Python 官方文档:入门教程 => 点击学习
目录 一、基础概念1.监督式机器学习2. 回归和分类3. 决策树4. 随机森林 二、Random Forest 的构造1. 算法实现2.数据的随机选取3. 待选特征的随机选取 三、Ra
随机森林是bagging集成策略中最实用的算法之一。森林是分别建立了多个决策树,把它们放到一起就是森林,这些决策树都是为了解决同一任务建立的,最终的目标也都是一致的,最后将其结果来平均即可,如图所示。

从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人标注的。监督学习就是最常见的分类问题,通过已有的训练样本(即已知数据及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优表示某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。也就具有了对未知数据分类的能力。监督学习的目标往往是让计算机去学习我们已经创建好的分类系统(模型)。
监督学习是训练神经网络和决策树的常见技术。这两种技术高度依赖事先确定的分类系统给出的信息,对于神经网络,分类系统利用信息判断网络的错误,然后不断调整网络参数。对于决策树,分类系统用它来判断哪些属性提供了最多的信息。
回归和分类都是监督式机器学习问题,用于预测结果或结果的价值或类别。他们的区别是:
分类问题是用于将事物打上一个标签,通常结果为离散值。例如判断一幅图片上的动物是一只猫还是一只狗,分类通常是建立在回归之上,分类并没有逼近的概念,最终正确结果只有一个,错误的就是错误的,不会有相近的概念。最常见的分类方法是逻辑回归,或者叫逻辑分类。
回归问题通常是用来预测一个值,如预测房价、未来的天气情况等等,例如一个产品的实际价格为500元,通过回归分析预测值为499元,这是一个比较好的回归分析。回归是对真实值的一种逼近预测。
区分两者的简单方法大概可以表述为,分类是关于预测标签(例如"垃圾邮件"或"不是垃圾邮件"),而回归是关于预测数量。
决策树是一种很简单的算法,他的解释性强,也符合人类的直观思维。这是一种基于if-then-else规则的有监督学习算法,下图可以直观的表达决策树的逻辑。
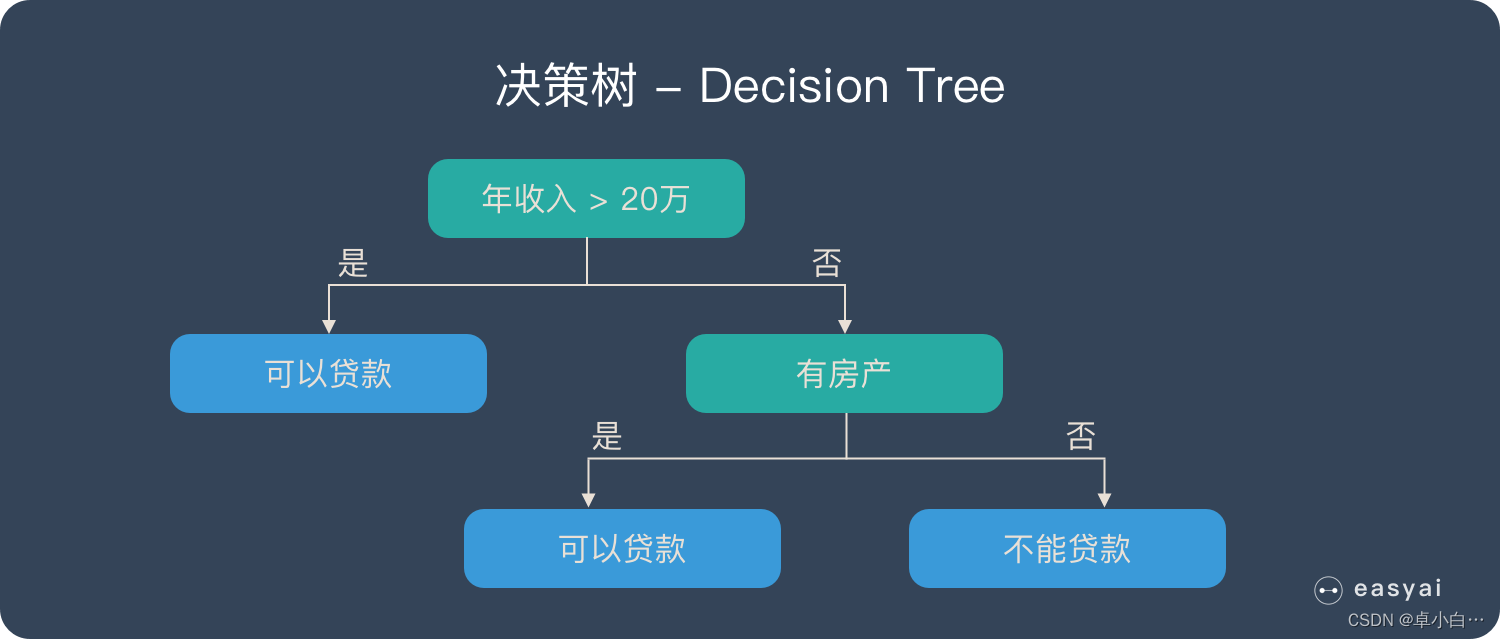
随机森林是由很多决策树构成的,不同决策树之间没有关联。当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。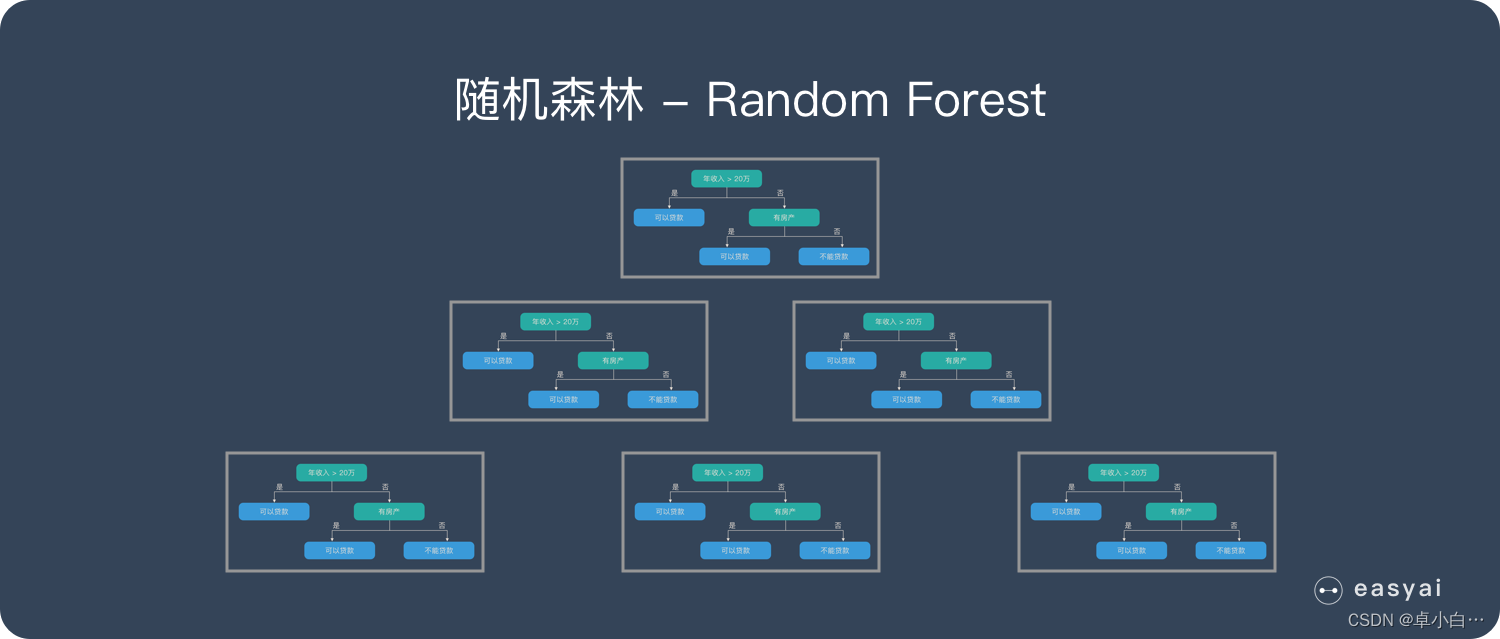

如图假设随机森林中有3棵子决策树,2棵子树的分类结果是A类,1棵子树的分类结果是B类,那么随机森林的分类结果就是A。
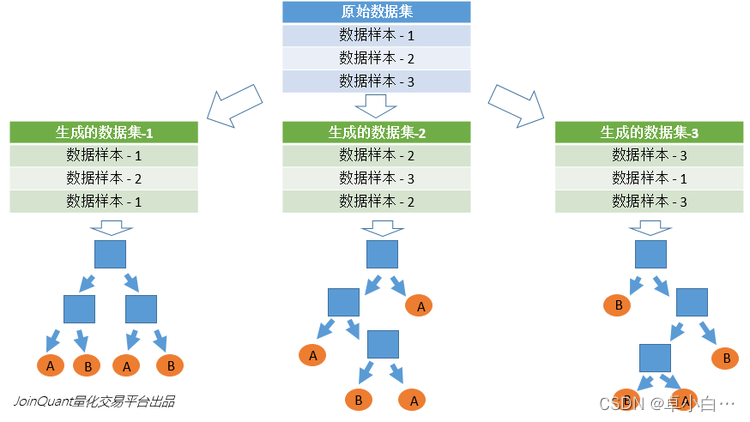
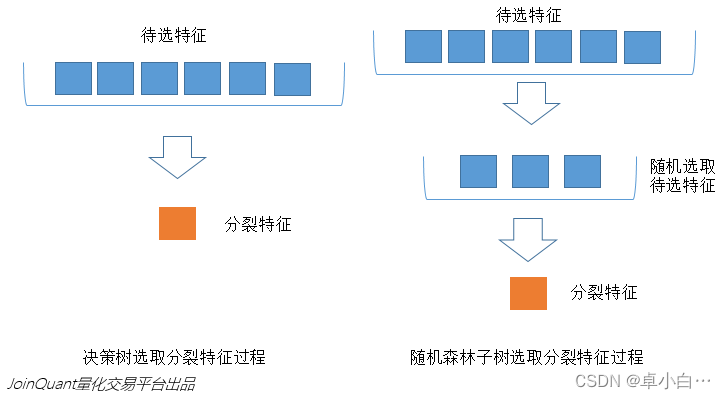
与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
下图中,蓝色的方块代表所有可以被选择的特征,也就是待选特征。黄色的方块是分裂特征。左边是一棵决策树的特征选取过程,通过在待选特征中选取最优的分裂特征,完成分裂。右边是一个随机森林中的子树的特征选取过程。
代码实现流程:
(1) 导入文件并将所有特征转换为float形式
(2) 将数据集分成n份,方便交叉验证
(3) 构造数据子集(随机采样),并在指定特征个数(假设m个,手动调参)下选取最优特征
(4) 构造决策树
(5) 创建随机森林(多个决策树的结合)
(6) 输入测试集并进行测试,输出预测结果
# -*- coding: utf-8 -*-import csvfrom random import seedfrom random import randrangefrom math import sqrt def loadCSV(filename):#加载数据,一行行的存入列表 dataSet = [] with open(filename, 'r') as file: csvReader = csv.reader(file) for line in csvReader: dataSet.append(line) return dataSet # 除了标签列,其他列都转换为float类型def column_to_float(dataSet): featLen = len(dataSet[0]) - 1 for data in dataSet: for column in range(featLen): data[column] = float(data[column].strip()) # 将数据集随机分成N块,方便交叉验证,其中一块是测试集,其他四块是训练集def