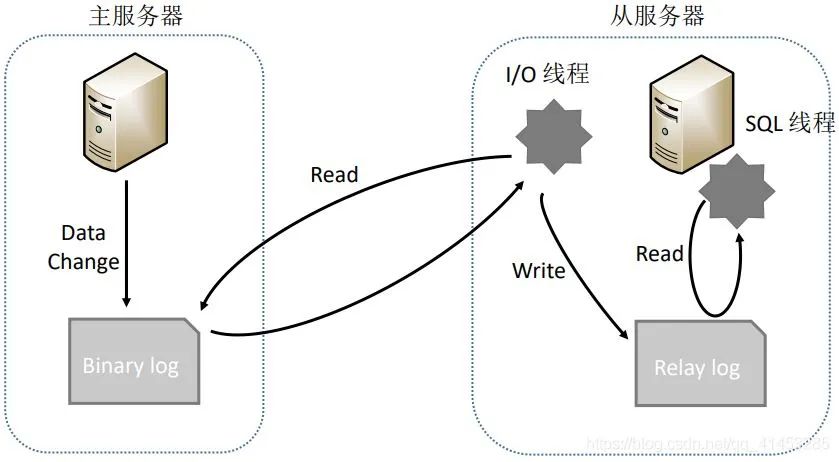
1.数据同步到数据库: 在介绍方案2之前我们先来介绍一下MySQL复制的原理,如下图所示: 主服务器操作数据,并将数据写入Bin log从服务器调用I/O线程读取主服务器的Bin log,并且写入到自己的Relay log中,再调用
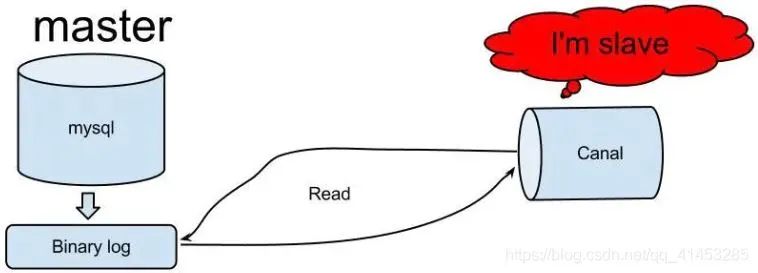
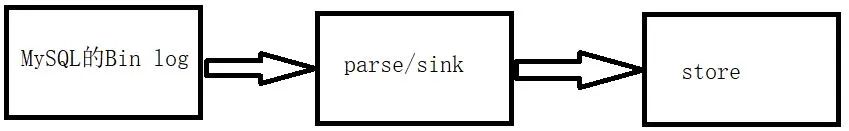
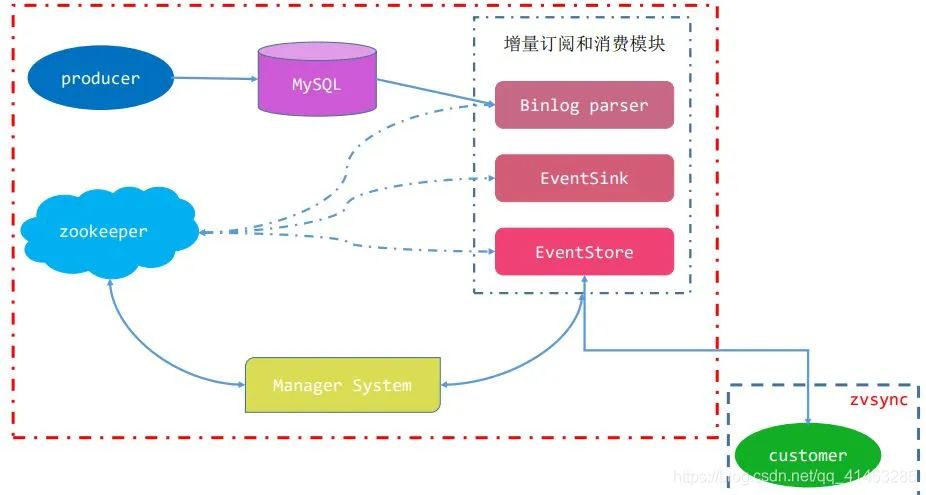

