Python 官方文档:入门教程 => 点击学习
本文主要讲述了在windows10环境下使用yolov3训练模型的具体步骤 本文主要包括以下内容: 一、程序下载与准备(1)yolov3下载(2)训练集文件夹创建(3)预训练权重下载 二、
本文主要讲述了在windows10环境下使用yolov3训练模型的具体步骤
软件准备:anaconda3,PyCharm
yolov3的GitHub地址:yolov3
1.可以点击此处选择自己想要下载的版本(本文以9.5.0为例)
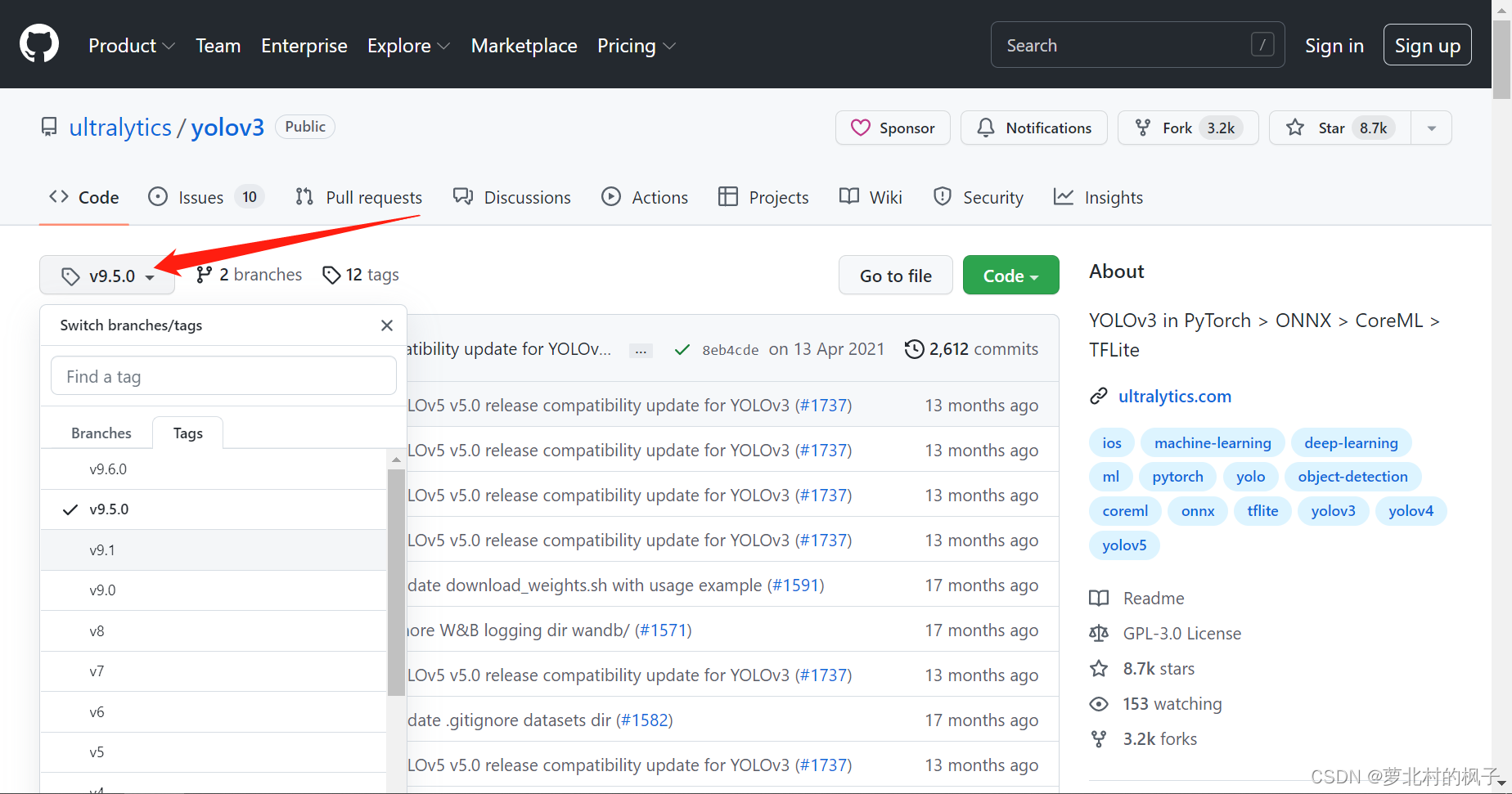
2.点击左边的download即可下载压缩包
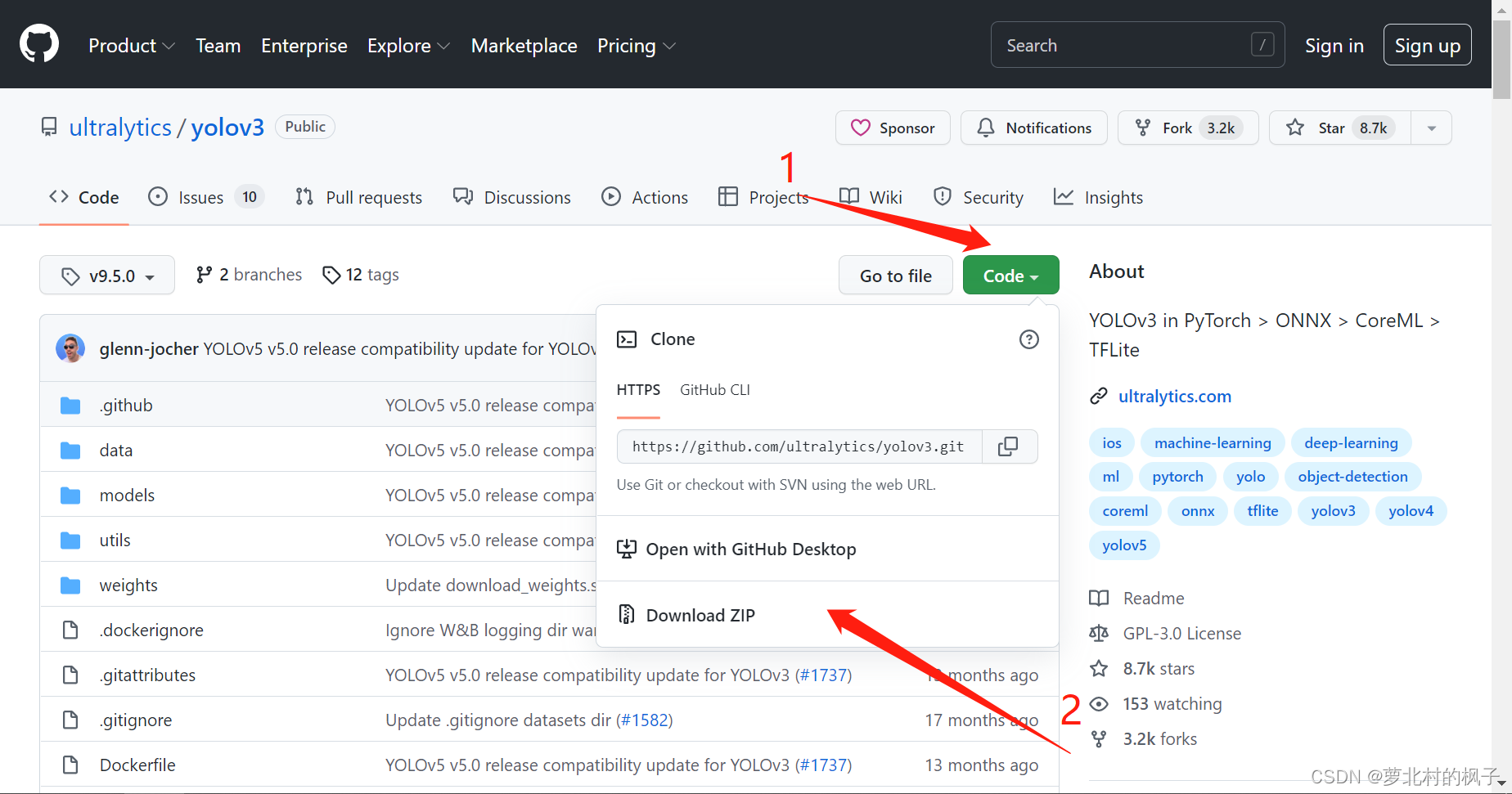
3.下载并解压后的文件夹如图所示:

在pycharm中打开工程目录如下图所示:
在yolov3-9.5.0工程文件夹下,新建一个名称为VOCdevkit的文件夹
2.在VOCdevkit文件夹下,新建三个名称分别为images,labels,VOC2007的文件夹
3.在images和labels文件夹下分别新建两个名为train和val的文件夹
4.在VOC2007文件夹下新建三个名称分别为Annotations,JPEGImages,YOLOLabels的文件夹
如下图所示:
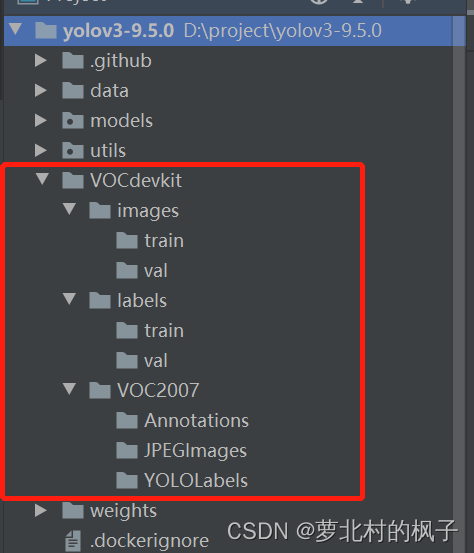
Annotations:xml标签文件夹
JPEGImages:图片文件夹
YOLOLabels:txt标签文件夹(yolov训练需要txt格式的标签文件)
加载预训练权重进行网络的训练可以减小缩短网络训练时间,并且提高精度。预训练权重越大,训练出来的精度就会越高,但是其检测的速度就会越慢。
预训练权重下载地址:yolov5权重
本文在此处选择下载的是yolov3-tiny.pt
(不同的预训练权重对应着不同的网络层数,我们需要根据预训练权重使用对应的yaml文件,即在之后的训练中需要使用名称为yolov3-tiny.yaml的文件)

2.将下载好的权重文件保存在weights文件夹中

windows10系统中通过anaconda安装pytorch的具体步骤可以阅读此篇博客:
anaconda安装pytorch(anaconda3,Windows10)
在上一步中我们通过anaconda安装了pytorch,并将其导入了pycharm,下面我们来将名称为pyotch环境中的编译器应用到工程文件中去。
1.点击文件→设置
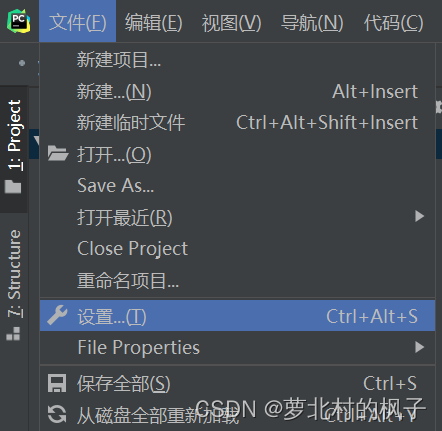
