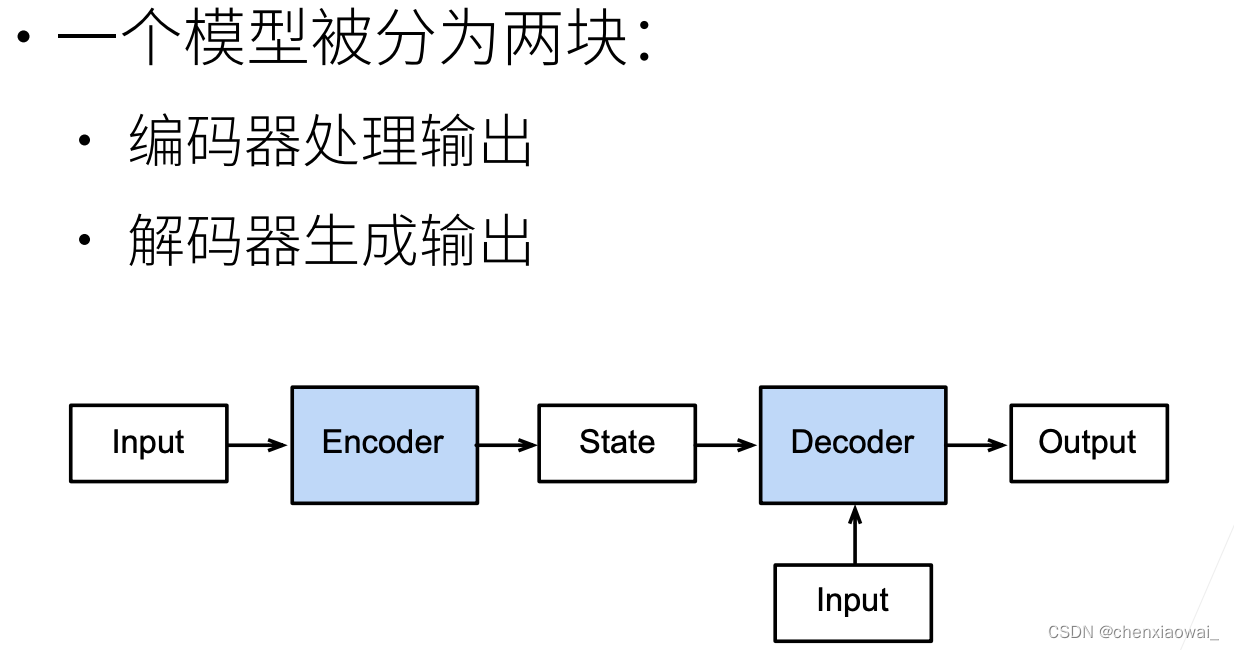

本节代码文件在源代码文件的chapter_recurrent-modern/seq2seq.ipynb中
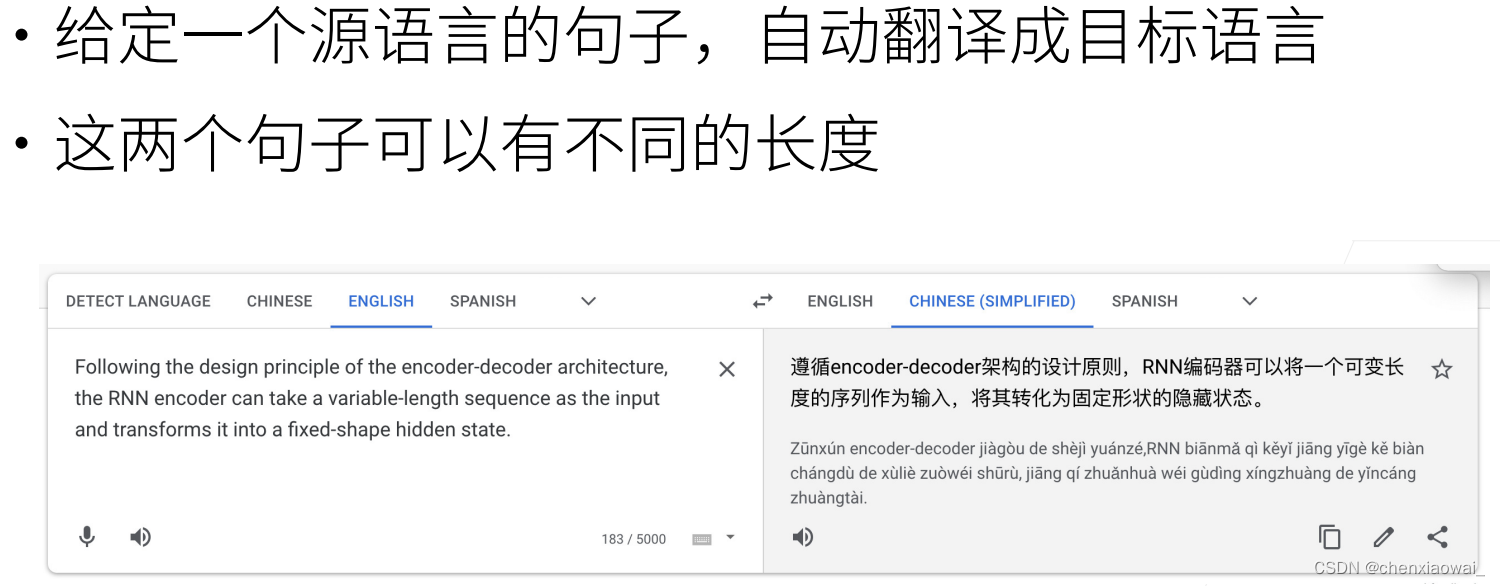