Canal 伪装成 MySQL 从节点,mySQL master 会推送 binary log 给canal,canal读取 MySQL binlog的变更信息并生成消息,客户端订阅这些数据变更消息,处理并存储。只要开发一个 Canal客户端就可以解析出MySQL的操作,再将这些数据发送到大数据流计算处理引擎,即可以实现对 MySQL 实时处理。
我们一般使用canal时,只需要引入一个客户端,比如java类似这样:
然后就可以订阅binlog消息了。
另外canal也支持直接把binlog消息发送到MQ,这样对多语言的支持更好一些。
canal自身帮我们做了很多事,这样我们自己写的客户端才能更简单,更专注于业务。下面就来看看canal内部的架构。
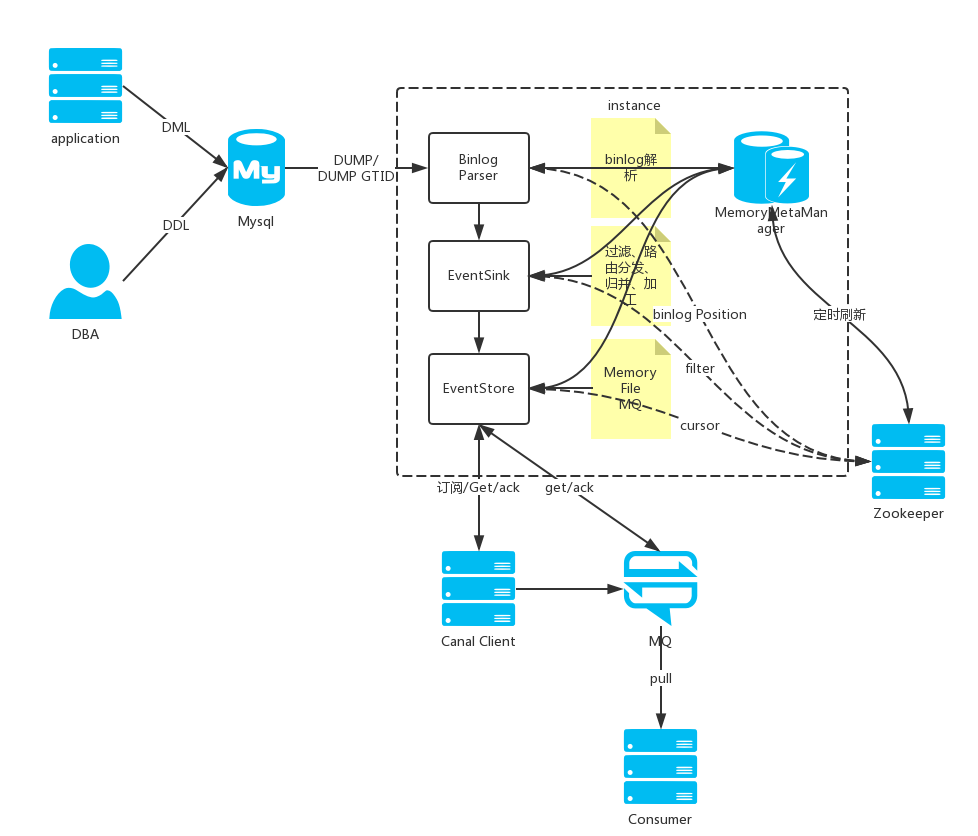
说明:
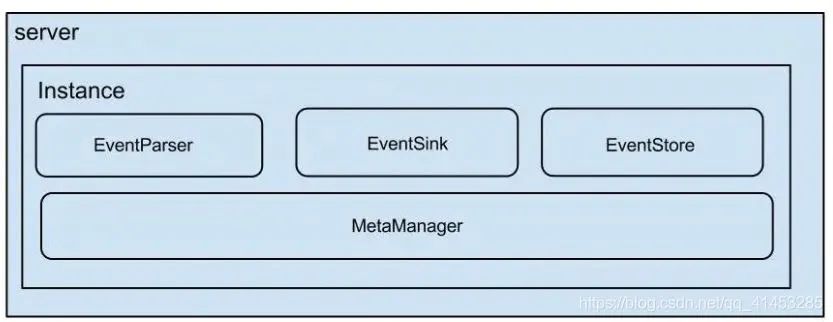
server代表一个canal运行实例,对应于一个JVM
instance对应于一个数据队列
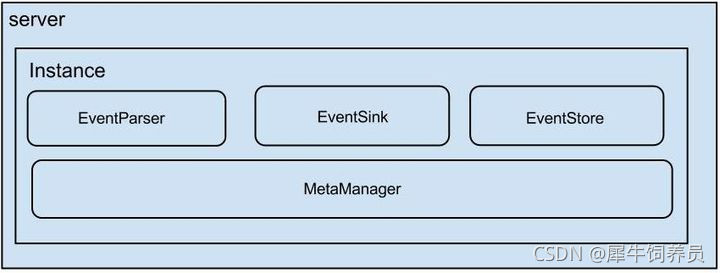
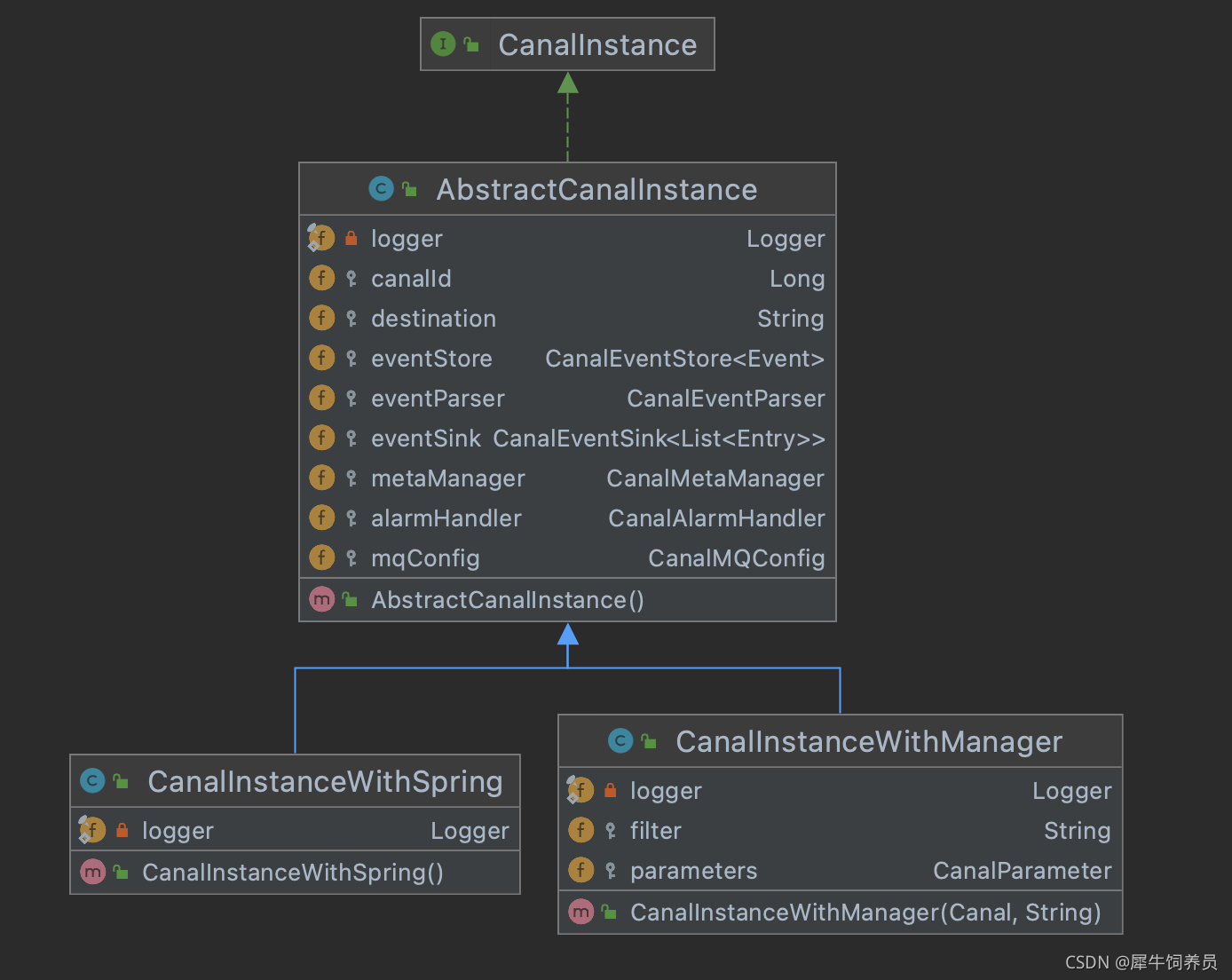
核心是instance模块,它包含:
parser模块
parser模块用来订阅binlog事件,然后通过sink投递到store。parser模块底层依赖dbsync、driver模块。
eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
meta模块
核心接口为CanalMetaManager,实现了订阅&消费的机制,主要用于记录canal消费到的mysql binlog的位置。CanalMetaManager接口有几个实现类:
FileMixedMetaManager
MemoryMetaManager
MixedMetaManager
PeriodMixedMetaManager
ZooKeeperMetaManager
这些实现类之间有些会持有其它实现的引用来装饰自己的功能(装饰器模式),
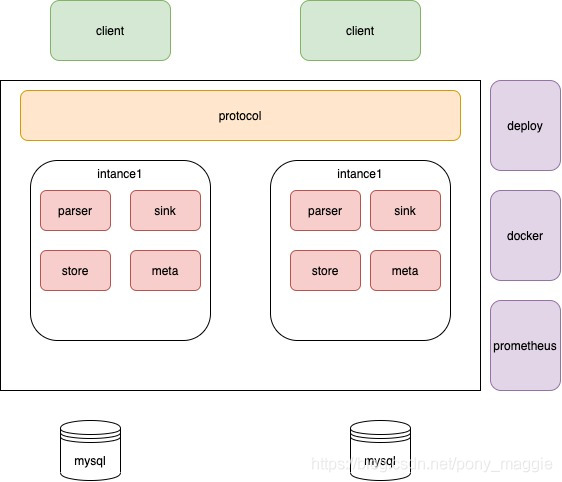