2.选择Project Interpreter,选择刚刚导入pycharm的pytorch环境,点击应用,最后点击确认
这样我们就成功将名称为pytorch环境中的编译器应用到了yolov3-9.5.0工程中
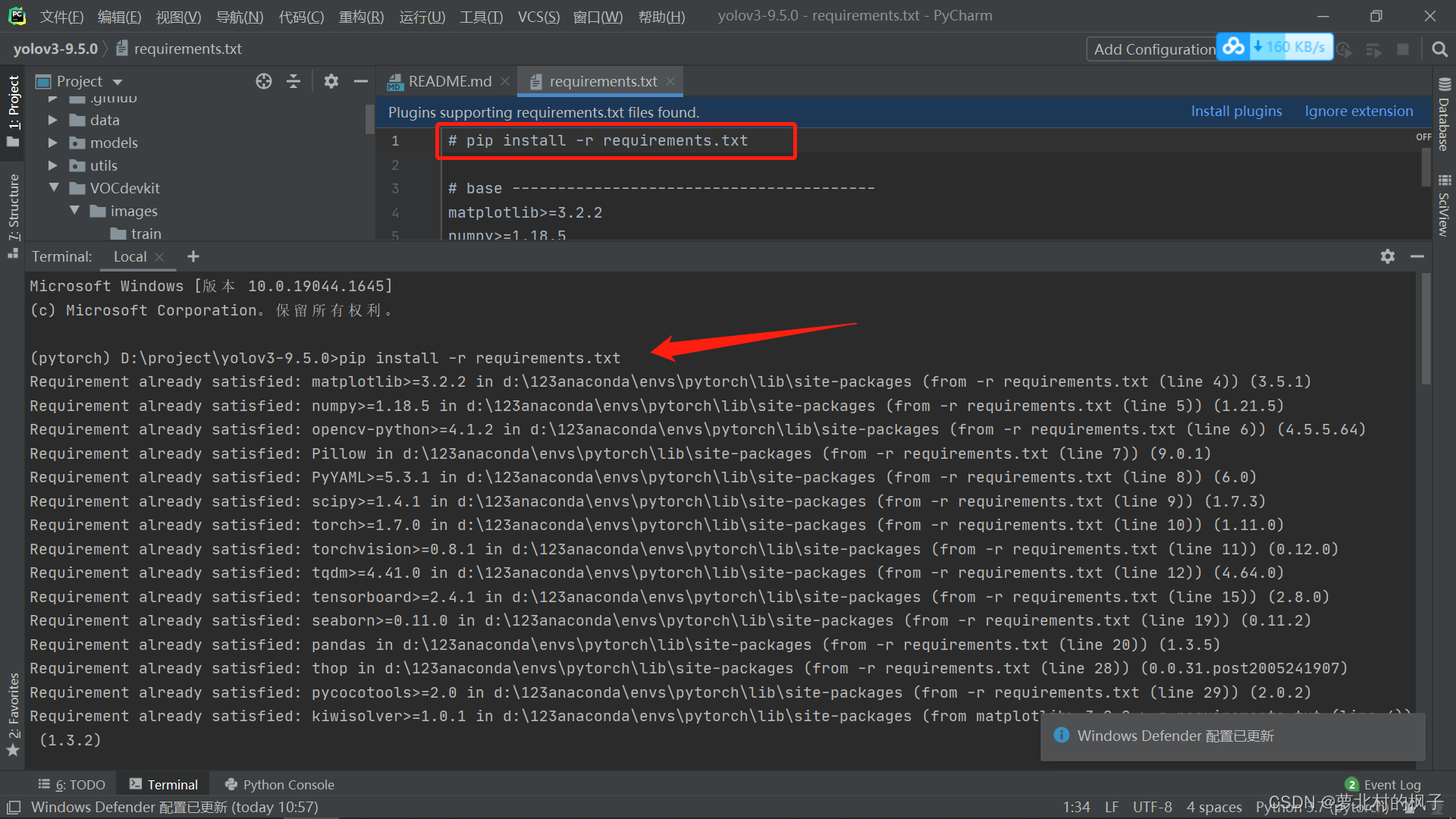
接下来对工程所需的依赖包进行安装,首先打开terminal
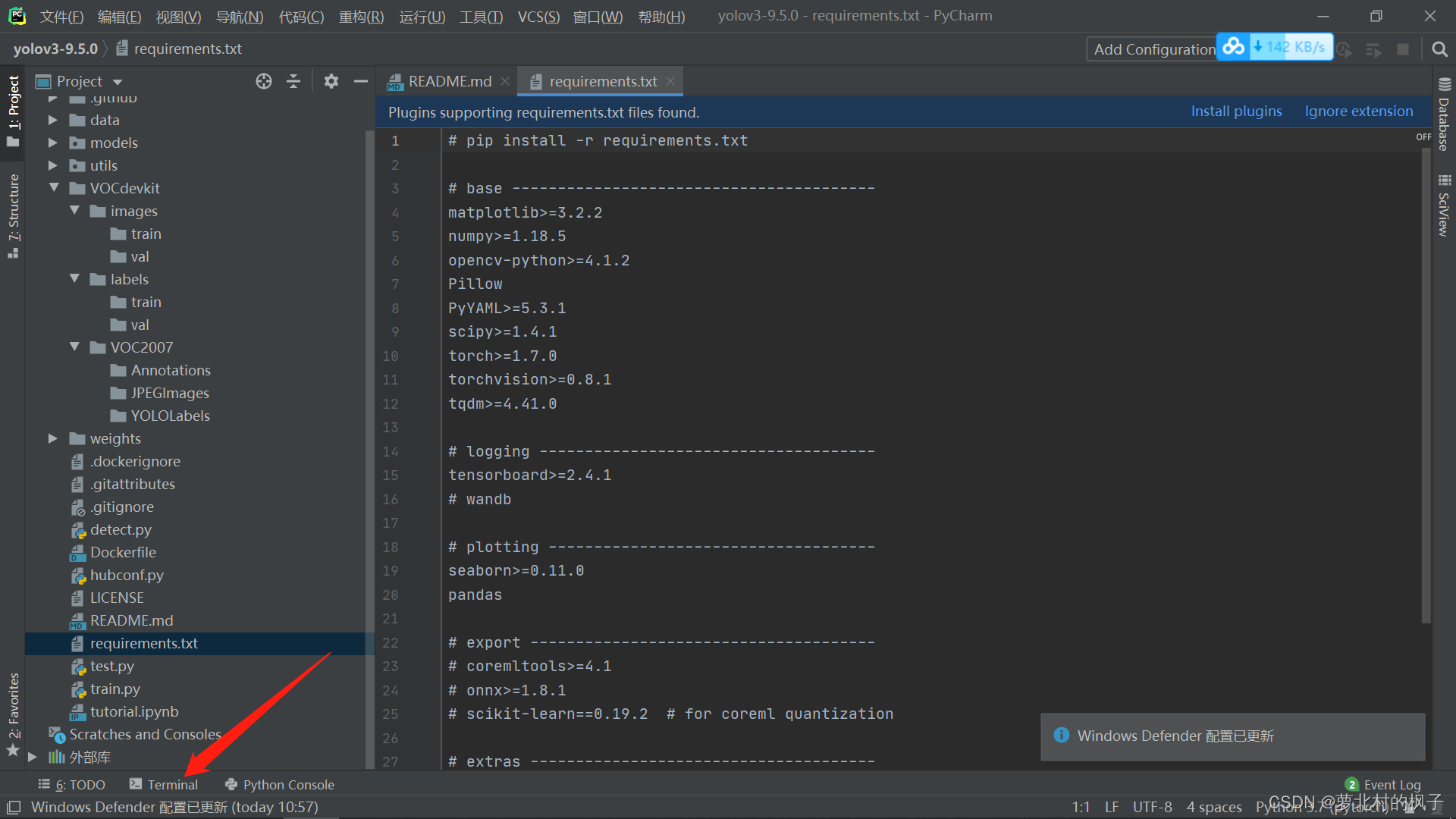
2.复制requirements.txt文件中的命令行:
pip install -r requirements.txt粘贴在terminal中,并按回车键运行命令行,requirements中的依赖包就开始安装了
参考此篇博客中的环境搭建可能遇到的问题部分:
目标检测—基于Yolov5的目标检测项目(学习笔记)
(如有其它错误会后续更新)
使用labelimg来制作我们自己的数据集,labelimg的安装和基本操作可以阅读此篇博客:
数据集制作——使用labelimg制作数据集
yolov网络训练所需要的文件格式是txt格式的
如果通过labelimg给数据集打标签时输出为xml格式,可以通过代码将xml格式的标注文件转换为txt格式的标注文件;
如果输出为txt格式的标签文件则可以直接使用。同时训练自己的yolov3检测模型的时候,数据集需要划分为训练集和验证集,也可以通过相关代码实现。
本文以识别两个标签"person"和"har"为例,同时本文的数据集是以基于识别人带安全帽的数据集为例
本文以使用labelimg标注xml格式的标签文件为例:
(打标签过程省略)
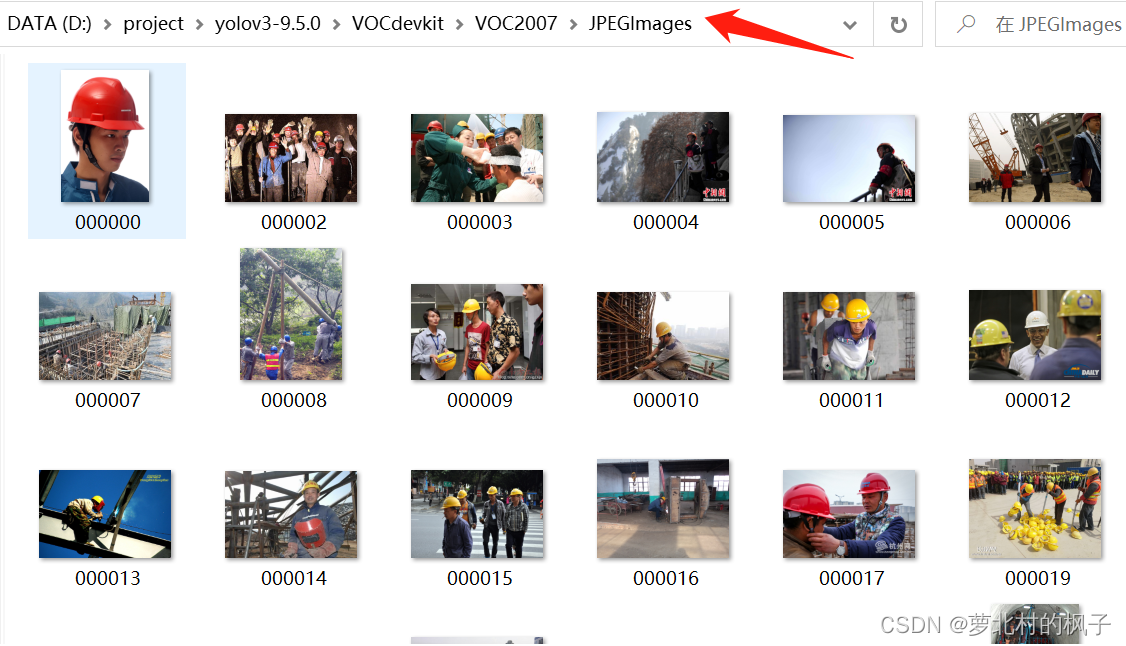
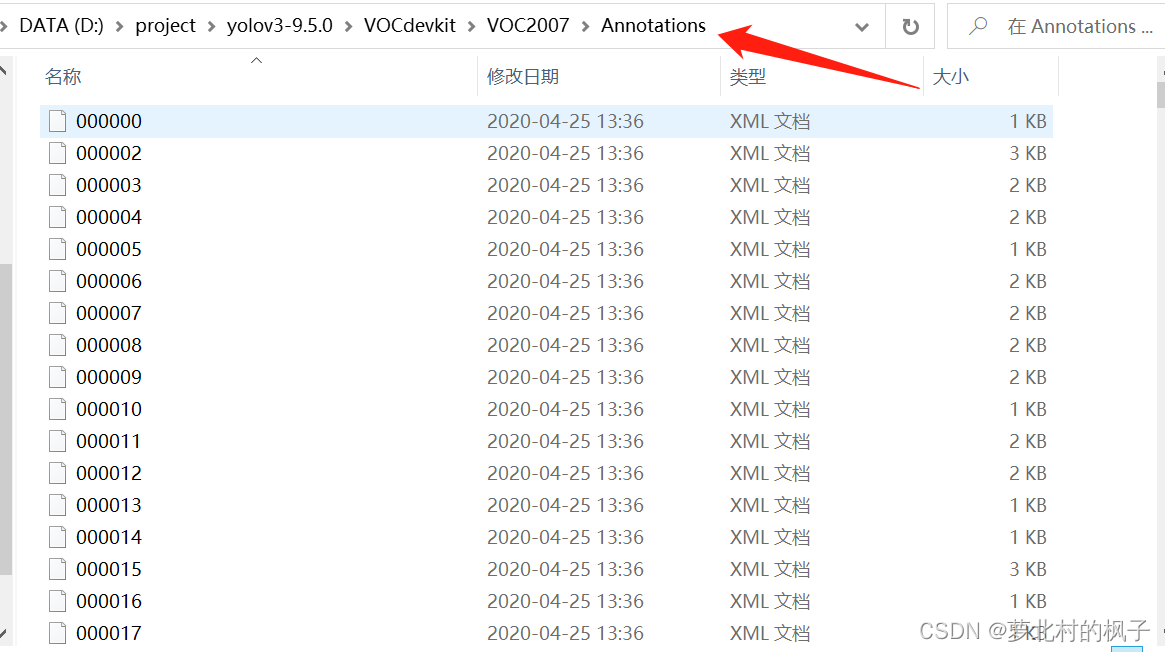
1.首先将图片数据集存放在JPEGImages文件夹下;将xml标签文件存放在Annotations文件夹下;即:
JPEGImages里面存放着图片文件
Annotations里面存放着xml格式的标签
如图所示:
2.在工程中新建一个python的file,复制粘贴下面的代码并运行,即可将数据集划分为训练集和验证集
(注意将下面代码中的标签种类classes = [“hat”, “person”] 修改为自己的标签,下面代码中训练集占比TRAIN_RATIO = 80为80%)