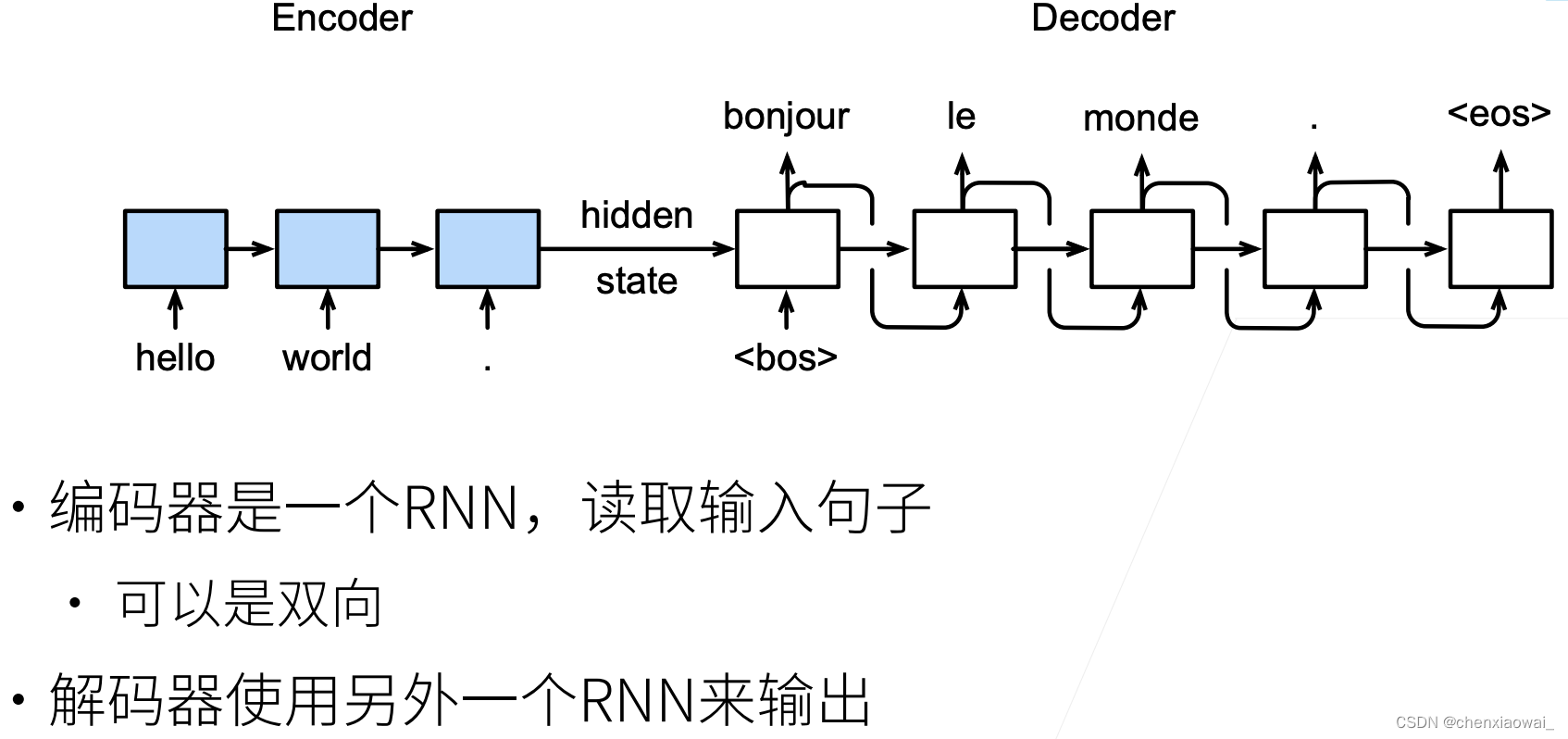
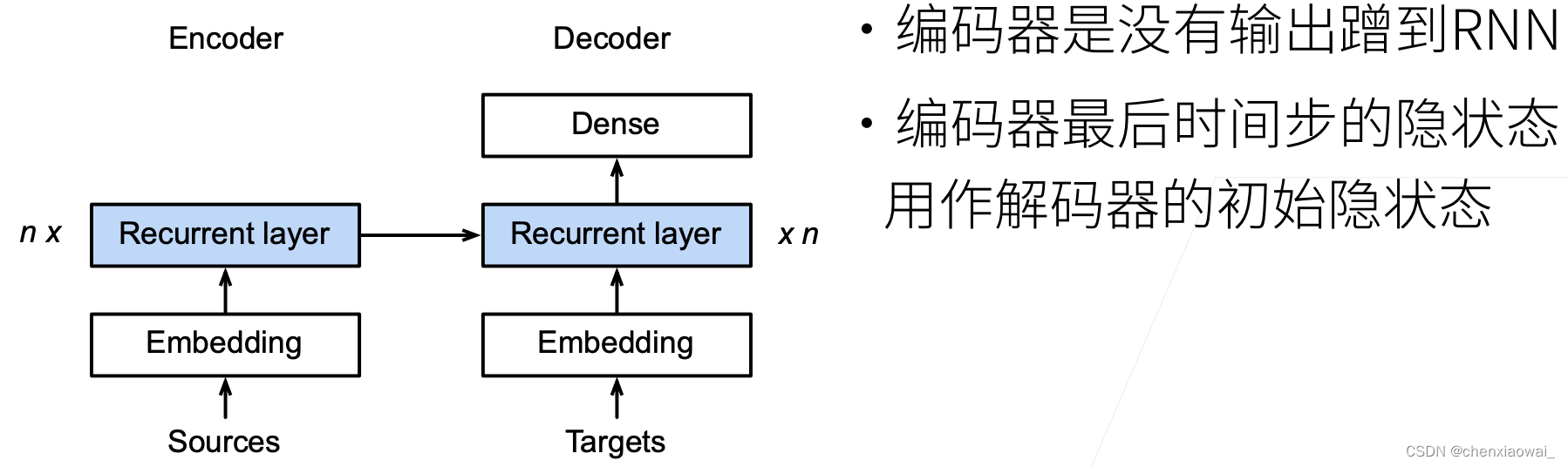
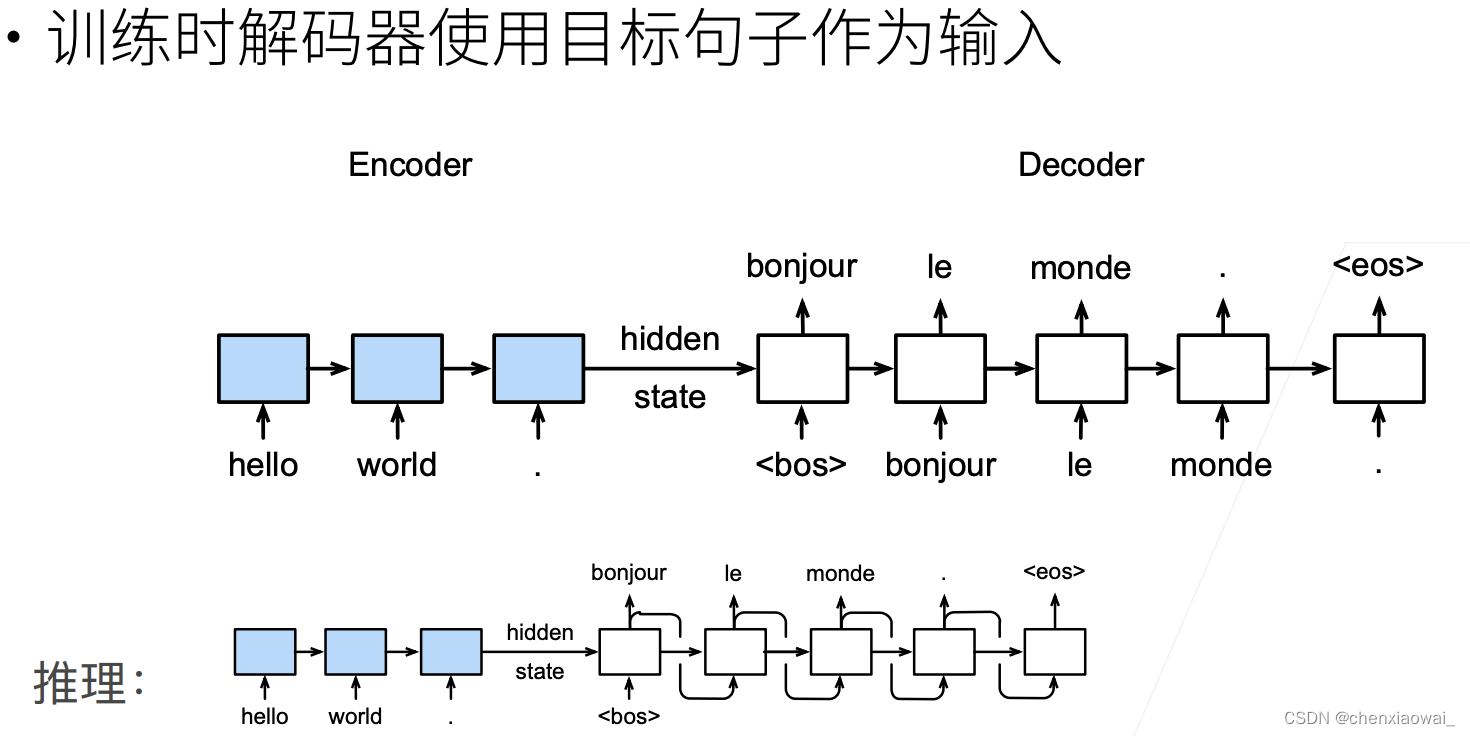
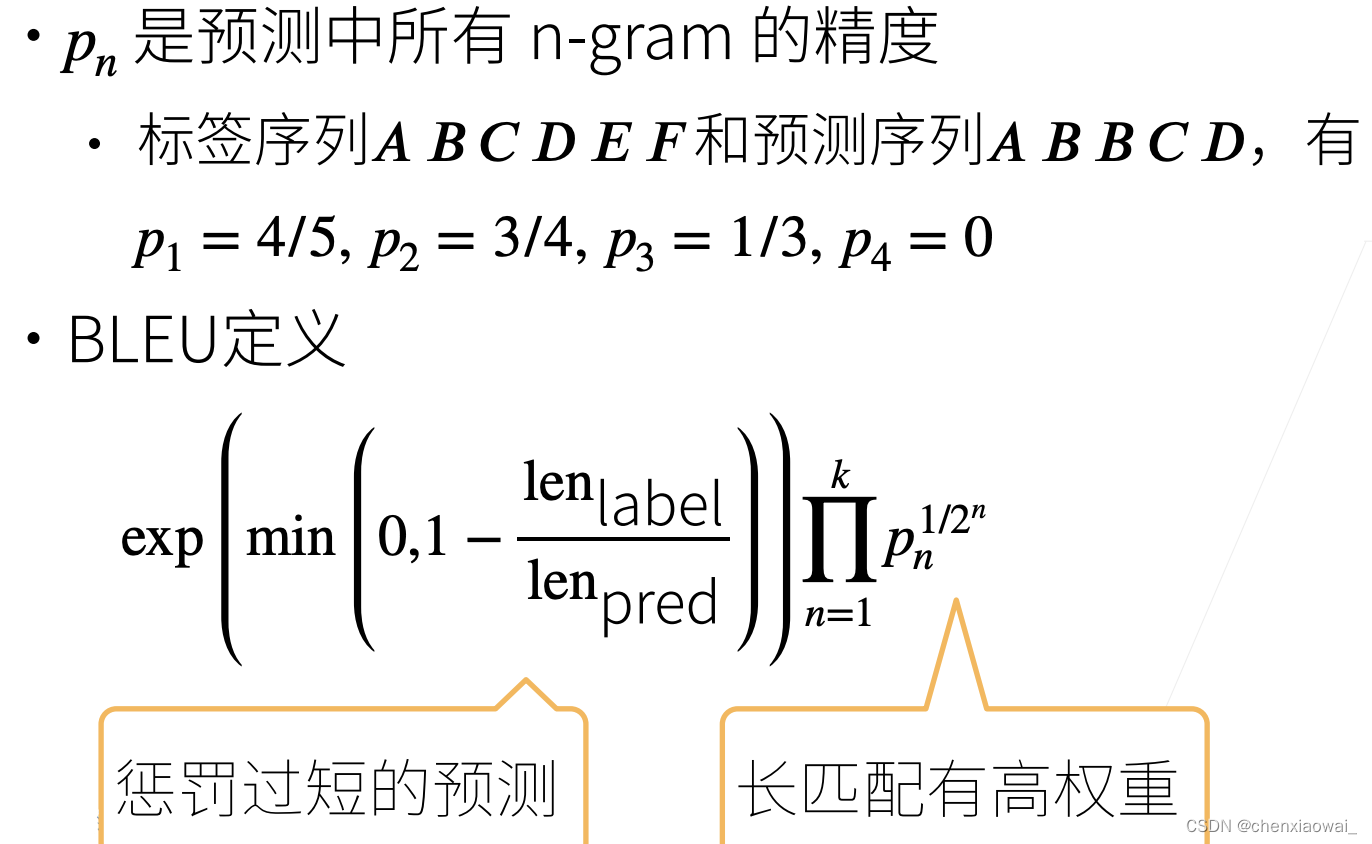