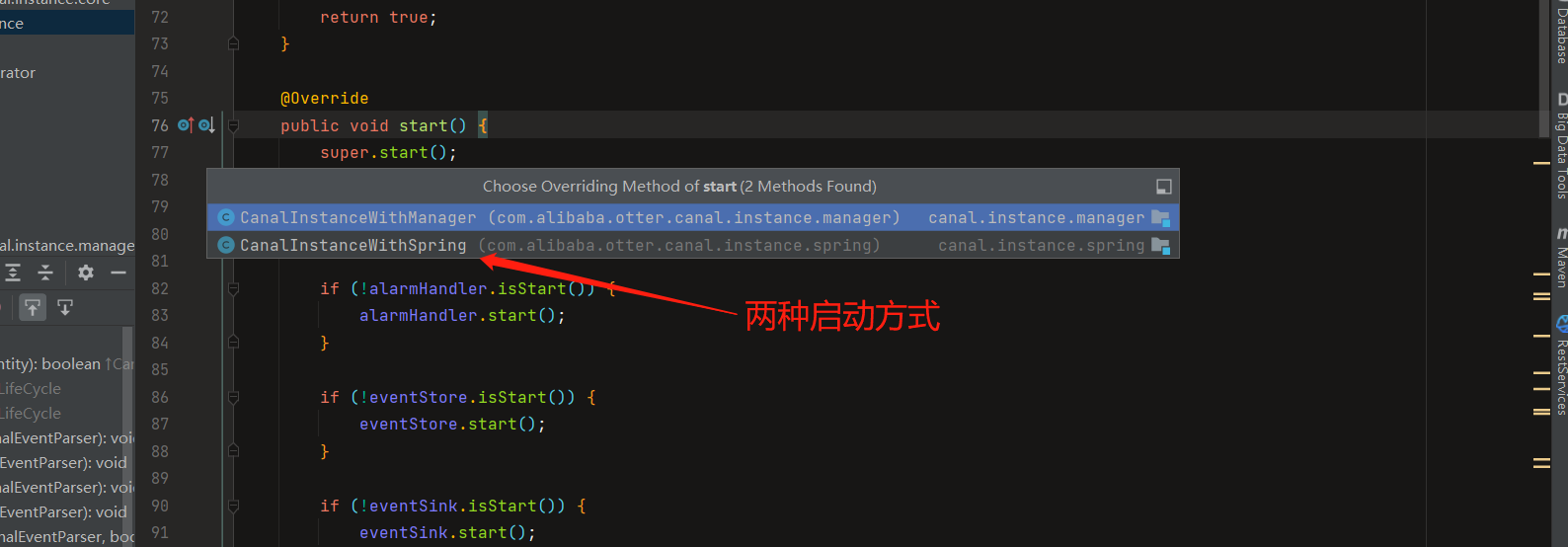
这两个实现代表了canal的两种应用模式,CanalServerWithNetty在canal独立部署场景发挥作用,开发者只需要实现cient,不同的应用通过canal client与canal server进行通信,canal client的请求统一由CanalServerWithNetty接受进行处理。
而通过CanalServerWithEmbeded,可以不需要独立部署canal,而是把canal嵌入到我们自己的服务里。但是这种对开发者的要求就比较高。
下面的图表示二者的关系,