import xml.etree.ElementTree as ETimport pickleimport osfrom os import listdir, getcwdfrom os.path import joinimport randomfrom shutil import copyfile classes = ["hat", "person"] #标签种类#classes=["ball"] TRaiN_RATIO = 80 #训练集占比 def clear_hidden_files(path): dir_list = os.listdir(path) for i in dir_list: abspath = os.path.join(os.path.abspath(path), i) if os.path.isfile(abspath): if i.startswith("._"): os.remove(abspath) else: clear_hidden_files(abspath) def convert(size, box): dw = 1./size[0] dh = 1./size[1] x = (box[0] + box[1])/2.0 y = (box[2] + box[3])/2.0 w = box[1] - box[0] h = box[3] - box[2] x = x*dw w = w*dw y = y*dh h = h*dh return (x,y,w,h) def convert_annotation(image_id): in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id) out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w') tree=ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w,h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') in_file.close() out_file.close() wd = os.getcwd()wd = os.getcwd()data_base_dir = os.path.join(wd, "VOCdevkit/")if not os.path.isdir(data_base_dir): os.mkdir(data_base_dir)work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")if not os.path.isdir(work_sapce_dir): os.mkdir(work_sapce_dir)annotation_dir = os.path.join(work_sapce_dir, "Annotations/")if not