spiltDataSet(dataSet, n_folds): fold_size = int(len(dataSet) / n_folds) dataSet_copy = list(dataSet) dataSet_spilt = [] for i in range(n_folds): fold = [] while len(fold) < fold_size: # 这里不能用if,if只是在第一次判断时起作用,while执行循环,直到条件不成立 index = randrange(len(dataSet_copy)) fold.append(dataSet_copy.pop(index)) # pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。 dataSet_spilt.append(fold) return dataSet_spilt # 构造数据子集def get_subsample(dataSet, ratio): subdataSet = [] lenSubdata = round(len(dataSet) * ratio)#返回浮点数 while len(subdataSet) < lenSubdata: index = randrange(len(dataSet) - 1) subdataSet.append(dataSet[index]) # print len(subdataSet) return subdataSet # 分割数据集def data_spilt(dataSet, index, value): left = [] right = [] for row in dataSet: if row[index] < value: left.append(row) else: right.append(row) return left, right # 计算分割代价def spilt_loss(left, right, class_values): loss = 0.0 for class_value in class_values: left_size = len(left) if left_size != 0: # 防止除数为零 prop = [row[-1] for row in left].count(class_value) / float(left_size) loss += (prop * (1.0 - prop)) right_size = len(right) if right_size != 0: prop = [row[-1] for row in right].count(class_value) / float(right_size) loss += (prop * (1.0 - prop)) return loss # 选取任意的n个特征,在这n个特征中,选取分割时的最优特征def get_best_spilt(dataSet, n_features): features = [] class_values = list(set(row[-1] for row in dataSet)) b_index, b_value, b_loss, b_left, b_right = 999, 999, 999, None, None while len(features) < n_features: index = randrange(len(dataSet[0]) - 1) if index not in features: features.append(index) # print 'features:',features for index in features:#找到列的最适合做节点的索引,(损失最小) for row in dataSet: left, right = data_spilt(dataSet, index, row[index])#以它为节点的,左右分支 loss = spilt_loss(left, right, class_values) if loss < b_loss:#寻找最小分割代价 b_index, b_value, b_loss, b_left, b_right = index, row[index], loss, left, right # print b_loss # print type(b_index) return {'index': b_index, 'value': b_value, 'left': b_left, 'right': b_right} # 决定输出标签def decide_label(data): output = [row[-1] for row in