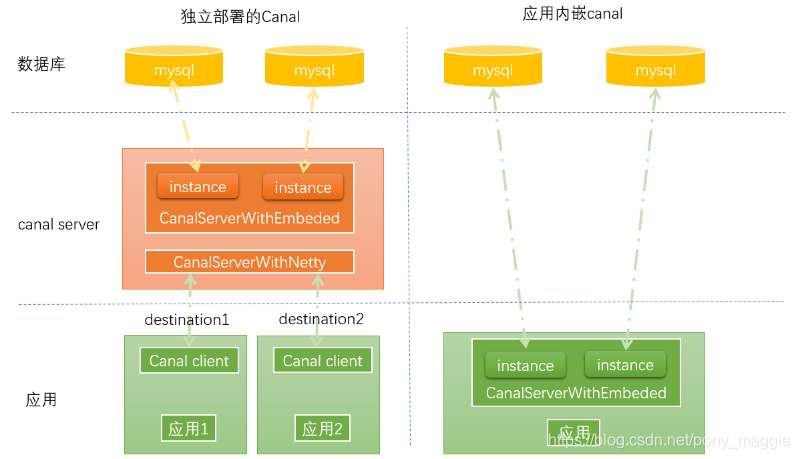
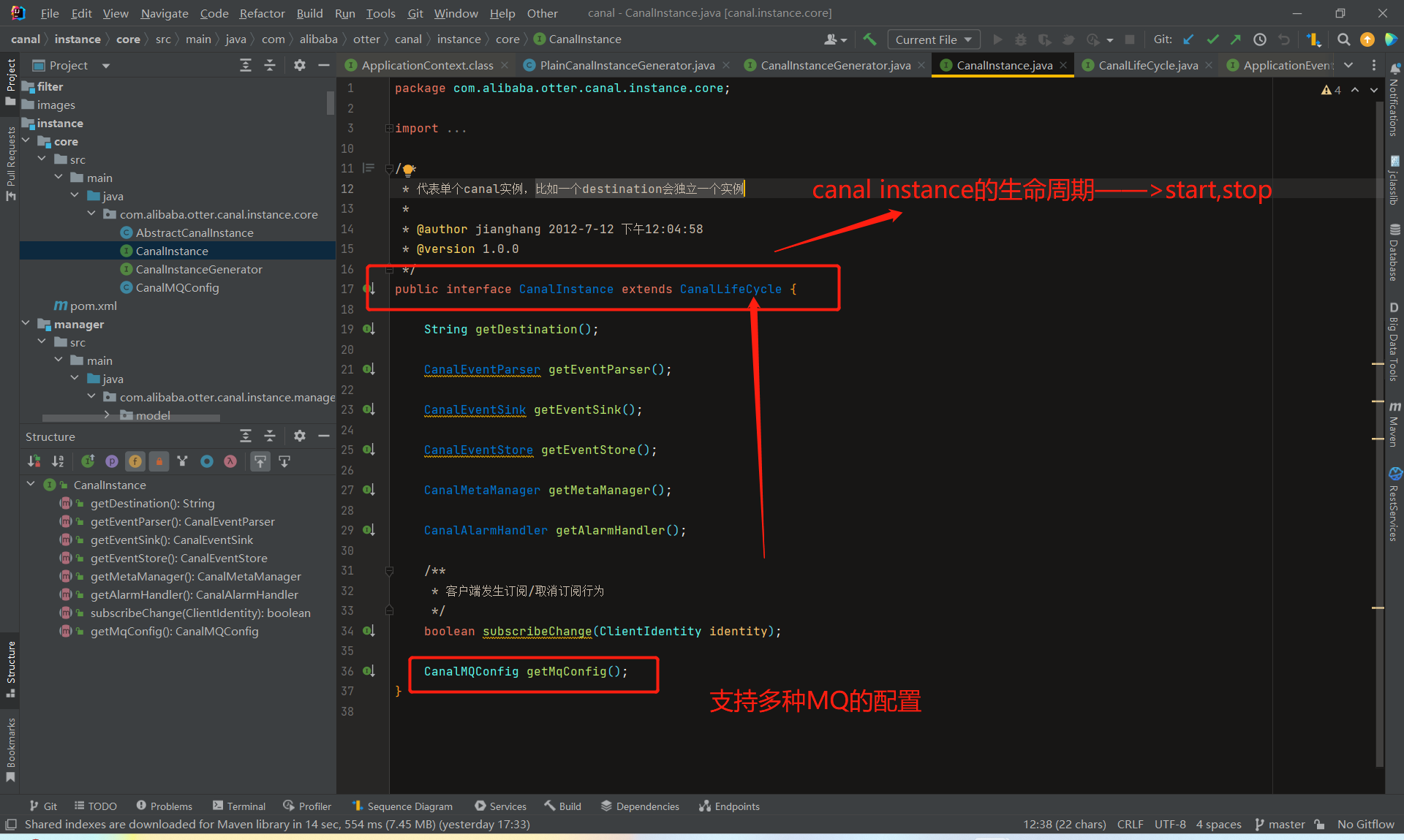
CanalServerWithEmbedded 内部管理所有的CanalInstance,通过 Client 的信息(destination),找到 Client 订阅的 CanalInstance,然后调用 CanalInstance 内部的各个模块进行处理(4个模块 )
1.CanalServerWithEmbedded 内部管理所有的CanalInstance,通过 Client 的信息(destination),找到 Client 订阅的 CanalInstance,然后调用 CanalInstance 内部的各个模块进行处理