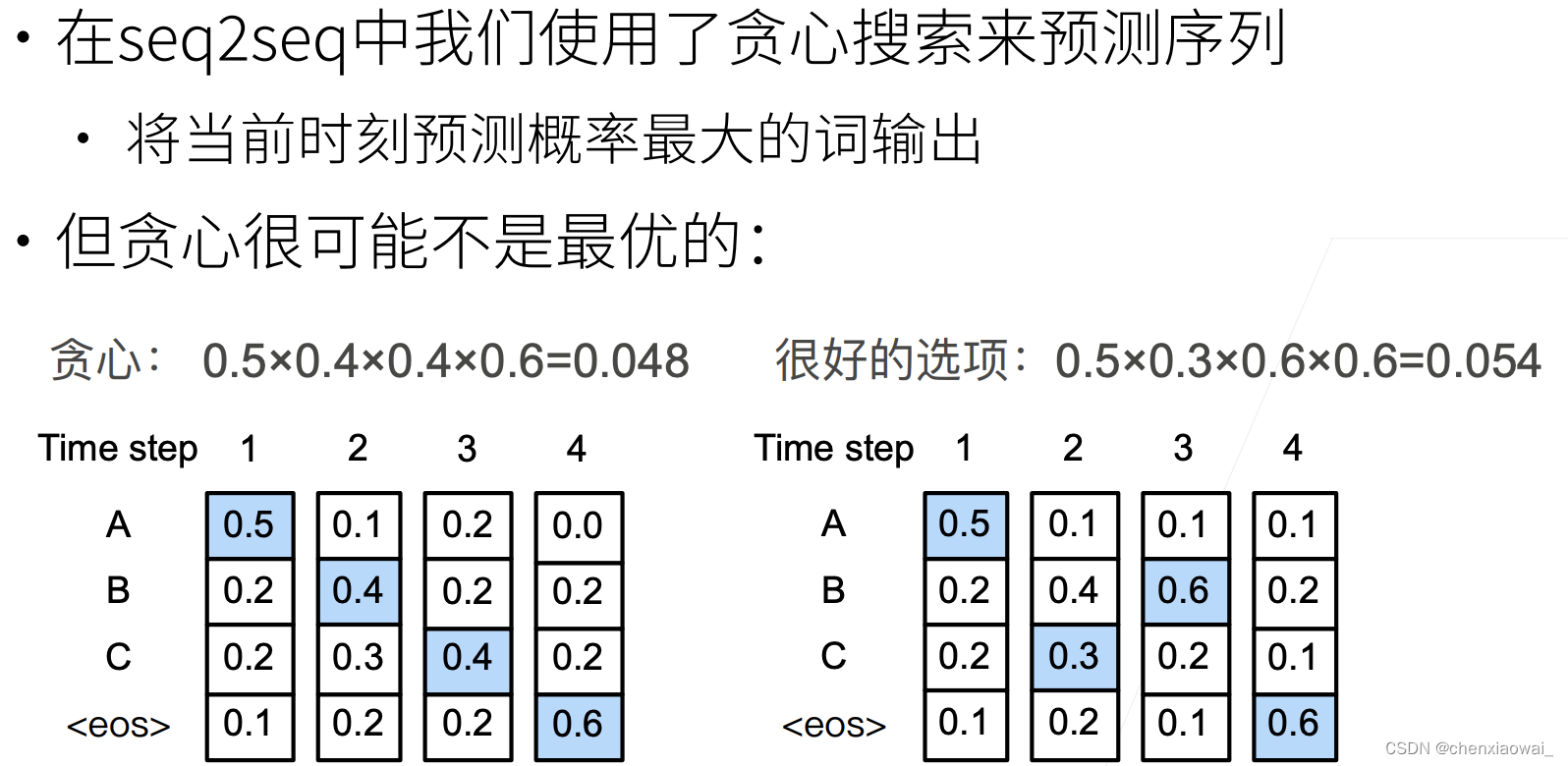
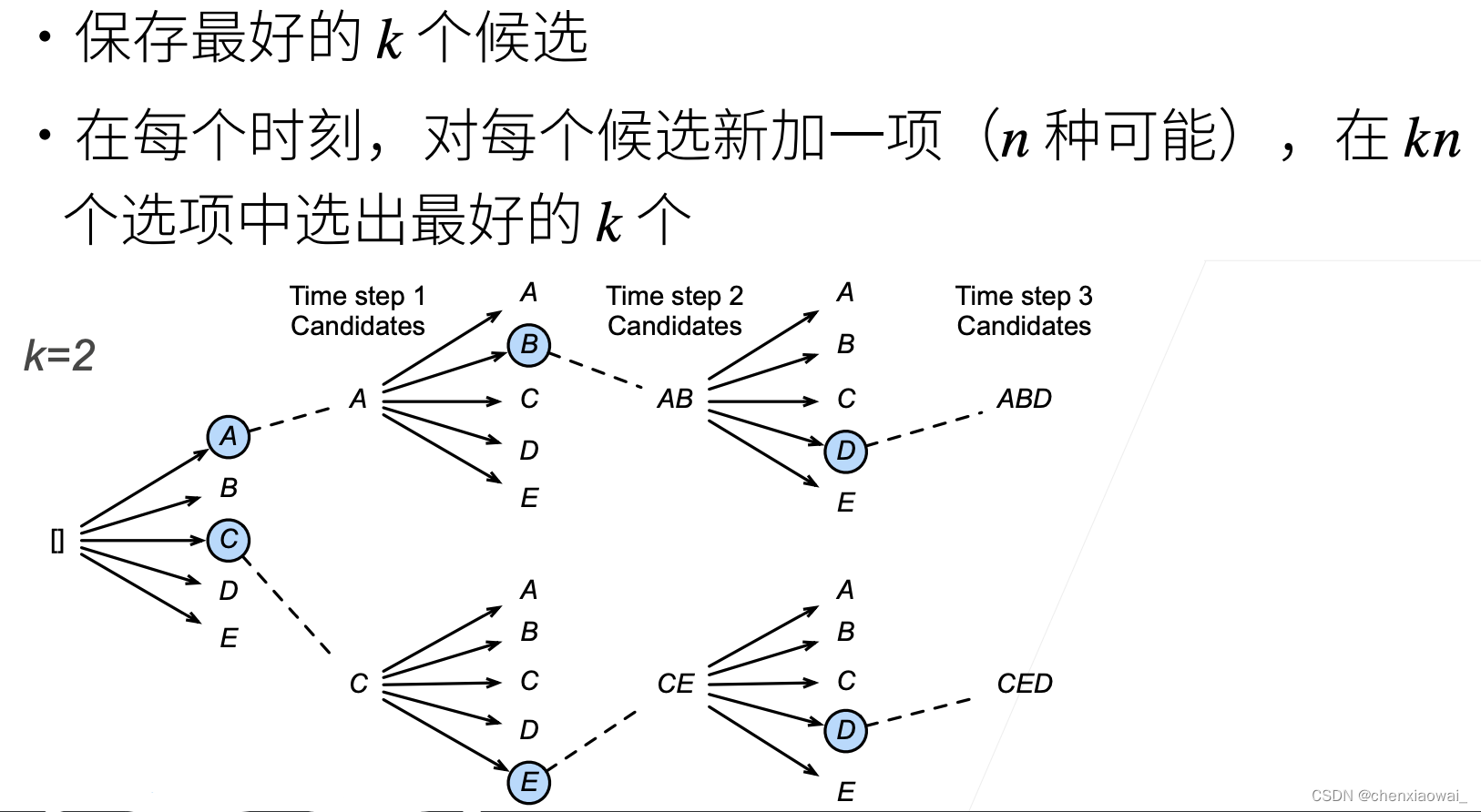
本节代码文件在源代码文件的chapter_recurrent-modern/beam-search.ipynb中