os.path.isdir(annotation_dir): os.mkdir(annotation_dir)clear_hidden_files(annotation_dir)image_dir = os.path.join(work_sapce_dir, "JPEGImages/")if not os.path.isdir(image_dir): os.mkdir(image_dir)clear_hidden_files(image_dir)yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")if not os.path.isdir(yolo_labels_dir): os.mkdir(yolo_labels_dir)clear_hidden_files(yolo_labels_dir)yolov5_images_dir = os.path.join(data_base_dir, "images/")if not os.path.isdir(yolov5_images_dir): os.mkdir(yolov5_images_dir)clear_hidden_files(yolov5_images_dir)yolov5_labels_dir = os.path.join(data_base_dir, "labels/")if not os.path.isdir(yolov5_labels_dir): os.mkdir(yolov5_labels_dir)clear_hidden_files(yolov5_labels_dir)yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")if not os.path.isdir(yolov5_images_train_dir): os.mkdir(yolov5_images_train_dir)clear_hidden_files(yolov5_images_train_dir)yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")if not os.path.isdir(yolov5_images_test_dir): os.mkdir(yolov5_images_test_dir)clear_hidden_files(yolov5_images_test_dir)yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")if not os.path.isdir(yolov5_labels_train_dir): os.mkdir(yolov5_labels_train_dir)clear_hidden_files(yolov5_labels_train_dir)yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")if not os.path.isdir(yolov5_labels_test_dir): os.mkdir(yolov5_labels_test_dir)clear_hidden_files(yolov5_labels_test_dir) train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')train_file.close()test_file.close()train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')list_imgs = os.listdir(image_dir) # list image filesprob = random.randint(1, 100)print("Probability: %d" % prob)for i in range(0,len(list_imgs)): path = os.path.join(image_dir,list_imgs[i]) if os.path.isfile(path): image_path = image_dir + list_imgs[i] voc_path = list_imgs[i] (nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path)) (voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path)) annotation_name = nameWithoutExtention + '.xml' annotation_path = os.path.join(annotation_dir, annotation_name) label_name = nameWithoutExtention + '.txt' label_path = os.path.join(yolo_labels_dir, label_name) prob = random.randint(1, 100) print("Probability: %d" % prob) if(prob < TRAIN_RATIO): # train dataset if os.path.exists(annotation_path): train_file.write(image_path + '\n') convert_annotation(nameWithoutExtention) # convert label copyfile(image_path, yolov5_images_train_dir + voc_path) copyfile(label_path, yolov5_labels_train_dir + label_name) else: # test dataset if os.path.exists(annotation_path): test_file.write(image_path + '\n') convert_annotation(nameWithoutExtention) # convert label copyfile(image_path, yolov5_images_test_dir + voc_path) copyfile(label_path, yolov5_labels_test_dir + label_name)train_file.close()test_file.close()运行此代码,过程如下图所示:(注意数据集文件夹名称要和上文中训练集文件夹创建部分一样,就可以直接复制粘贴运行)
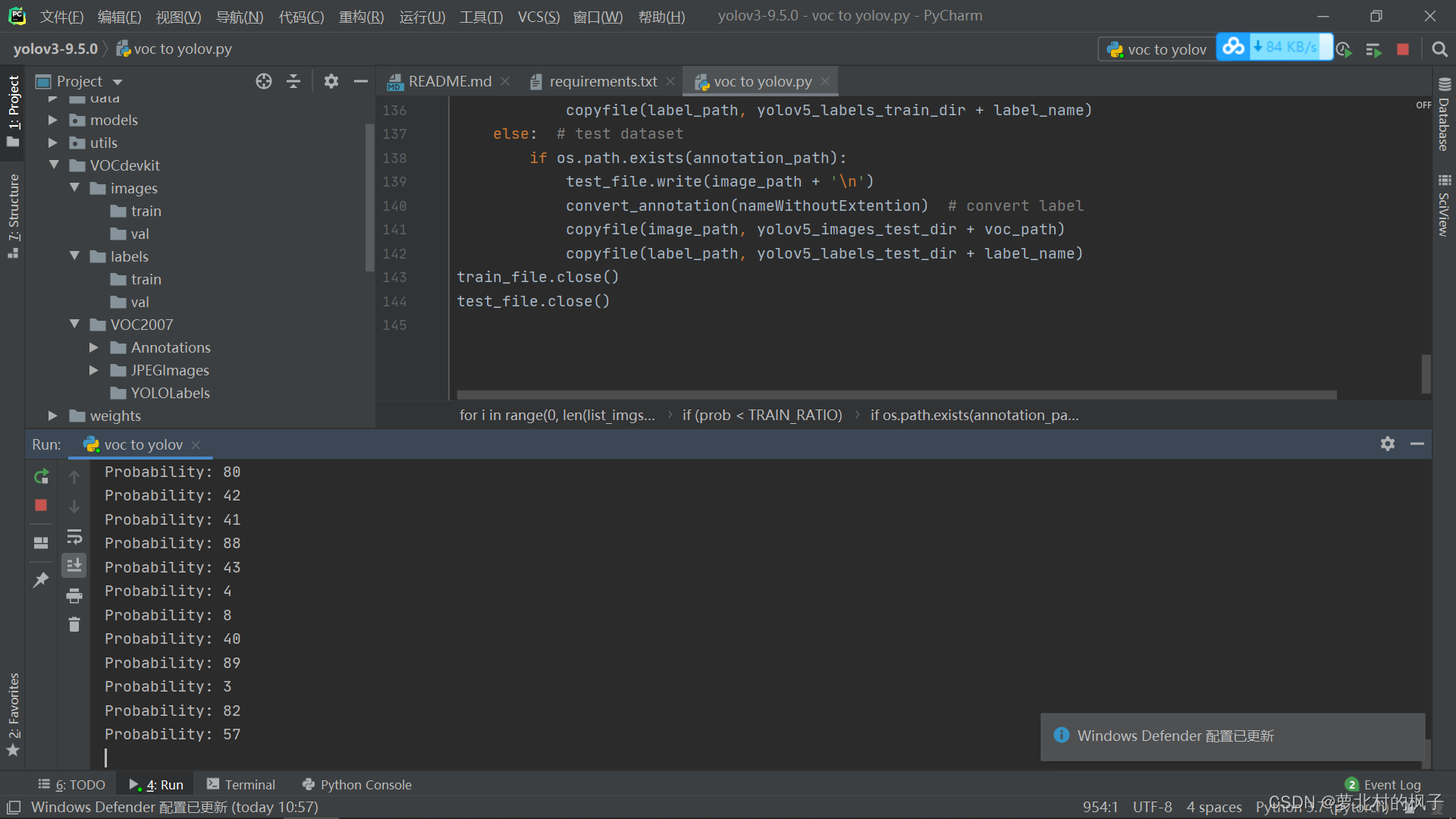
然后就可以在images和labels文件夹中分别看到已经划分好的图片数据集和标签数据集
找到data目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名,方便后续操作,本文此处修改为hat.yaml
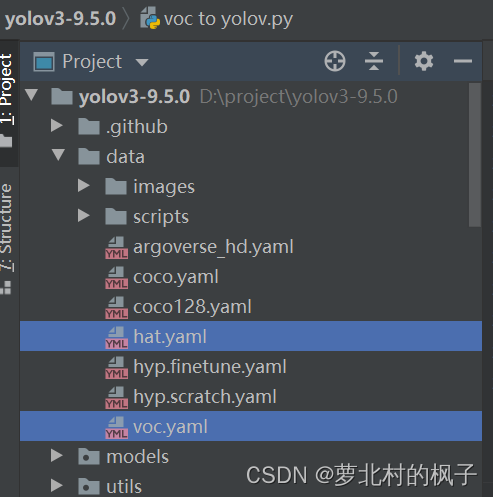
2.点击hat.yaml文件,修改以下部分:
注释掉语句:download: bash data/scripts/get_voc.sh
修改train和val地址为自己电脑中数据集地址
修改number of classes数值为自己数据集标签的种类个数(本文标签为两类)
修改class names为自己自己数据集标签的种类(本文为hat和person)
前面选择下载的权重文件为yolov3-tiny.pt,我们需要使用与之相对应的模型配置yaml文件
找到models目录下的yolov3-tiny.yaml文件,将该文件复制一份,将复制的文件重命名,方便后续操作,本文此处修改为yolov3-tiny_hat.yaml
2.打开yolov3-tiny_hat.yaml文件,将number of classes改为数据集标签的种类(本文数据集识别种类为两类)

主要修改以下五个函数:
