Python 官方文档:入门教程 => 点击学习
文章目录 一、DataFrame 结构简介二、DataFrame 对象创建1. 使用普通列表创建2. 使用嵌套列表创建3 指定数值元素的数据类型为 float4. 字典嵌套列表创建5. 添加自
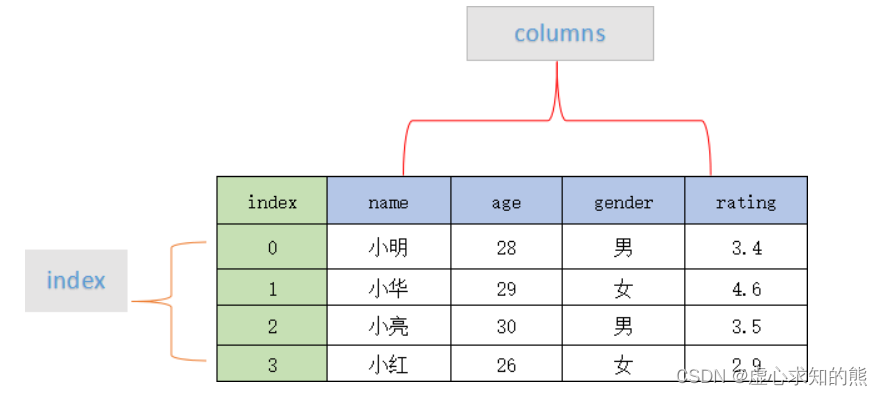
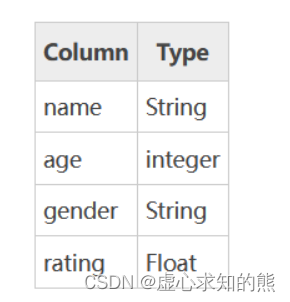
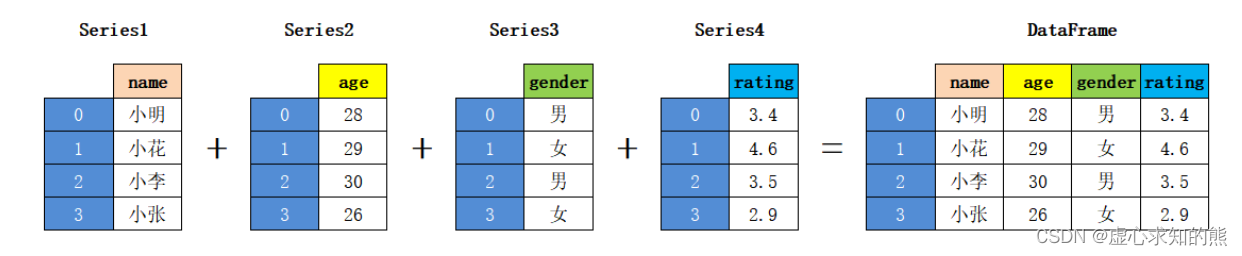
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)其参数含义如下:
import numpy as npimport pandas as pddata = [1,2,3,4,5]df = pd.DataFrame(data)print(df)# 0#0 1#1 2#2 3#3 4#4 5data = [1,2,3,4,5]df = pd.Series(data)print(df)#0 1#1 2#2 3#3 4#4 5#dtype: int64data = [['xiaowang',20],['Lily',30],['Anne',40]]df = pd.DataFrame(data)print(df)# 0 1#0 xiaowang 20#1 Lily 30#2 Anne 40data = [['xiaowang',20],['Lily',30],['Anne',40]]df = pd.DataFrame(data,columns=['Name','Age'])print(df)# Name Age#0 xiaowang 20#1 Lily 30#2 Anne 40data = [['xiaowang', 20, "男", 5000],['Lily', 30, "男", 8000],['Anne', 40, "女", 10000]]df = pd.DataFrame(data,columns=['Name','Age',"gender", "salary"], dtype=int)print(df)print(df['salary'].dtype)# Name Age gender salary#0 xiaowang 20 男 5000#1 Lily 30 男 8000#2 Anne 40 女 10000#float64data = {'Name':['关羽', '刘备', '张飞', '曹操'],'Age':[28,34,29,42]}df = pd.DataFrame(data)print(df)print(df.index)print(df.columns)# Name Age#0 关羽 28#1 刘备 34#2 张飞 29#3 曹操 42#RangeIndex(start=0, stop=4, step=1)#Index(['Name', 'Age'], dtype='object')data = {'Name':['关羽', '刘备', '张飞', '曹操'],'Age':[28,34,29,42]}index = ["rank1", "rank2", "rank3", "rank4"]df = pd.DataFrame(data, index=index)print(df)print(df.index)print(df.columns)# Name Age#rank1 关羽 28#rank2 刘备 34#rank3 张飞 29#rank4 曹操 42#Index(['rank1', 'rank2', 'rank3', 'rank4'], dtype='object')#Index(['Name', 'Age'], dtype='object')data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]df = pd.DataFrame(data, index=['first', 'second'])print(df)# a b c#first 1 2 NaN#second 5 10 20.0data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]df1 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b'])df2 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b1'])print("===========df1============")print(df1)print("===========df2============")print(df2)#===========df1============# a b#first 1 2#second 5 10#===========df2============# a b1#first 1 NaN#second 5 NaNd = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}df = pd.DataFrame(d)print(df)type(np.NaN)# one two#a 1.0 1#b 2.0 2#c 3.0 3#d NaN 4#floatdata = { "Name":pd.Series(['xiaowang', 'Lily', 'Anne']), "Age":pd.Series([20, 30, 40], dtype=float), "gender":pd.Series(["男", "男", "女"]), "salary":pd.Series([5000, 8000, 10000], dtype=float)}df = pd.DataFrame(data)df# Name Agegender salary#0xiaowang 20.0 男 5000.0#1 Lily 30.0 男 8000.0#2 Anne 40.0 女 10000.0data = {'Name':['关羽', '刘备', '张飞', '曹操'],'Age':[28,34,29,42]}index = ["rank1", "rank2", "rank3", "rank4"]df = pd.DataFrame(data, index=index)print(df)print("=========df['Name']:取得Name列===============")print(df['Name'])print("=========df['Age']:取得Age列===============")print(df['Age'])# Name