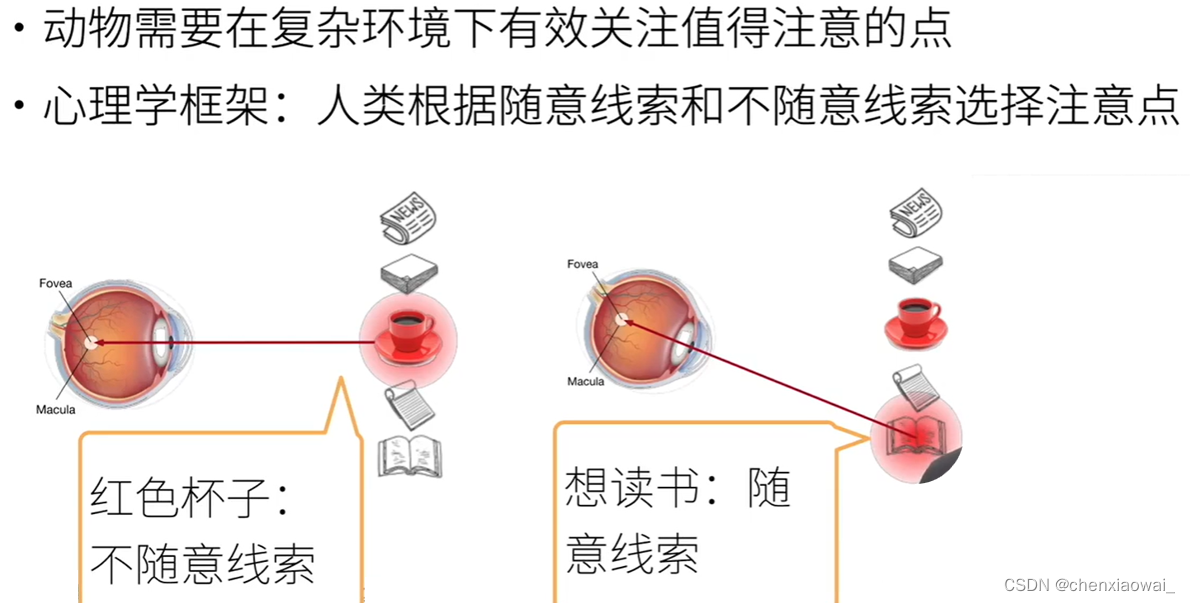
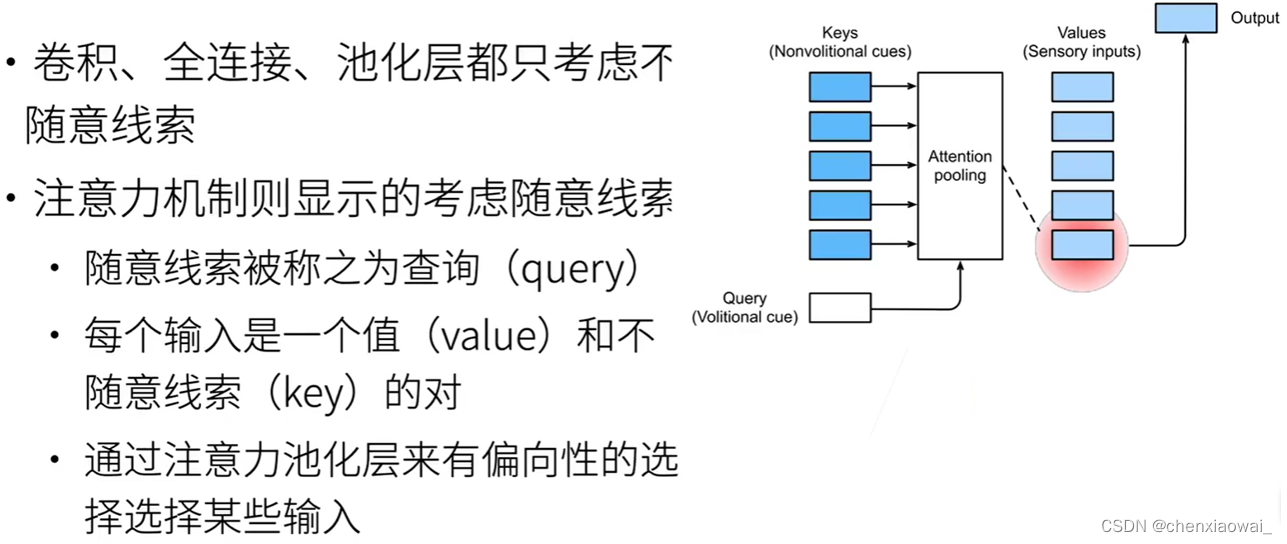
本节代码文件在源代码文件的chapter_attention-mechanisms/attention-cues.ipynb中
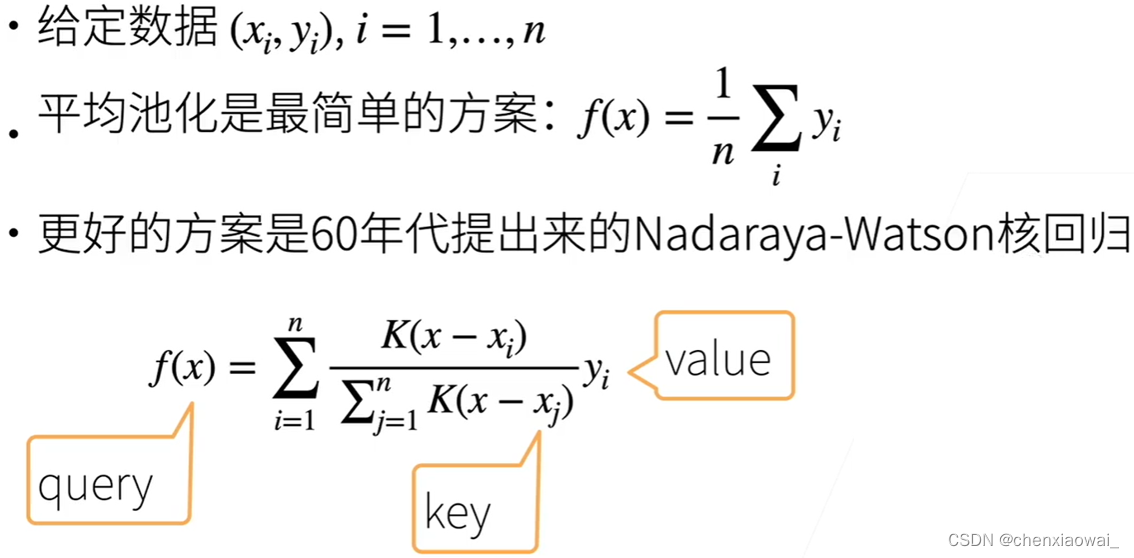
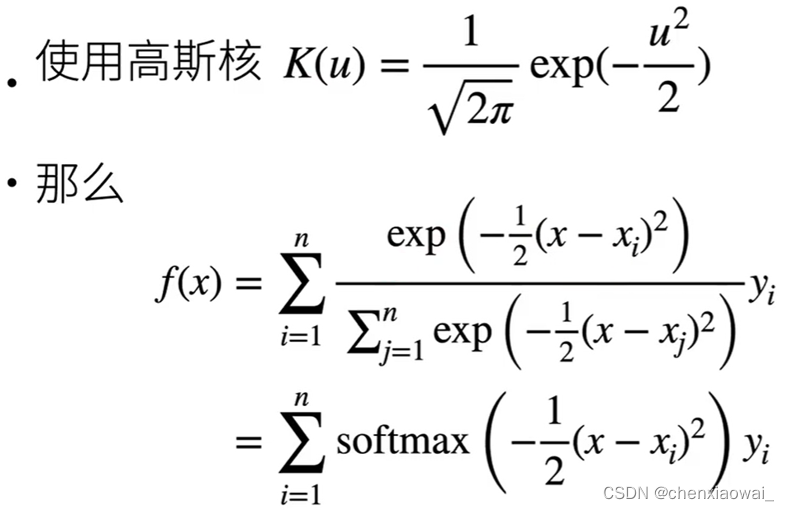


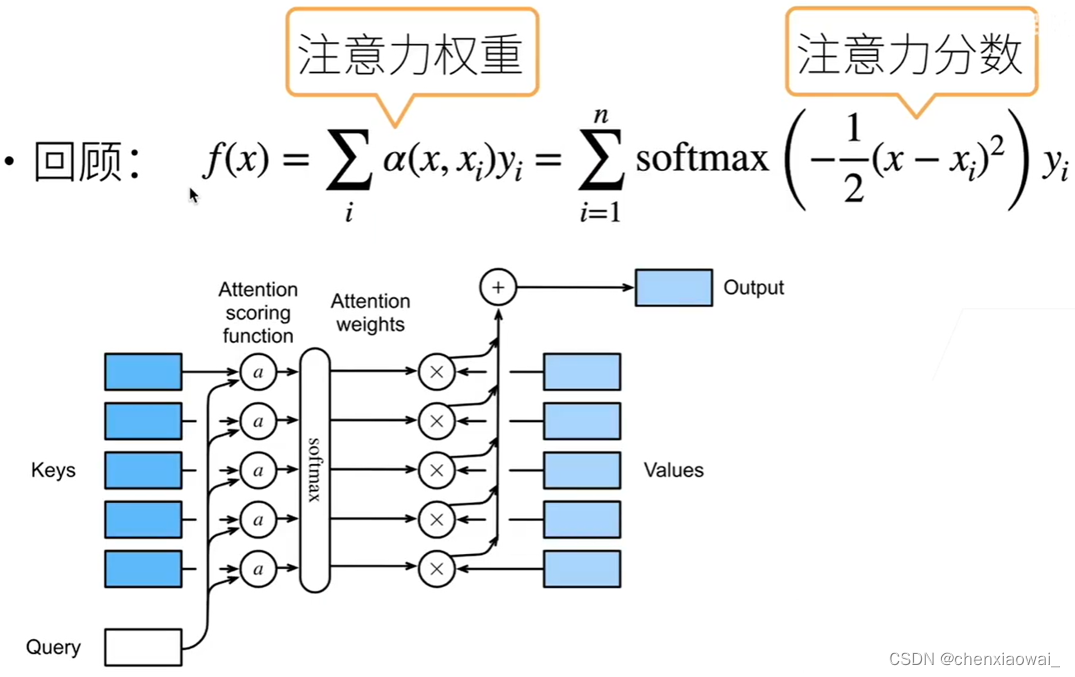
本节代码文件在源代码文件的chapter_attention-mechanisms/attention-scoring-functions.ipynb中