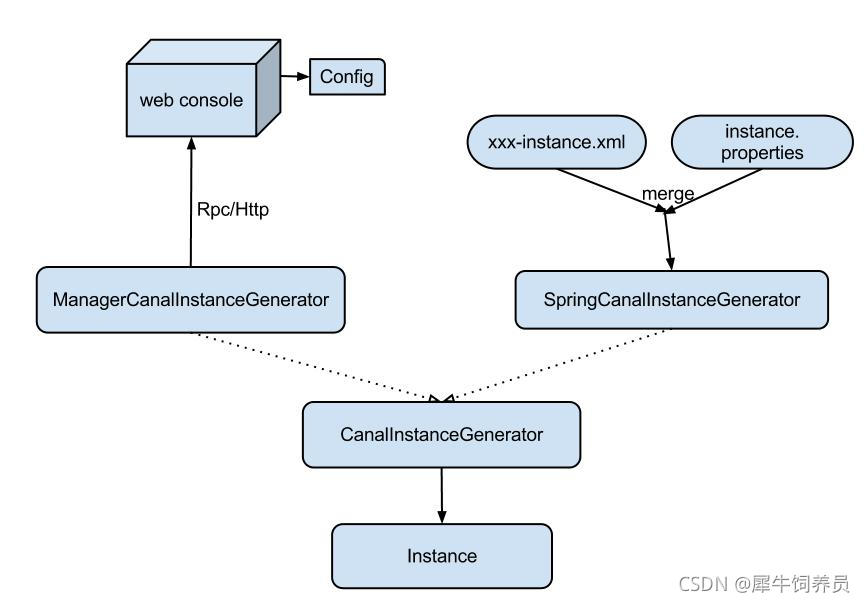
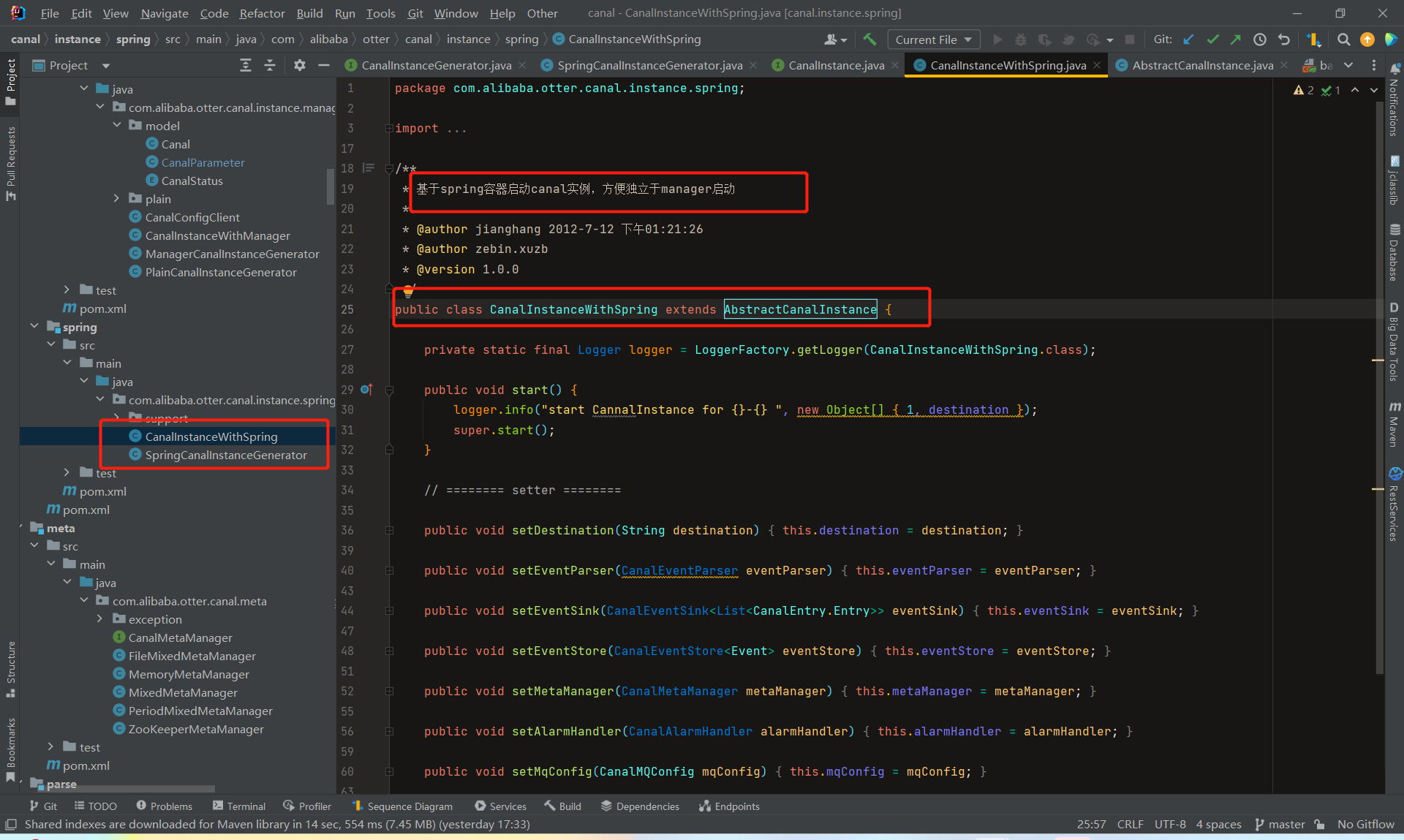
CanalInstanceGenerator相当于一个工厂类,通过 destination 产生特定的 CanalInstance,它有两个实现:
ManagerCanalInstanceGenerator类,manager方式: 和你自己的内部WEB console/manager系统进行对接。(目前主要是公司内部使用)
springCanalInstanceGenerator类,spring方式:基于spring xml + properties进行定义,构建spring配置