Age#rank1 关羽 28#rank2 刘备 34#rank3 张飞 29#rank4 曹操 42#=========df['Name']:取得Name列===============#rank1 关羽#rank2 刘备#rank3 张飞#rank4 曹操#Name: Name, dtype: object#=========df['Age']:取得Age列===============#rank1 28#rank2 34#rank3 29#rank4 42#Name: Age, dtype: int64print("=========df[['Name', 'Age']]:df选取多列===============")print(df[['Name', 'Age']])#=========df[['Name', 'Age']]:df选取多列===============# Name Age#rank1 关羽 28#rank2 刘备 34#rank3 张飞 29#rank4 曹操 42print("=========df不能使用切片选取多列===============")print(df['Name': 'Age']) #=========df不能使用切片选取多列===============#Empty DataFrame#Columns: [Name, Age]#Index: []df[1]d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}df = pd.DataFrame(d)print(df)# one two#a 1.0 1#b 2.0 2#c 3.0 3#d NaN 4print ("====通过Series添加一个新的列====:")df['three']=pd.Series([10,20,30],index=['a','b','c'])print(df)#====通过Series添加一个新的列====:# one two three#a 1.0 1 10.0#b 2.0 2 20.0#c 3.0 3 30.0#d NaN 4 NaNprint ("======将已经存在的数据列相加运算,从而创建一个新的列:=======")df['four']=df['one']+df['three']print(df)#======将已经存在的数据列相加运算,从而创建一个新的列:=======# one two three four#a 1.0 1 10.0 11.0#b 2.0 2 20.0 22.0#c 3.0 3 30.0 33.0#d NaN 4 NaN NaNdf['error']=pd.Series([10,20,30],index=['b','a','s3'])print(df)# one two three four error#a 1.0 1 10.0 11.0 20.0#b 2.0 2 20.0 22.0 10.0#c 3.0 3 30.0 33.0 NaN#d NaN 4 NaN NaN NaNdf.insert(loc, column, value, allow_duplicates=False)info=[['王杰',18],['李杰',19],['刘杰',17]]df=pd.DataFrame(info,columns=['name','age'])print(df)# name age#0 王杰 18#1 李杰 19#2 刘杰 17print("=====df.insert插入数据:=======")print(df)#=====df.insert插入数据:=======# name score age#0 王杰 91 18#1 李杰 90 19#2 刘杰 75 17df.insert(1,column='score',value=[80,70,90],allow_duplicates=True)print(df)# name score score age#0 王杰 80 91 18#1 李杰 70 90 19#2 刘杰 90 75 17df['score']#scorescore#08091#17090#29075df.insert(1,column='score',value=[80,70,90])# 错误 cannot insert name, already existsd = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']), 'three' : pd.Series([10,20,30], index=['a','b','c'])}df = pd.DataFrame(d)print ("Our dataframe is:")print(df)#Our dataframe is:# one two three#a 1.0 1 10.0#b 2.0 2 20.0#c 3.0 3 30.0#d NaN 4 NaNdel df['one']print("=======del df['one']=========")print(df)#=======del df['one']=========# two three#a 1 10.0#b 2 20.0#c 3 30.0#d 4 NaNres_pop = df.pop('two')print("=======df.pop('two')=========")print(df)print("=======res_pop = df.pop('two')=========")print(res_pop)#=======df.pop('two')=========# three#a 10.0#b 20.0#c 30.0#d NaN#=======res_pop = df.pop('two')=========#a 1#b 2#c 3#d 4#Name: two, dtype: int64来源地址:https://blog.csdn.net/weixin_45891612/article/details/129118246
--结束END--
本文标题: Python 之 Pandas DataFrame 数据类型的简介、创建的列操作
本文链接: https://www.lsjlt.com/news/385273.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0