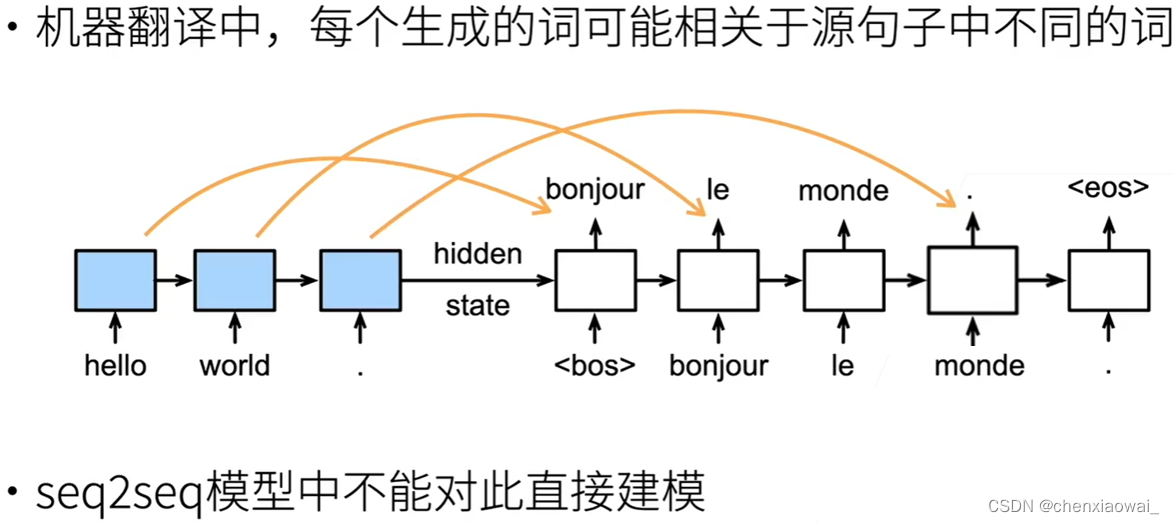
本节代码文件在源代码文件的chapter_attention-mechanisms/bahdanau-attention.ipynb中
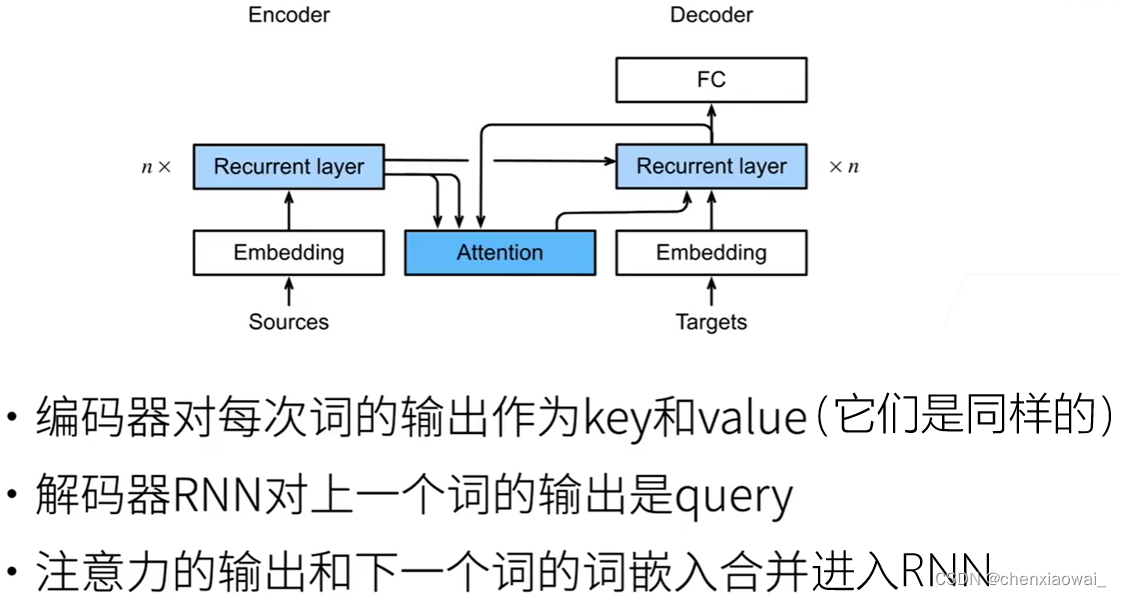

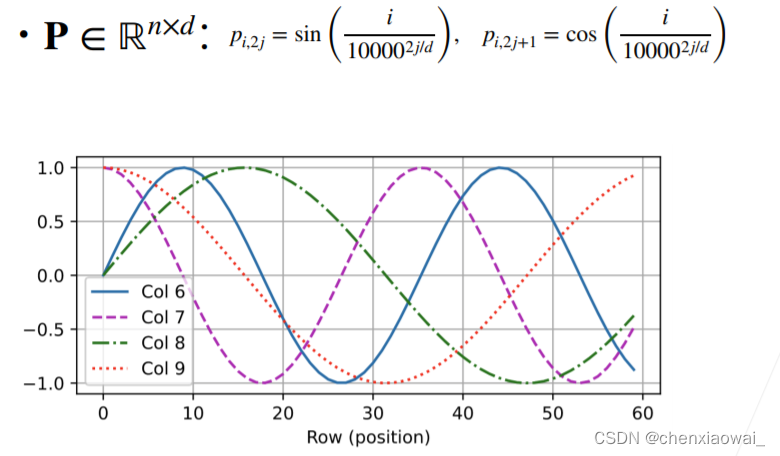
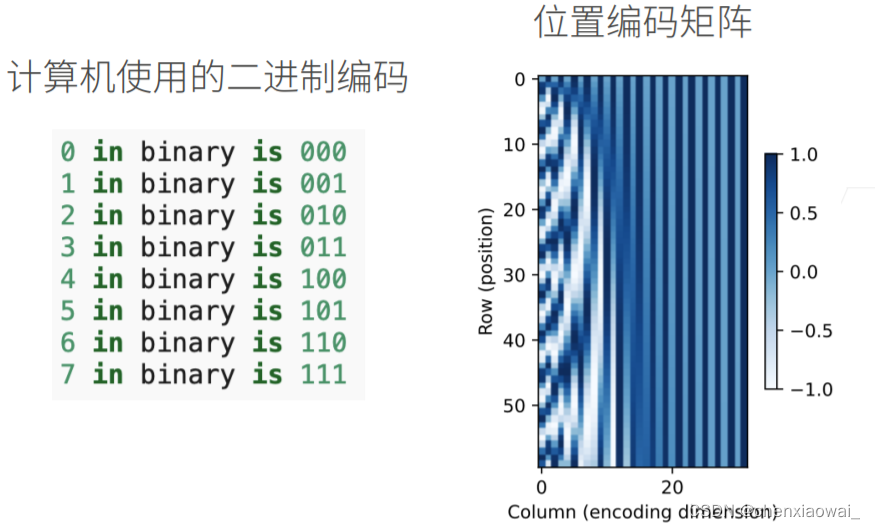
本节代码文件在源代码文件的chapter_attention-mechanisms/self-attention-and-positional-encoding.ipynb中

