Python 官方文档:入门教程 => 点击学习
行索引、列索引、loc和iloc import pandas as pdimport numpy as np# 准备数据df = pd.DataFrame(np.arange(12).reshape(
import pandas as pdimport numpy as np# 准备数据df = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))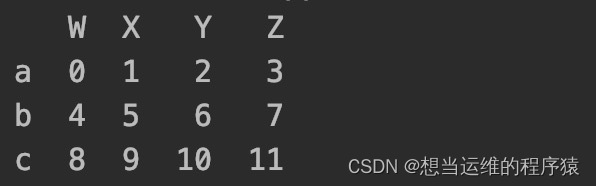
行索引(index):对应最左边那一竖列
列索引(columns):对应最上面那一横行
.loc[]官方释义: Access a group of rows and columns by label(s) or a boolean array.(通过标签或布尔数组访问一组行和列) 官方链接
.iloc[]官方释义: Purely integer-location based indexing for selection by position.(按位置进行索引选择) 官方链接
df['W'] # 取‘W’列,返回类型是Seriesdf[['W']] # 取‘W’列,返回类型是DataFramedf[['W','Y']] # 取‘W’列和‘Y’列df.loc[:,'W':'Y'] # 取‘W’列到‘Y’列df.loc['a'] # 取‘a’行,返回类型是Seriesdf.loc[['a']] # 取‘a’行,返回类型是DataFramedf.loc[['a','c']] # 取‘a’行和‘c’行,也可以写成 df.loc[['a','c'],:]df.loc['a':'c',:] # 取‘a’行到‘c’行df.iloc[:,1] # 取第2列(‘X’列),列号为1,返回类型是Seriesdf.iloc[:,0:2] # 取前2列(‘W’列和‘X’列),列号为0和1df.iloc[:,0:-1] # 取最后一列之前的所有列df[:2] #取前2行,行号为0和1df[1:2] #取第2行,行号为1df.iloc[1] # 取第2行(‘b’行),行号为1,返回类型是Series,也可以写成df.iloc[1,:]df.loc['b','W'] # 取‘b’行‘W’列的值df.iloc[0]['W'] # 取第1行、‘W’列的值df[:2][['W','Y']] # 取前2行的‘W’列和’Y‘列df[:2].loc[:2,'W':'Y'] # 取前2行的‘W’列到’Y‘列df.iloc[0][['W','Y']] # 取第1行的‘W’列和’Y‘列df.iloc[0]['W':'Y'] # 取第1行的‘W’列到’Y‘列df.loc[["a","c"],["W","Y"]] # 取‘a’行和‘c’行,‘W’列和‘Y’列df.iloc[[0,2],[1,3]] # 取1、3行,2、4列总结: 一般通过行位置来取行,通过列索引来取列,且行索引大多数情况下和行位置是相同的。
最常用的是以下几个
# 取某一列df['W']# 取某一行df.iloc[0] # 取多列df.loc[:,'W':'Y'] # 取‘W’列到‘Y’列df.iloc[:,0:-1] # 取最后一列之前的所有列# 取对应行列的值df.iloc[0]['W']df.loc['a','W'] # 在行索引和行位置相同的情况下的写法就是,df.loc[0,'W']来源地址:https://blog.csdn.net/qq_33218097/article/details/130315303
--结束END--
本文标题: 【pandas】Python读取DataFrame的某行或某列
本文链接: https://www.lsjlt.com/news/419660.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0