data] return max(set(output), key=output.count) # 子分割,不断地构建叶节点的过程def sub_spilt(root, n_features, max_depth, min_size, depth): left = root['left'] # print left right = root['right'] del (root['left']) del (root['right']) # print depth if not left or not right: root['left'] = root['right'] = decide_label(left + right) # print 'testing' return if depth > max_depth: root['left'] = decide_label(left) root['right'] = decide_label(right) return if len(left) < min_size: root['left'] = decide_label(left) else: root['left'] = get_best_spilt(left, n_features) # print 'testing_left' sub_spilt(root['left'], n_features, max_depth, min_size, depth + 1) if len(right) < min_size: root['right'] = decide_label(right) else: root['right'] = get_best_spilt(right, n_features) # print 'testing_right' sub_spilt(root['right'], n_features, max_depth, min_size, depth + 1) # 构造决策树def build_tree(dataSet, n_features, max_depth, min_size): root = get_best_spilt(dataSet, n_features) sub_spilt(root, n_features, max_depth, min_size, 1) return root# 预测测试集结果def predict(tree, row): predictions = [] if row[tree['index']] < tree['value']: if isinstance(tree['left'], dict): return predict(tree['left'], row) else: return tree['left'] else: if isinstance(tree['right'], dict): return predict(tree['right'], row) else: return tree['right'] # predictions=set(predictions)def bagging_predict(trees, row): predictions = [predict(tree, row) for tree in trees] return max(set(predictions), key=predictions.count)# 创建随机森林def random_forest(train, test, ratio, n_feature, max_depth, min_size, n_trees): trees = [] for i in range(n_trees): train = get_subsample(train, ratio)#从切割的数据集中选取子集 tree = build_tree(train, n_features, max_depth, min_size) # print 'tree %d: '%i,tree trees.append(tree) # predict_values = [predict(trees,row) for row in test] predict_values = [bagging_predict(trees, row) for row in test] return predict_values# 计算准确率def accuracy(predict_values, actual): correct = 0 for i in range(len(actual)): if actual[i] == predict_values[i]: correct += 1 return correct / float(len(actual)) if __name__ == '__main__': seed(1) dataSet = loadCSV('C:/Users/shadow/Desktop/组会/sonar-all-data.csv') column_to_float(dataSet)#dataSet n_folds = 5 max_depth = 16 min_size = 1 ratio = 1.0 # n_features=sqrt(len(dataSet)-1) n_features = 15 n_trees = 11 folds = spiltDataSet(dataSet, n_folds)#先是切割数据集 scores = [] for fold in folds: train_set = folds[ :] # 此处不能简单地用train_set=folds,这样用属于引用,那么当train_set的值改变的时候,folds的值也会改变,所以要用复制的形式。(L[:])能够复制序列,D.copy() 能够复制字典,list能够生成拷贝 list(L) train_set.remove(fold)#选好训练集 # print len(folds) train_set = sum(train_set, []) # 将多个fold列表组合成一个train_set列表 # print len(train_set) test_set = [] for row in fold: row_copy = list(row) row_copy[-1] = None test_set.append(row_copy) # for row in test_set: # print row[-1] actual = [row[-1] for row in fold] predict_values = random_forest(train_set, test_set, ratio, n_features, max_depth, min_size, n_trees) accur = accuracy(predict_values, actual) scores.append(accur) print ('Trees is %d' % n_trees) print ('scores:%s' % scores) print ('mean score:%s' % (sum(scores) / float(len(scores))))打印结果
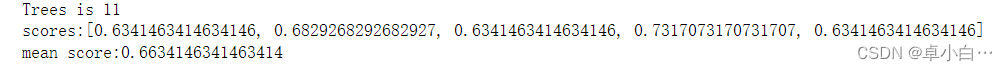
基于scikit-learn第三方机器学习库的实现:
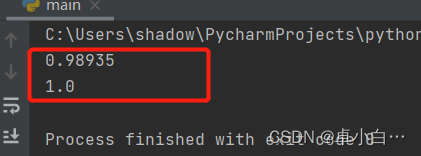
# -*- coding: utf-8 -*-from sklearn.model_selection import cross_val_scorefrom sklearn.datasets import make_blobsfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.ensemble import ExtraTreesClassifierfrom sklearn.tree import DecisionTreeClassifier##创建100个类共20000个样本,每个样本15个特征X, y = make_blobs(n_samples=20000, n_features=15, centers=100, random_state=0)## 决策树clf1 = DecisionTreeClassifier(max_depth=None, min_samples_split=2, random_state=0)scores1 = cross_val_score(clf1, X, y)print(scores1.mean())## 随机森林clf2 = RandomForestClassifier(n_estimators=10, max_depth=None, min_samples_split=2, random_state=0)scores2 = cross_val_score(clf2, X, y)print(scores2.mean())打印结果:
来源地址:https://blog.csdn.net/weixin_45075135/article/details/125838044
--结束END--
本文标题: 随机森林算法(Random Forest)原理分析及Python实现
本文链接: https://www.lsjlt.com/news/419435.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0