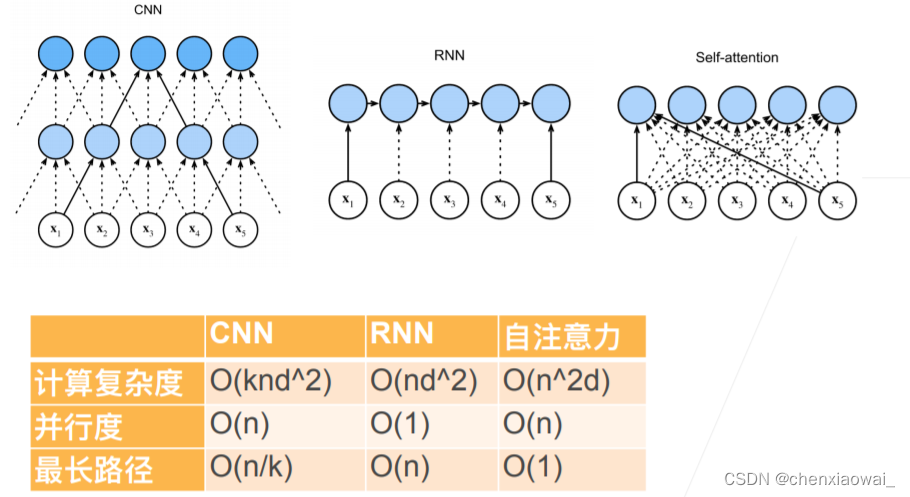



本节代码文件在源代码文件的chapter_attention-mechanisms/transformer.ipynb中
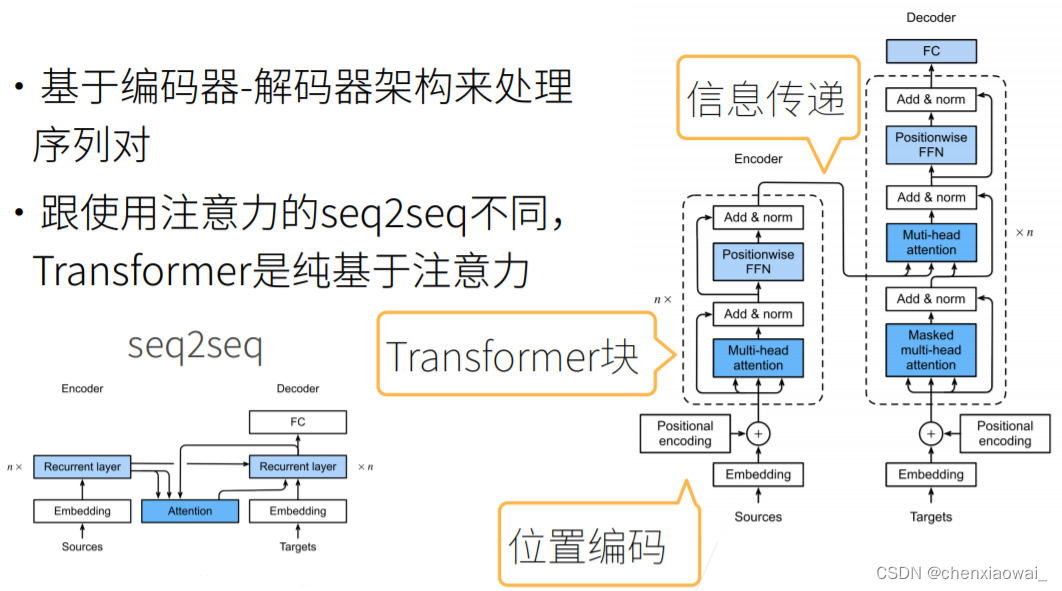
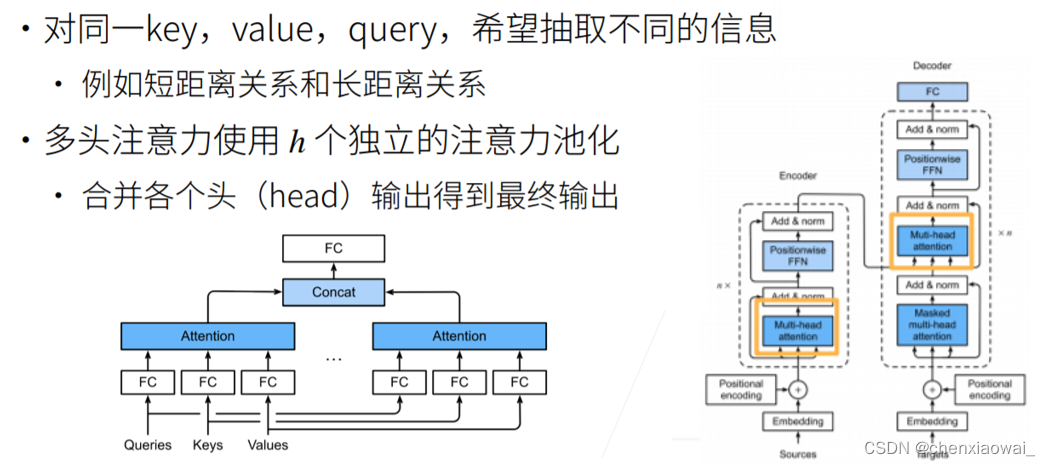
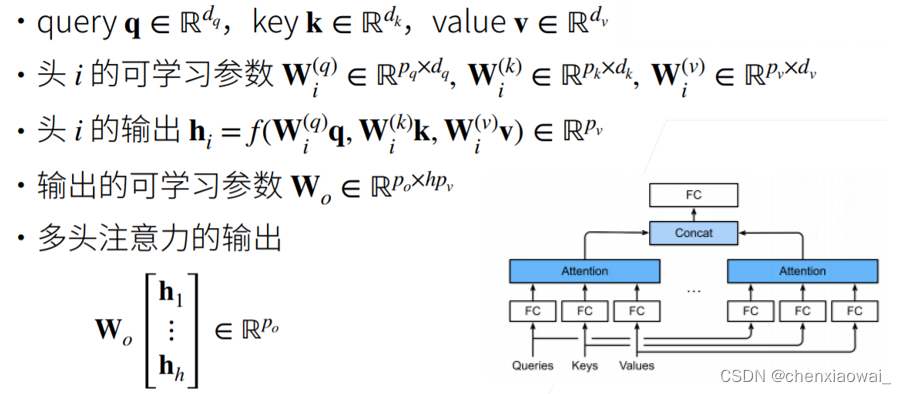


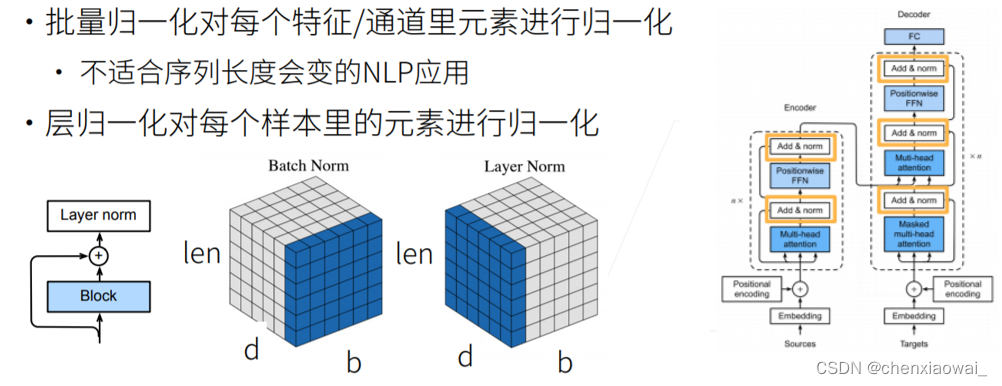


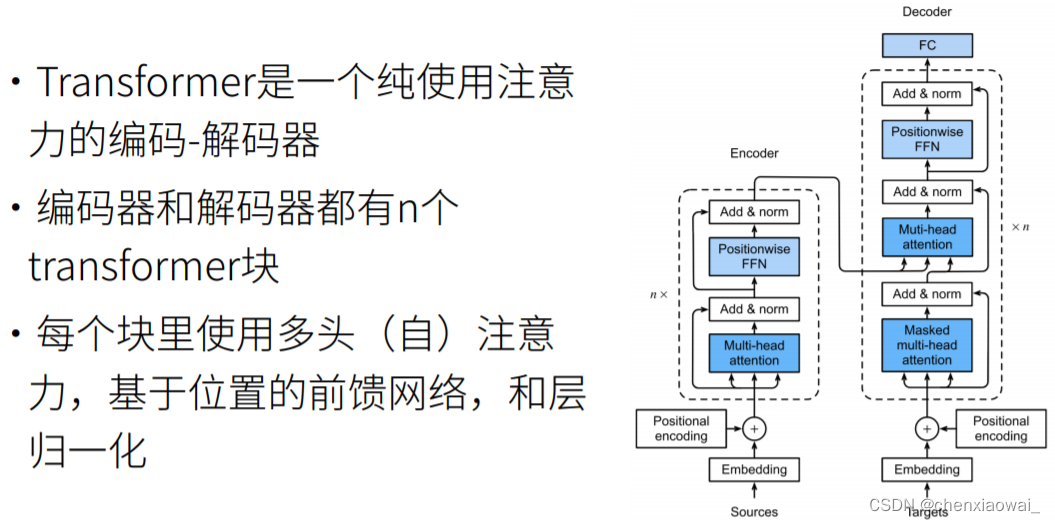
本节代码文件在源代码文件的chapter_natural-language-processing-pretraining/bert-pretraining.ipynb中