–weights:初始化的权重文件的路径地址
–cfg:模型yaml文件的路径地址
–data:数据yaml文件的路径地址
–epochs:训练次数
–batch-size:一轮训练的文件个数
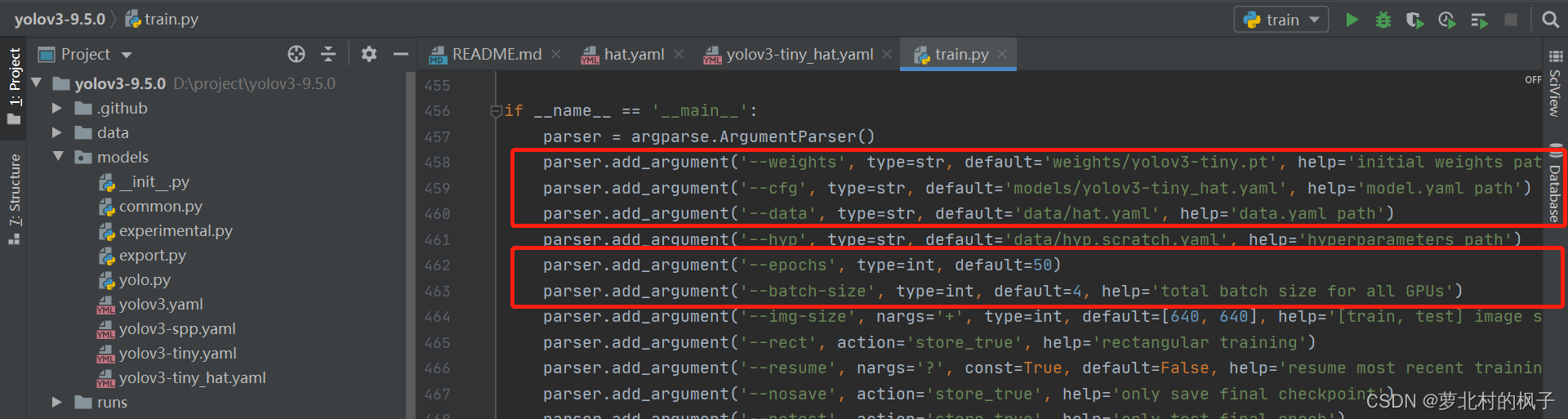
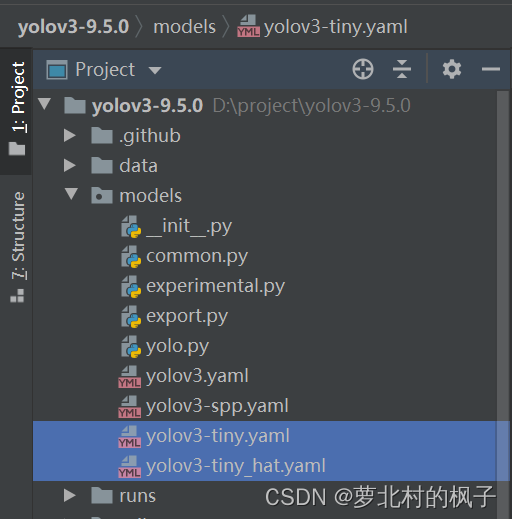
1.打开train.py,作以下修改:
修改"–weights"中权重文件地址为文件yolov3-tiny.pt的地址
修改"–cfg"中模型yaml文件的地址为文件yolov3-tiny_hat.yaml的地址
修改"–data"中数据yaml文件的地址为文件hat.yaml的地址
parser.add_argument('--weights', type=str, default='weights/yolov3-tiny.pt', help='initial weights path') parser.add_argument('--cfg', type=str, default='models/yolov3-tiny_hat.yaml', help='model.yaml path') parser.add_argument('--data', type=str, default='data/hat.yaml', help='data.yaml path')如下图所示:
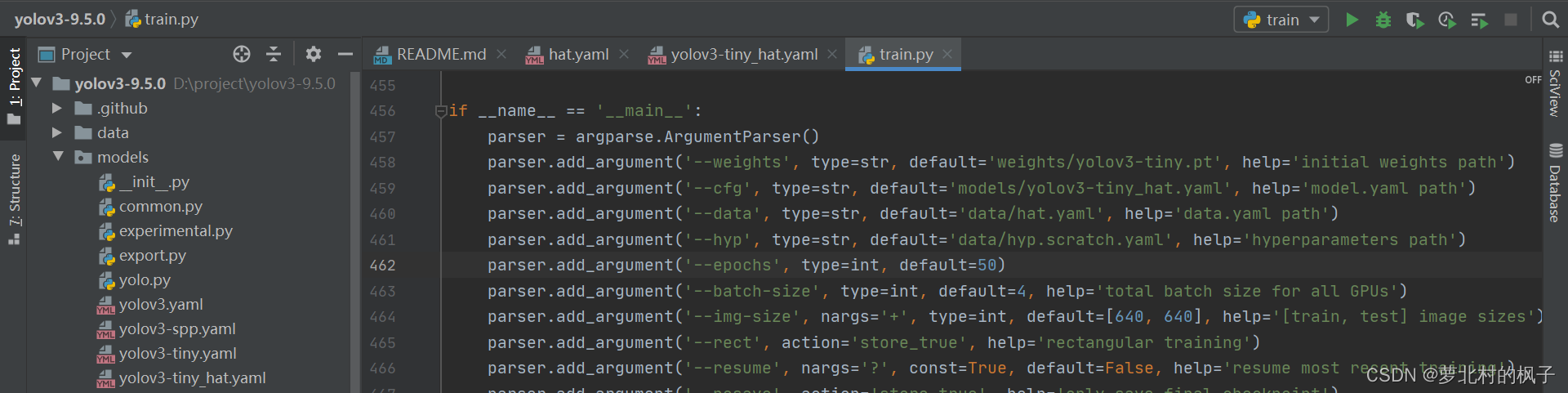
" --epochs"和"–batch-size"的数值可以根据GPU情况自行设置
运行train.py,开始训练模型
在加载完train和val的数据集之后,可以看到模型开始训练~
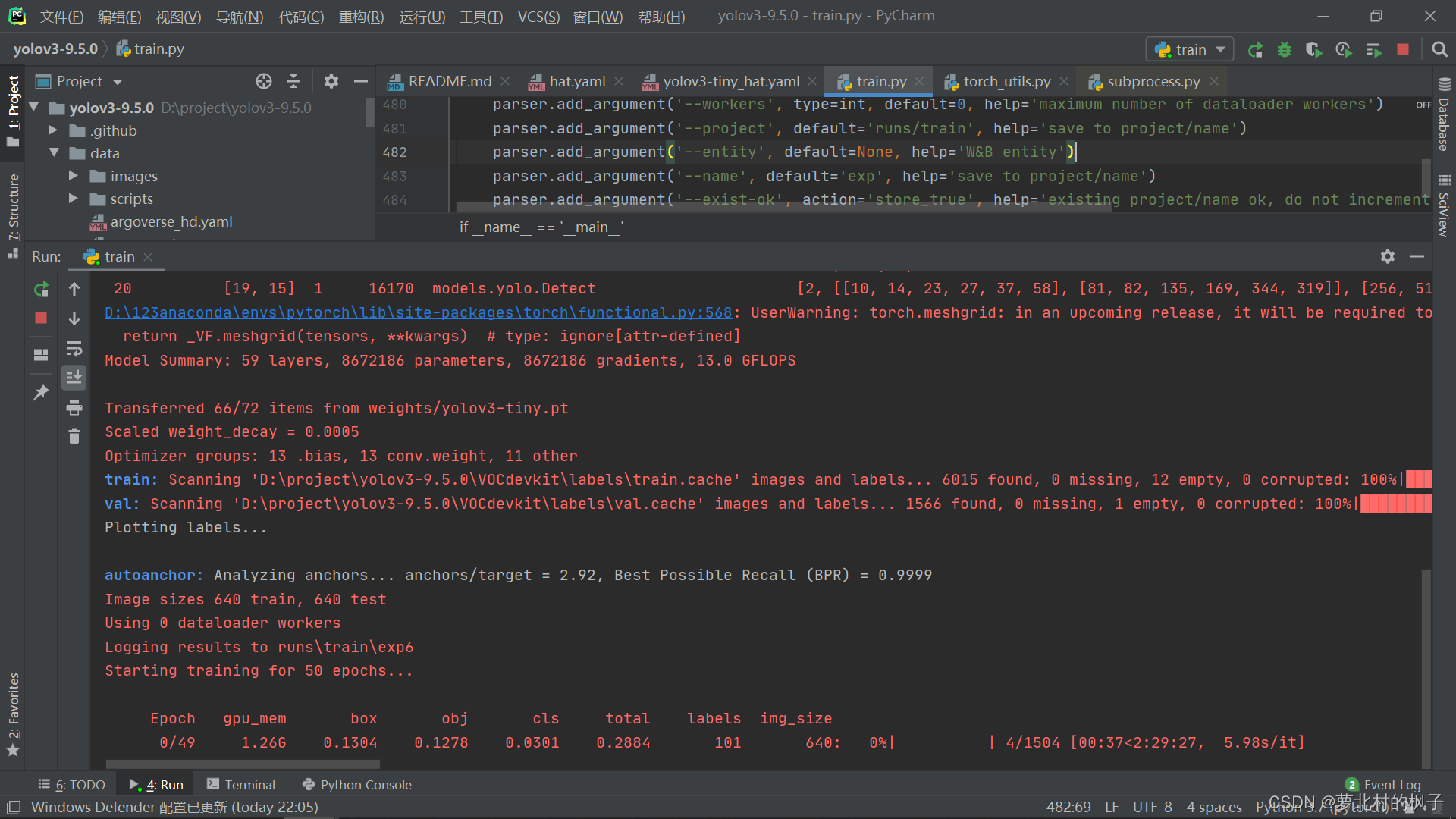
如下图所示:
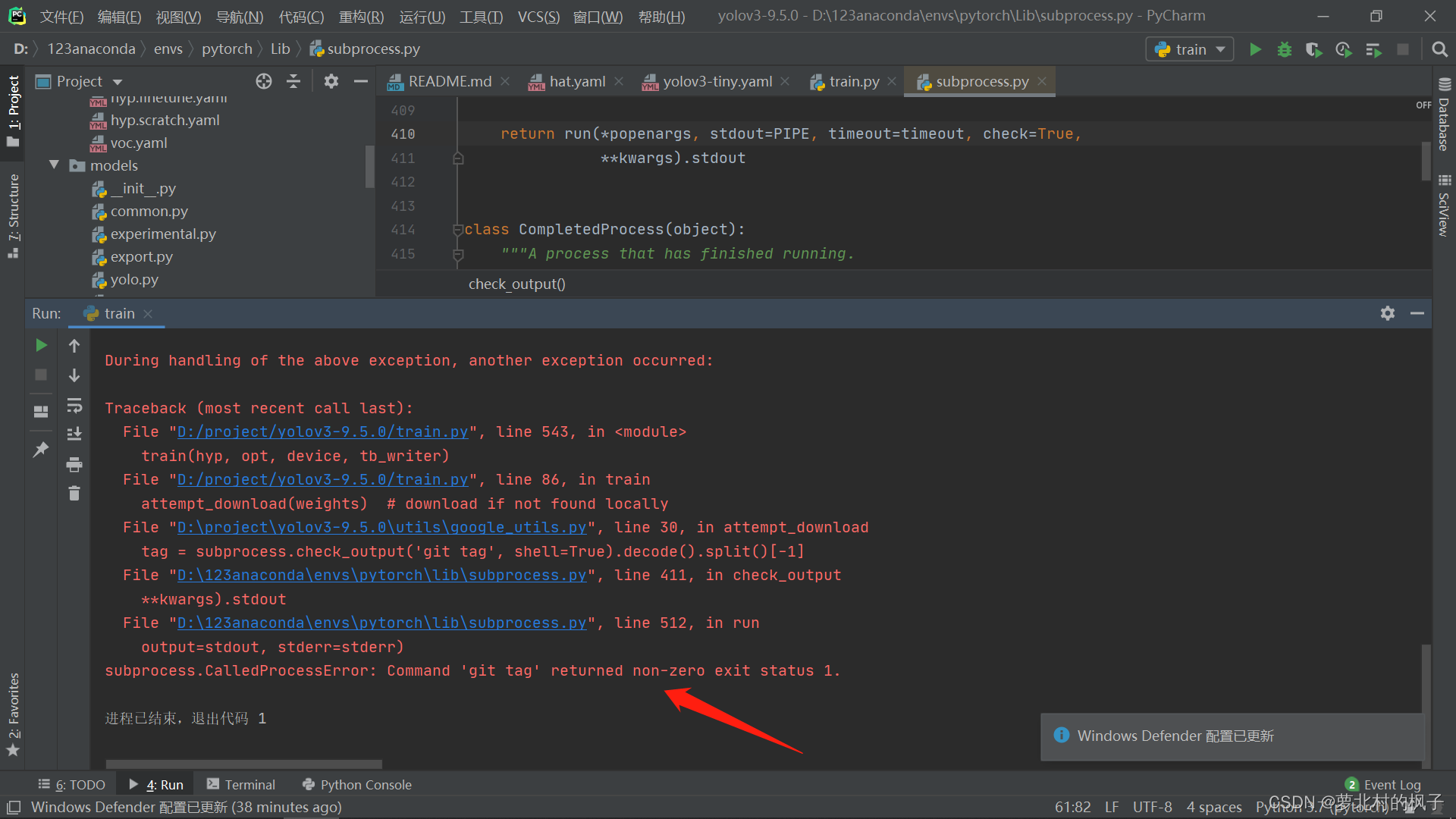
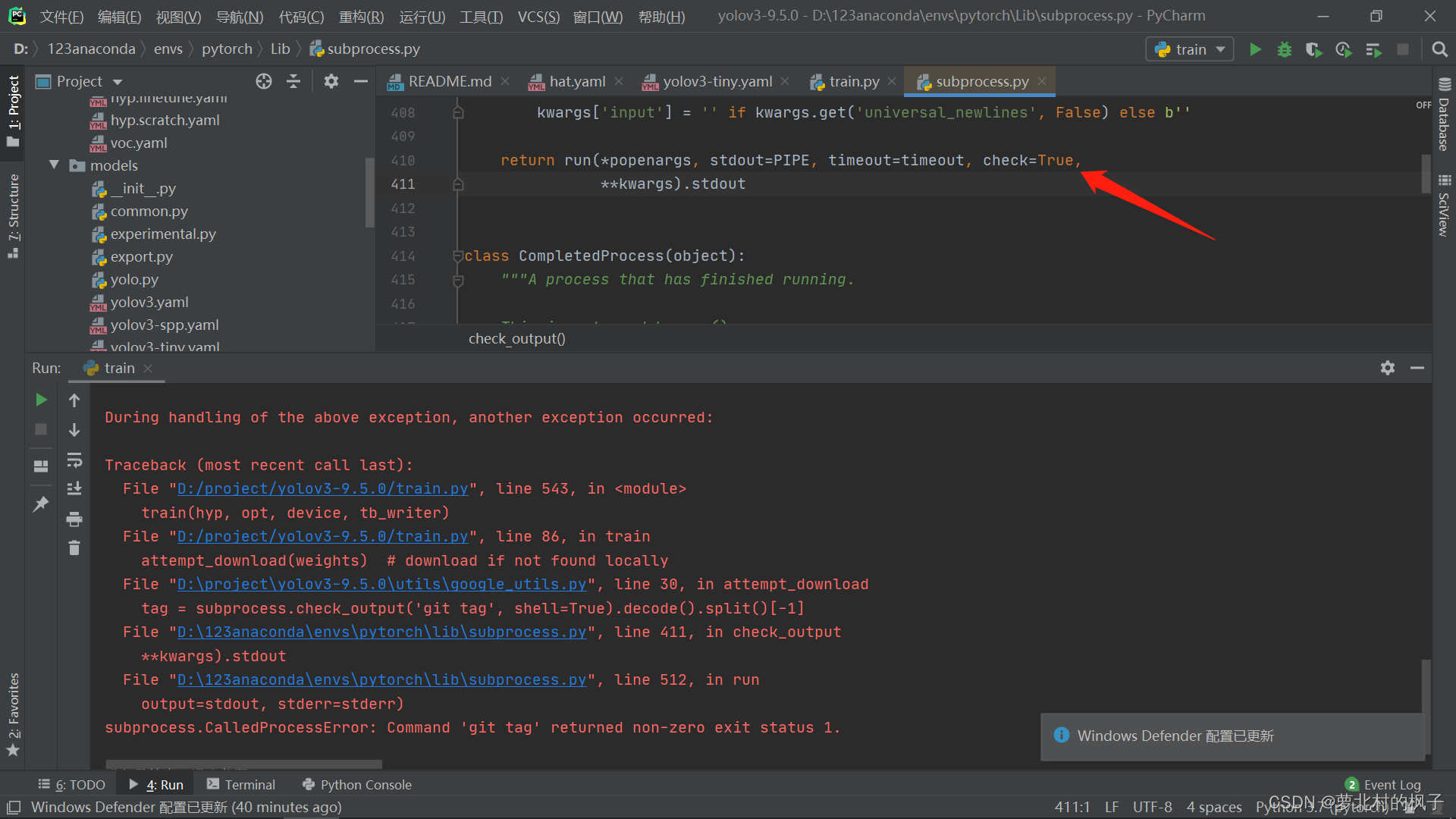
解决方法:
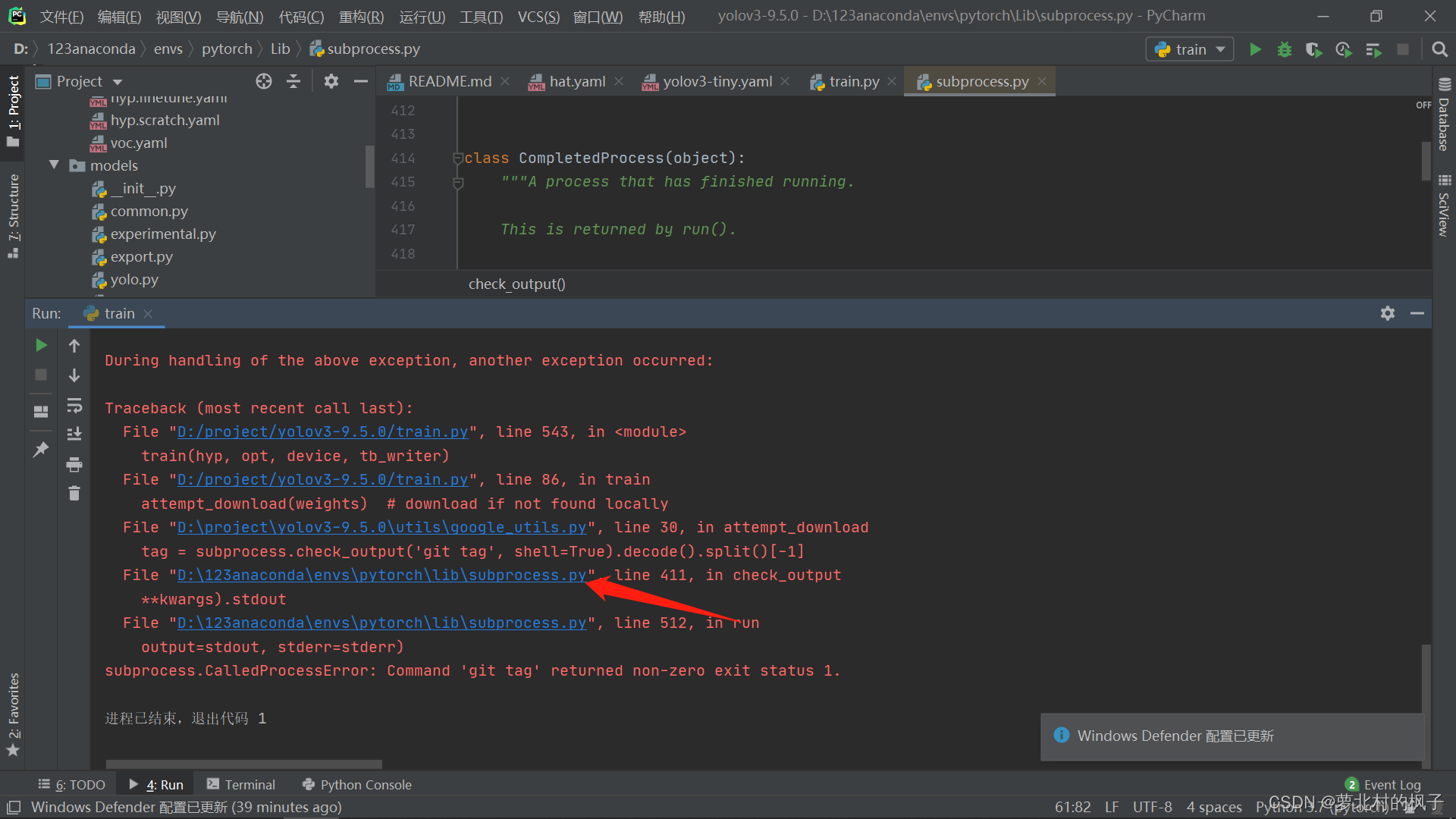
打开subprocess.py文件,在第410行,将check值修改为False
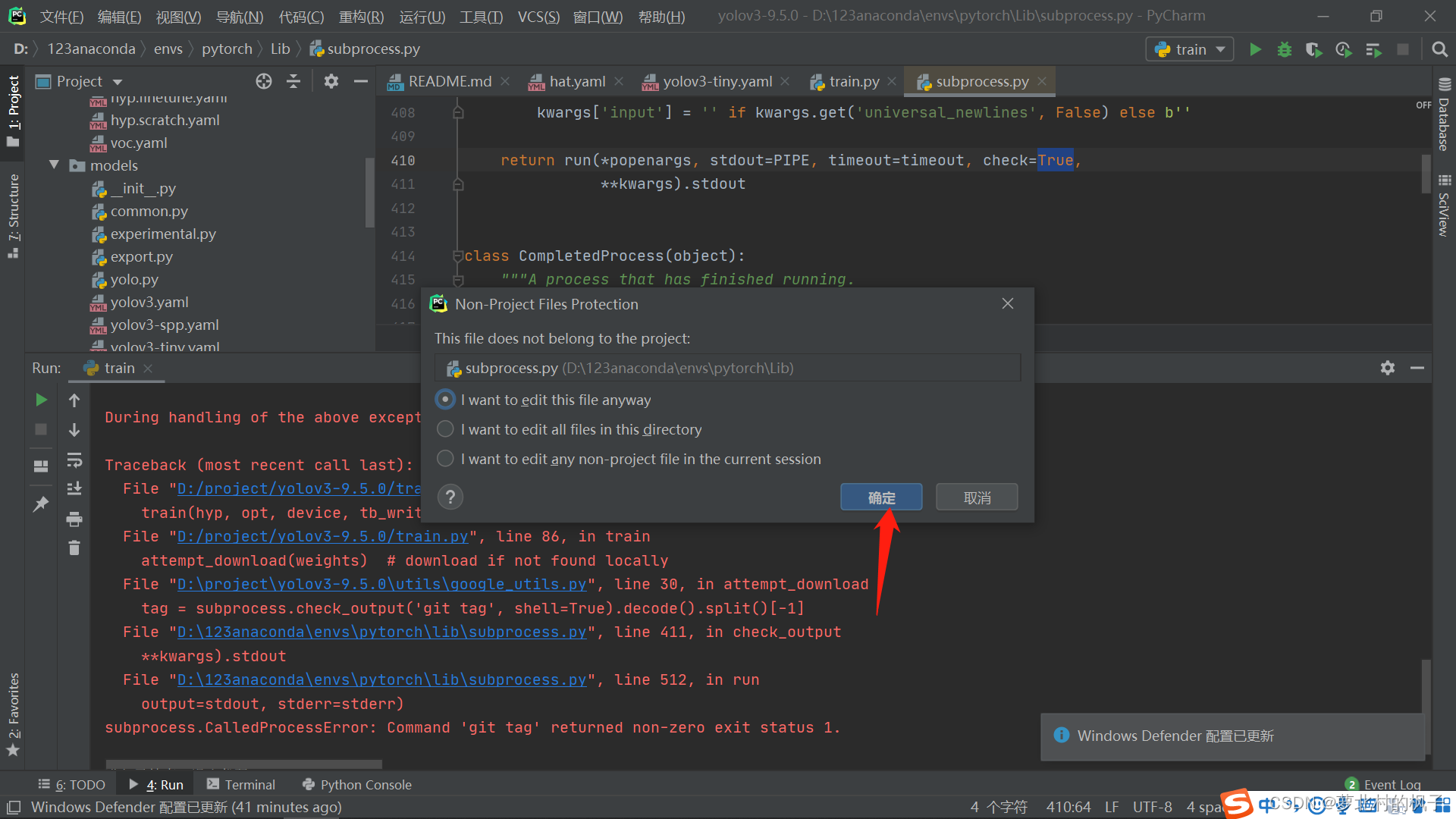
点击确定即可
如下图所示:
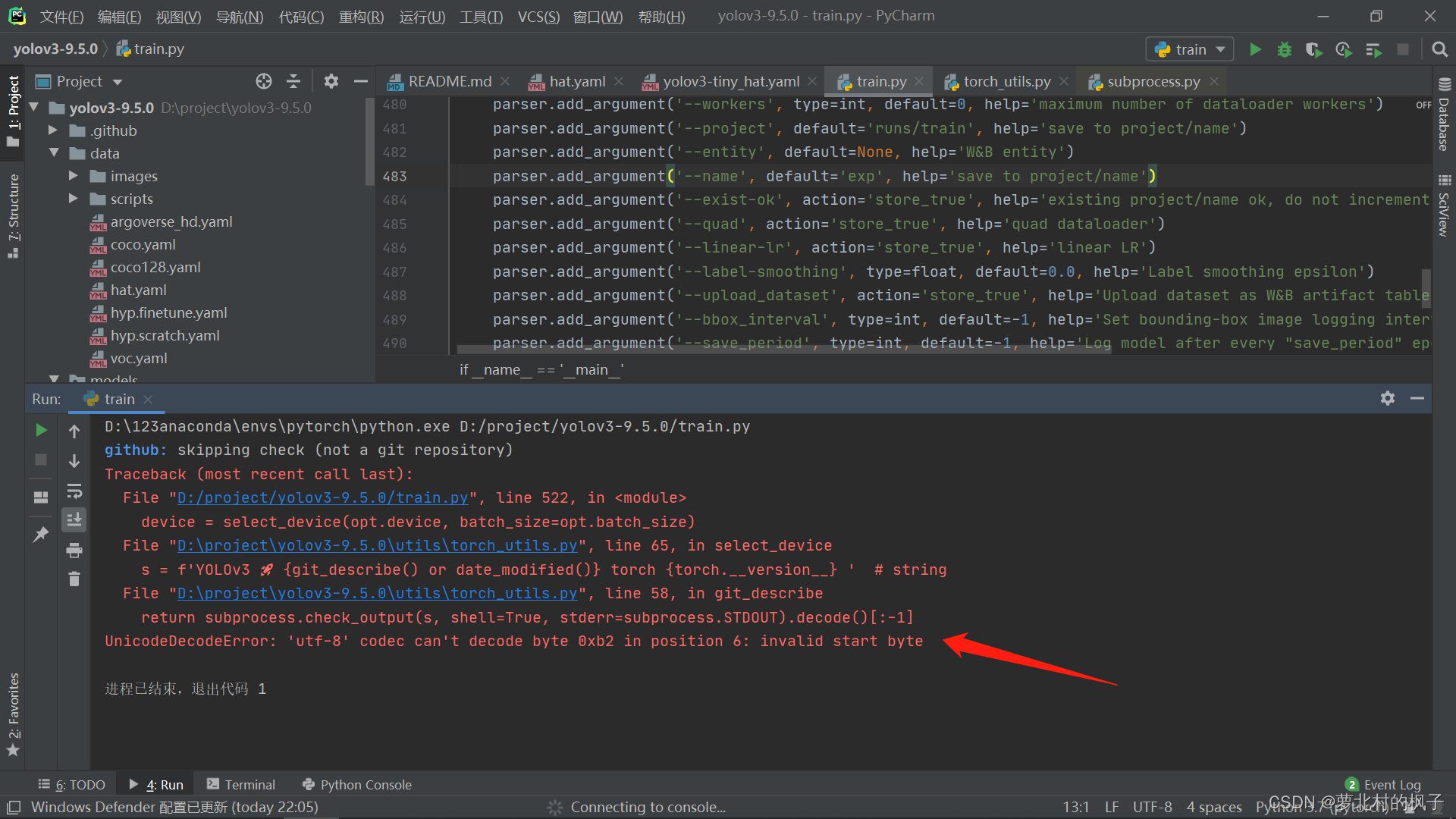
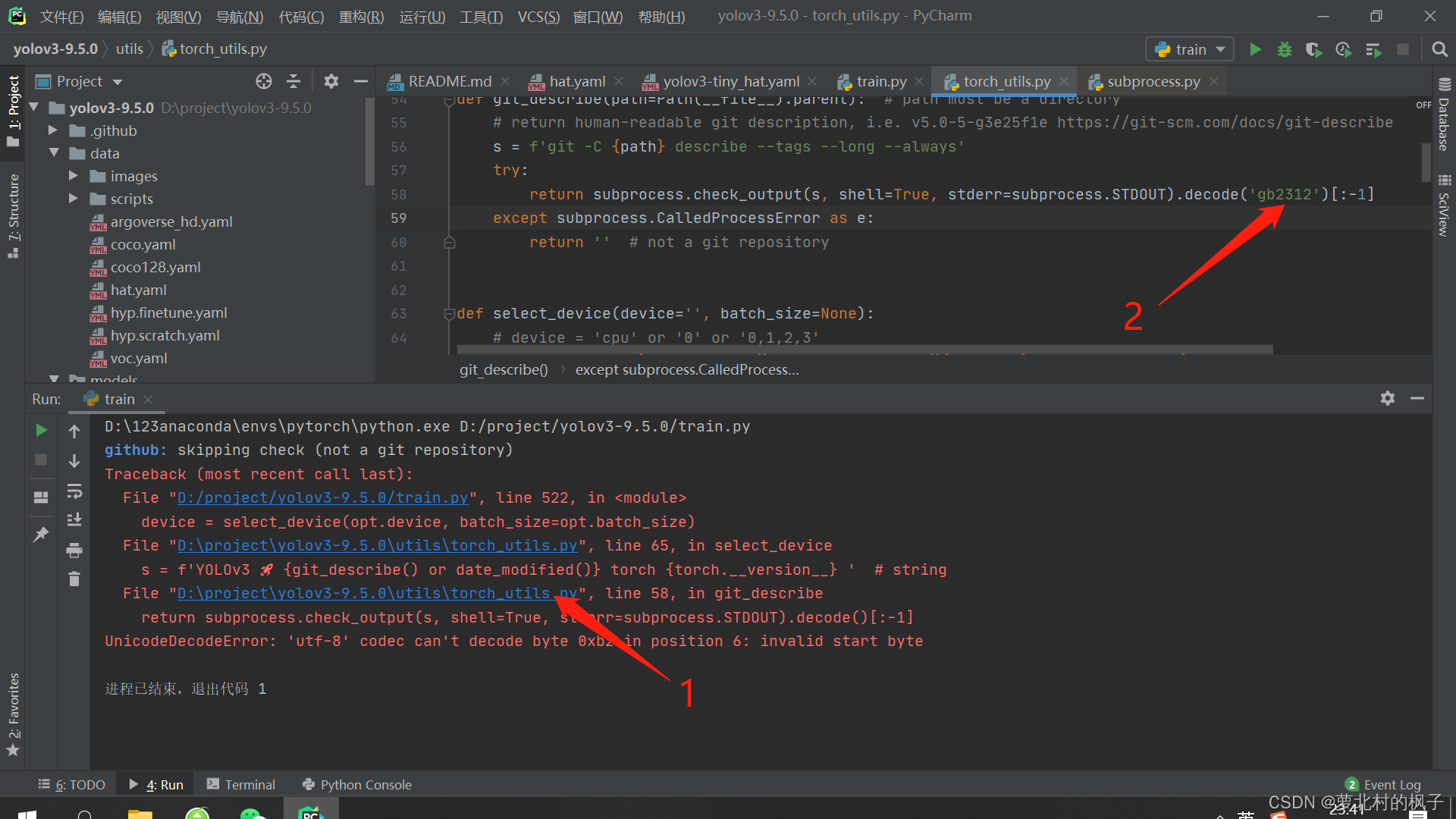
解决方法:
打开torch_utils.py,在第58行将编码方式改为decode(‘gb2312’)
如下图所示:
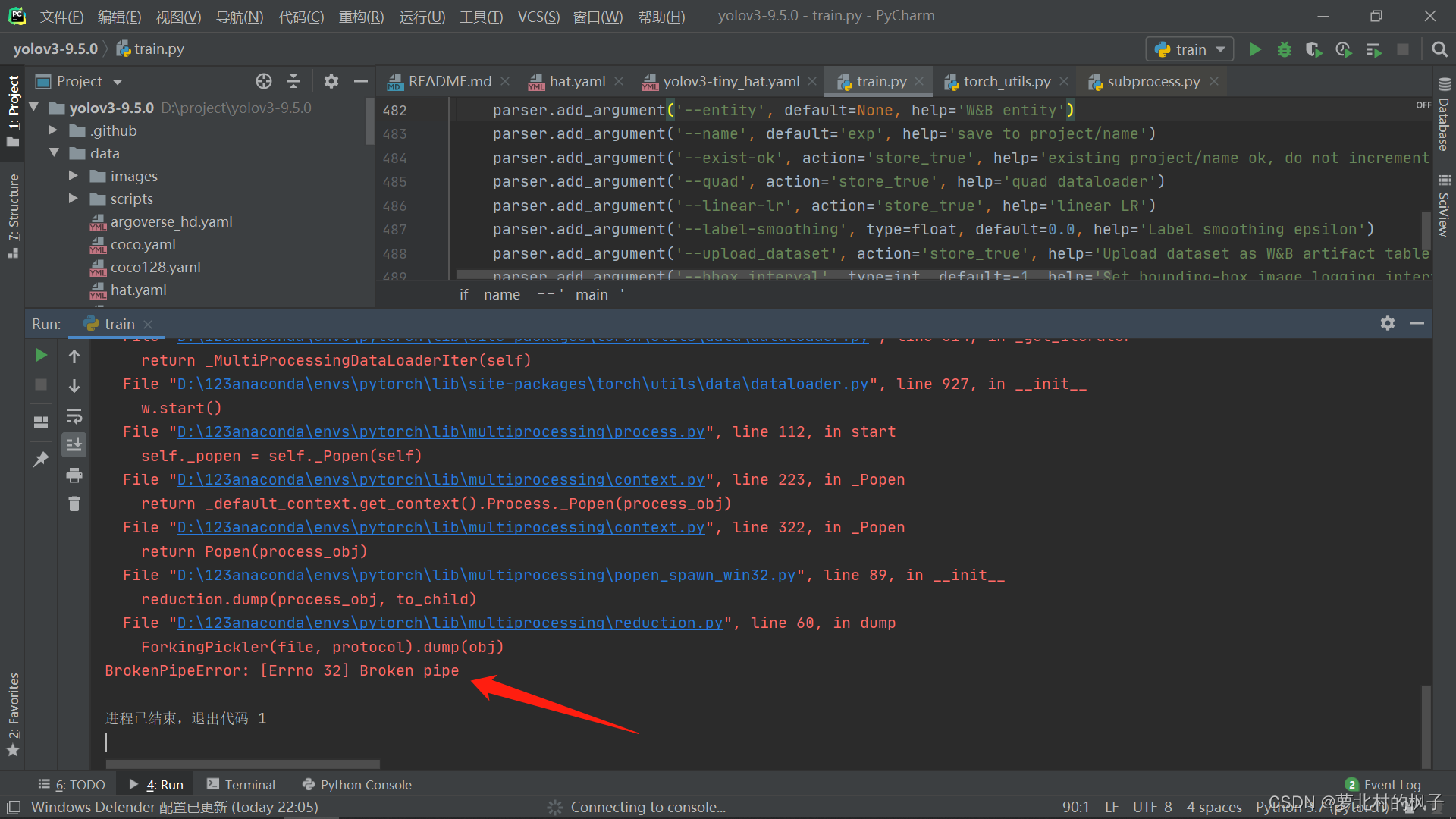
解决方法:
在第488行,将’–workers’的值改为0
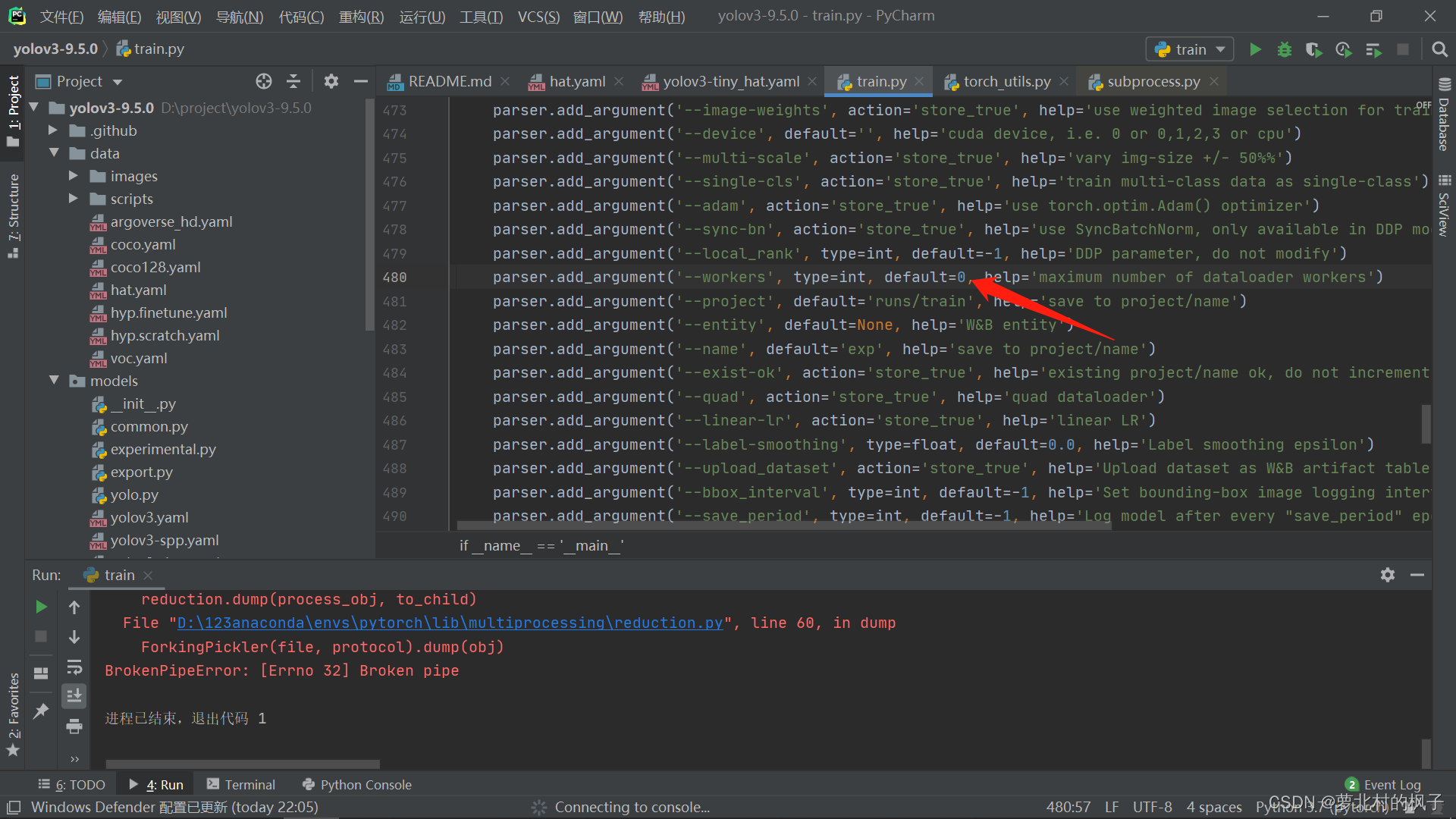
如下图所示:
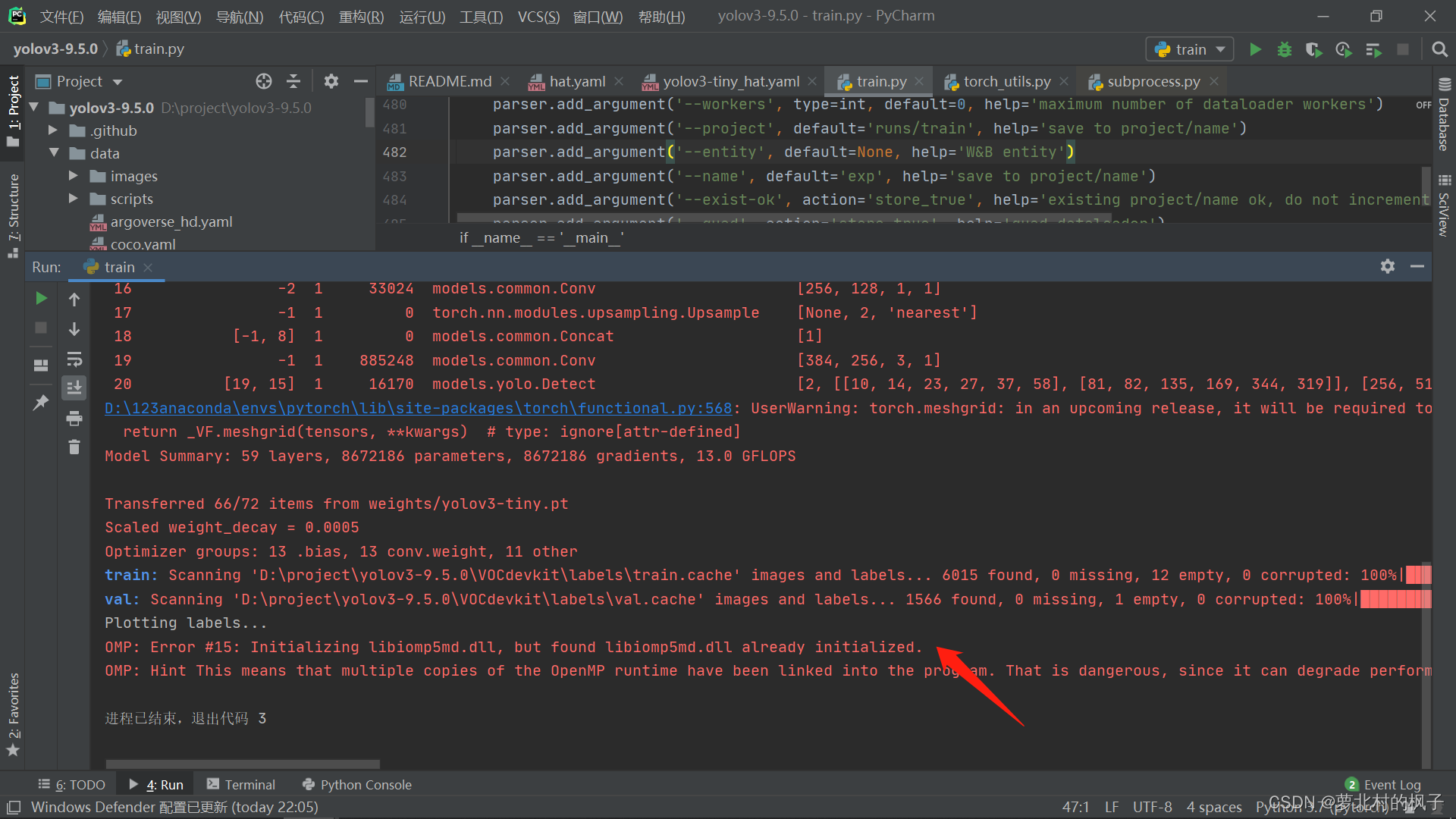
解决方法:
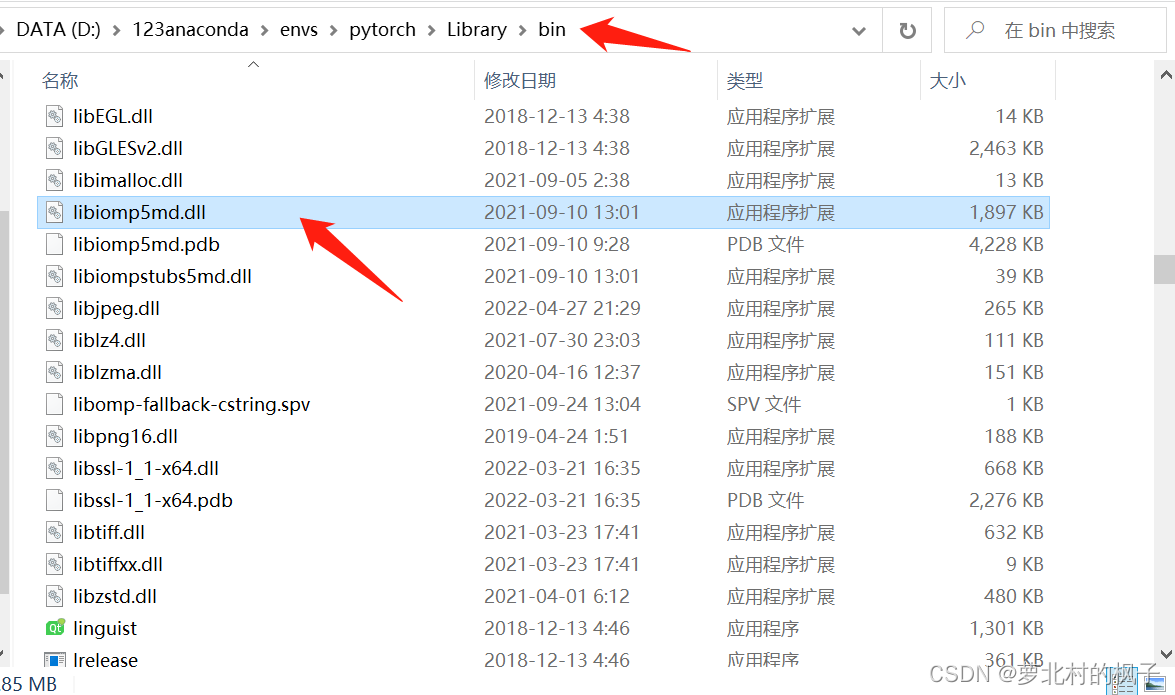
在anaconda安装目录的envs文件夹下,找到pytorch环境,进入library的bin文件夹,删除libiomp5md.dll文件
训练结束之后,在runs/train/exp/weights目录下会产生两个权重文件,一个是训练效果最好的权重文件,一个是训练最后一轮的权重文件
(接下来以best.pt权重文件为例)

将best.pt权重文件复制粘贴在主目录的weights文件夹下(方便后续操作)
2.将想进行测试的图片放在主目录的data文件夹下,如图所示:
3.打开defect.py,更改以下部分:
将"–weight"改为best.pt权重文件的地址(在weights文件夹中)
将"–source"改为要测试的图片地址(在data文件夹中)
parser.add_argument('--weights', nargs='+', type=str, default='weights/best.pt', help='model.pt path(s)')parser.add_argument('--source', type=str, default='data/1.jpg', help='source') # file/folder, 0 for WEBcam如图所示:

4.运行defect.py,即可得到结果;
5.如果识别视频,在将"–source"改为要测试的视频地址即可(注意加.mp4后缀名)
如果识别摄像头,在将"–source"的值置0即可,即:
parser.add_argument('--source', type=str, default='0', help='source') # file/folder, 0 for webcam来源地址:https://blog.csdn.net/thy0000/article/details/124579443
--结束END--
本文标题: yolov3模型训练——使用yolov3训练自己的模型
本文链接: https://www.lsjlt.com/news/391312.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0