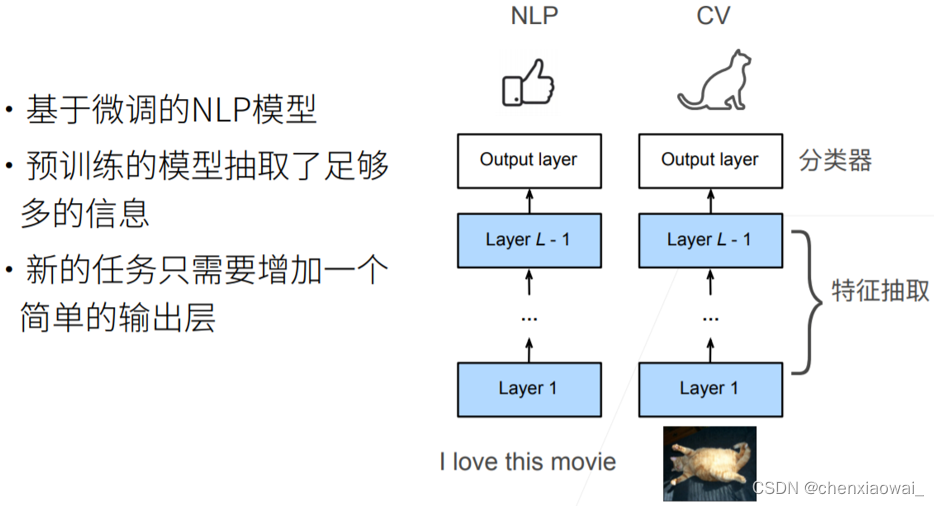





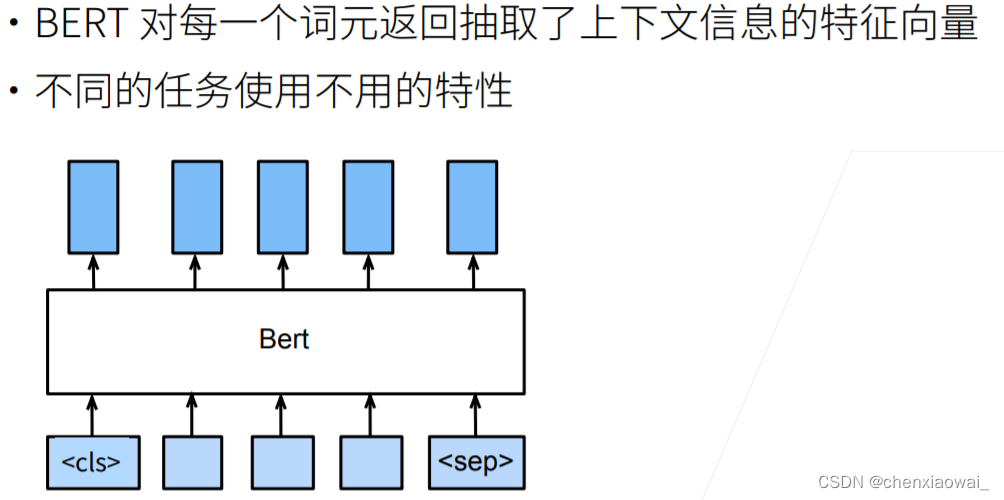
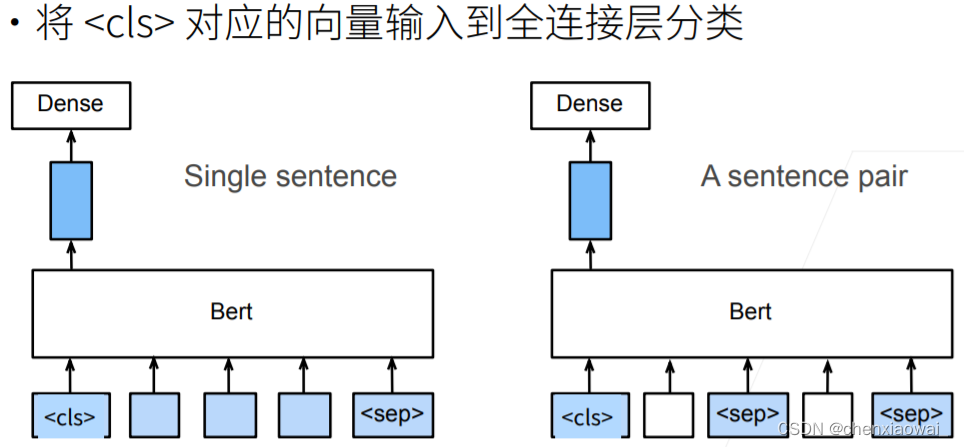
本节代码文件在源代码文件的chapter_natural-language-processing-applications/finetuning-bert.ipynb中
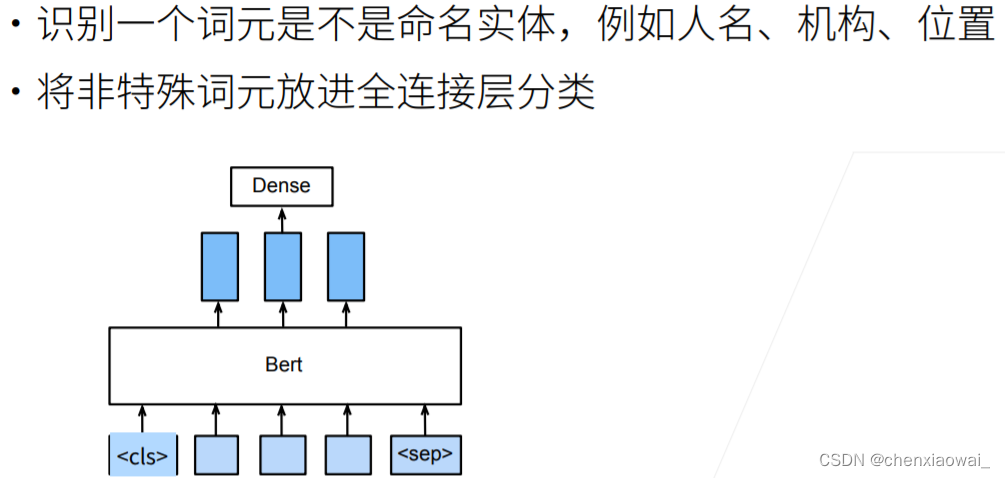
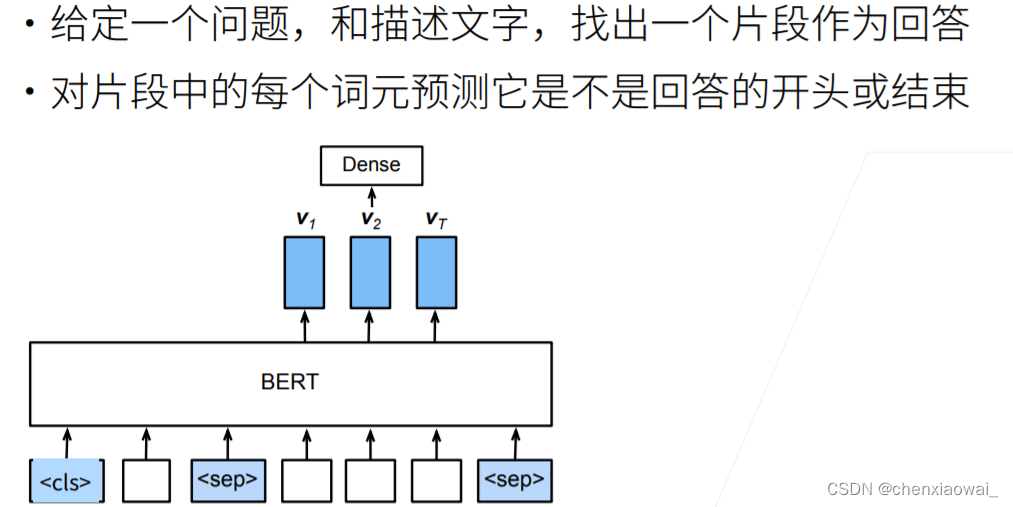

本节代码文件在源代码文件的chapter_optimization/optimization-intro.ipynb中

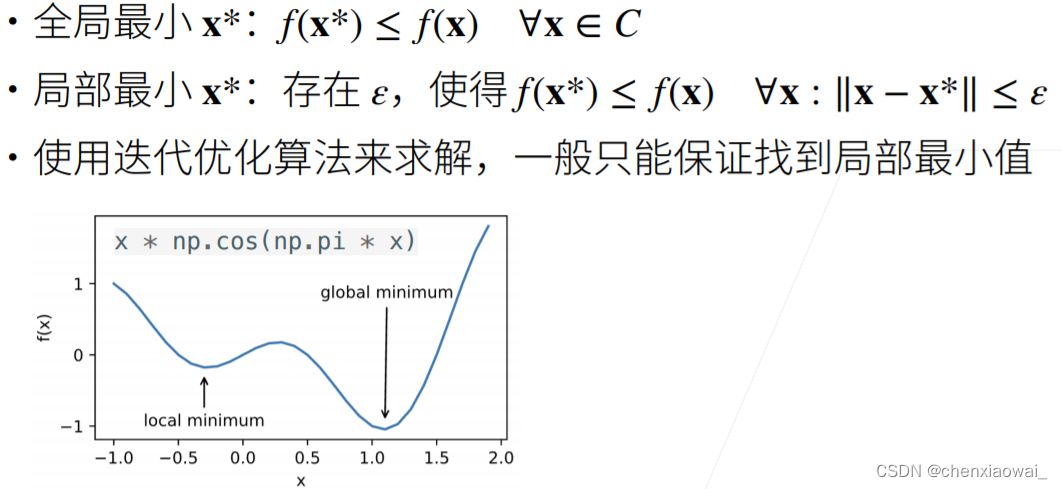
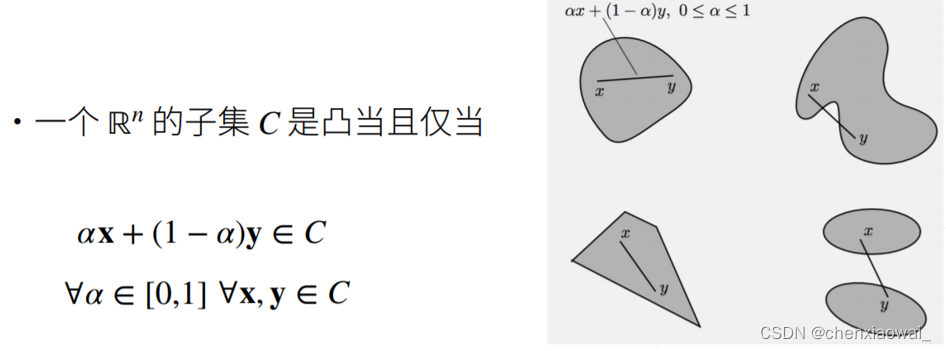
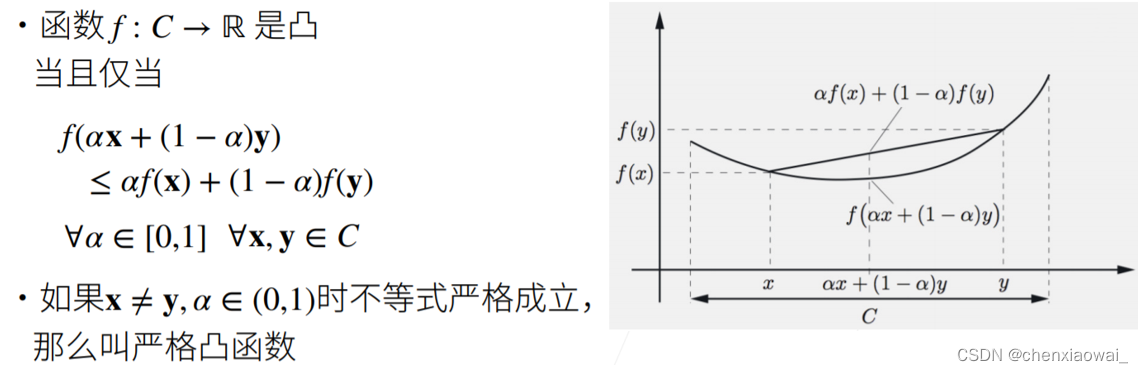
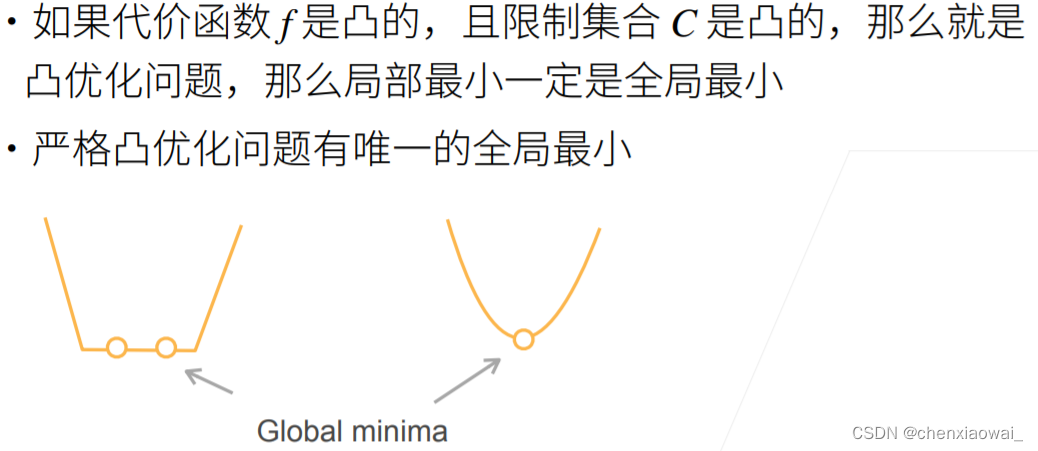
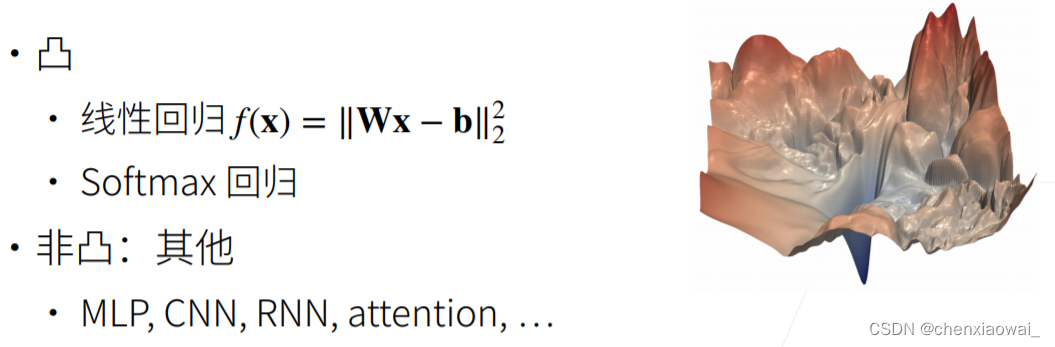
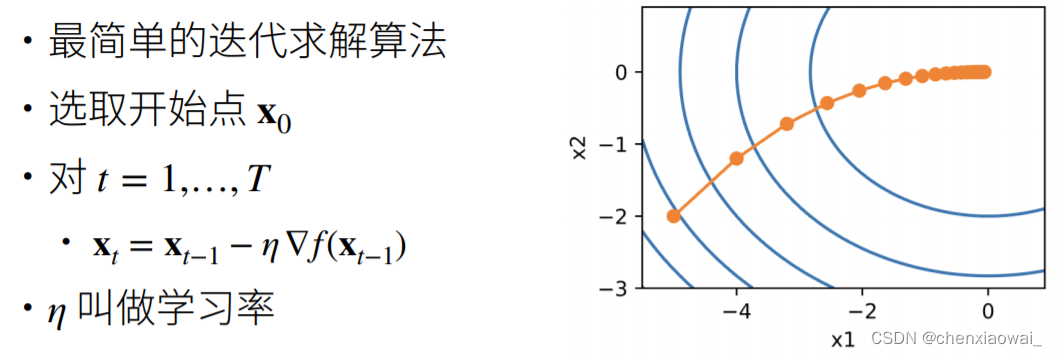
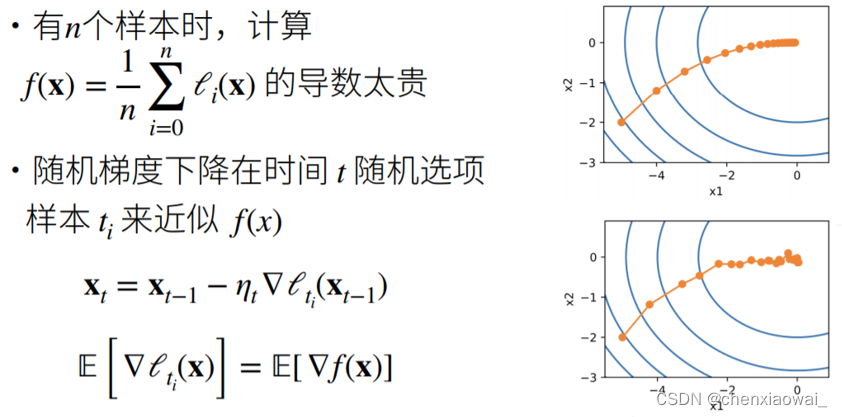


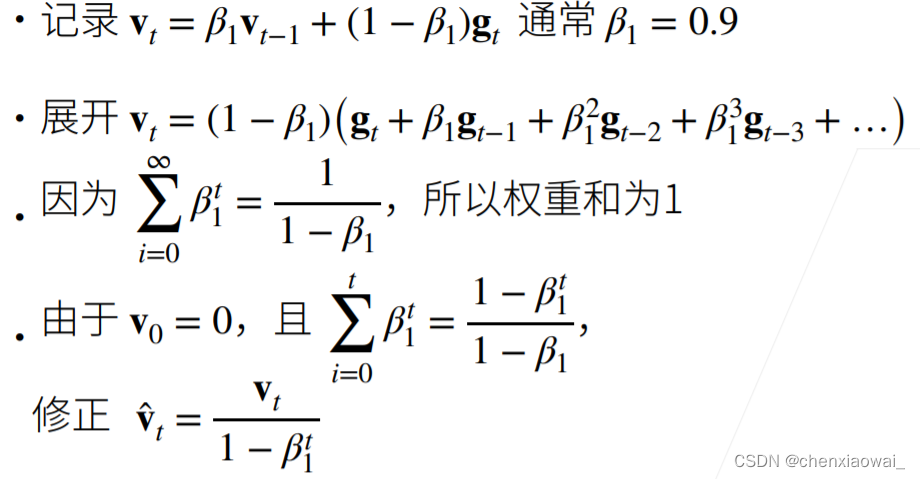


来源地址:https://blog.csdn.net/chenxiaowai_/article/details/124537066
--结束END--
本文标题: 【李沐】动手学深度学习 学习笔记
本文链接: https://www.lsjlt.com/news/385254.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0