canal.instance.global.mode = spring
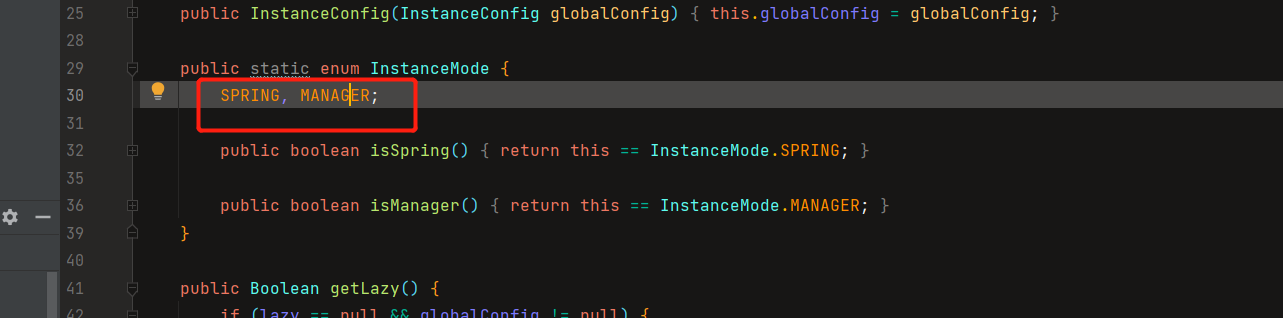
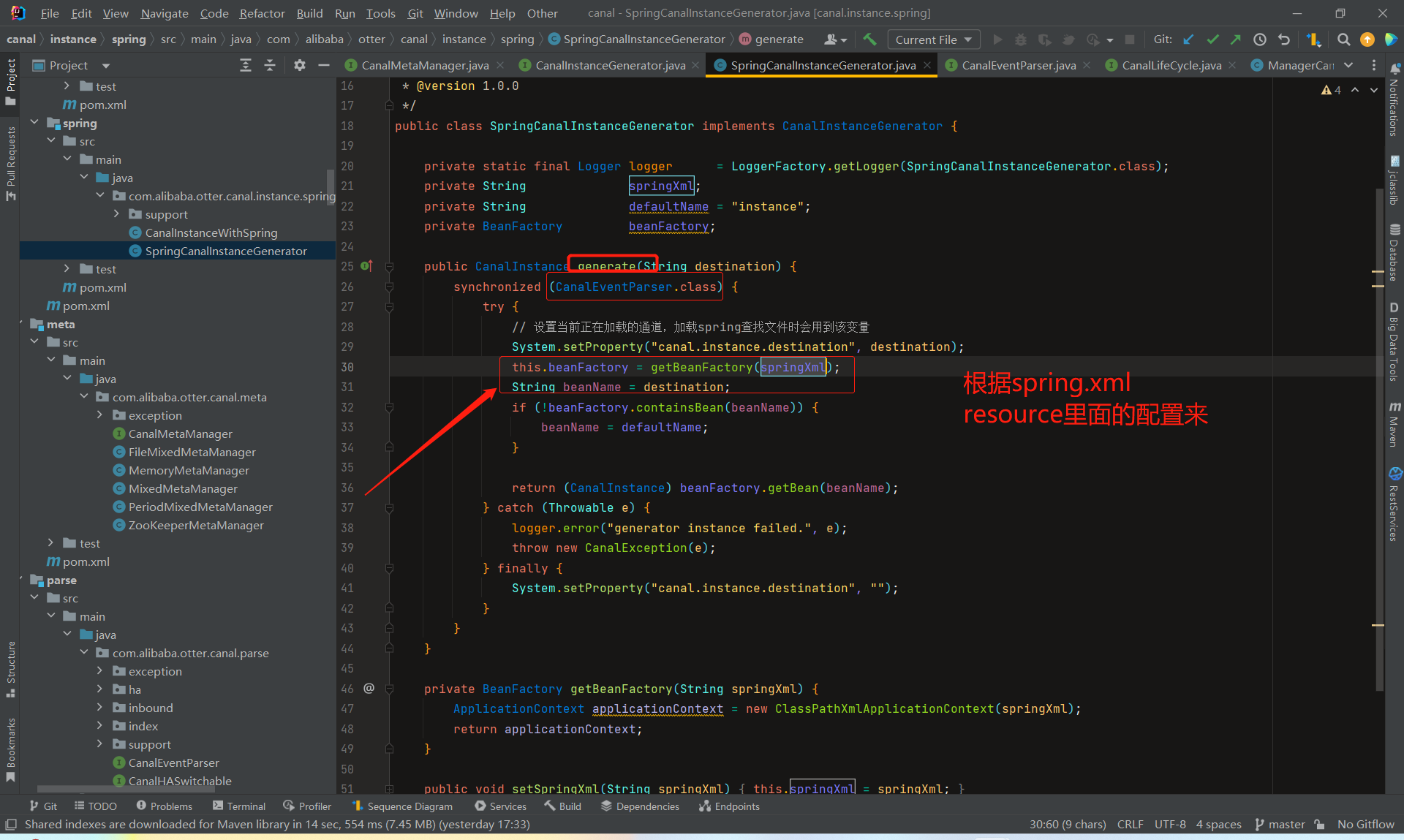
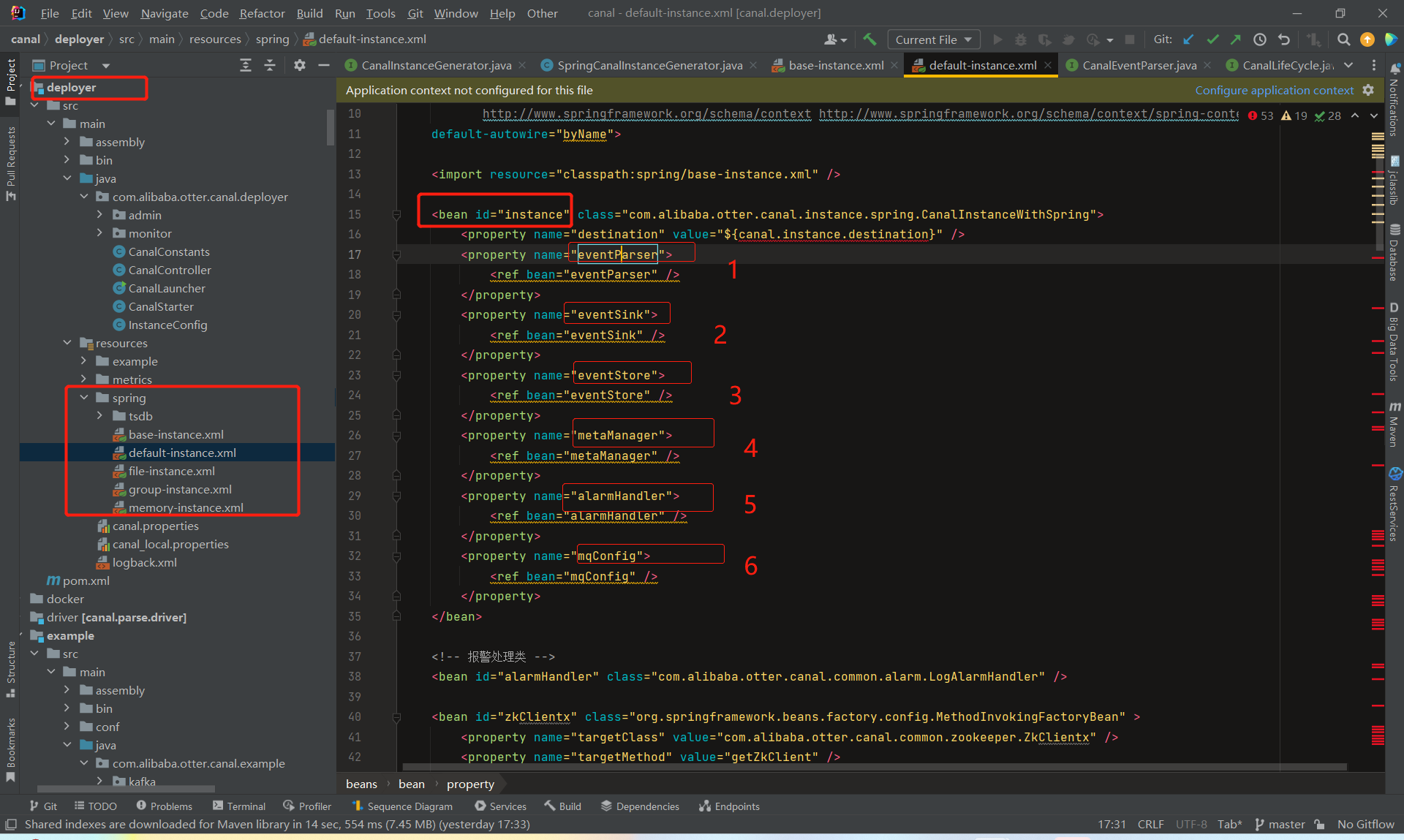
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
这几个文件的主要区别是,metaManager 和eventParser 这两个配置有所不同,可能在内存、文件或zk进行存储。
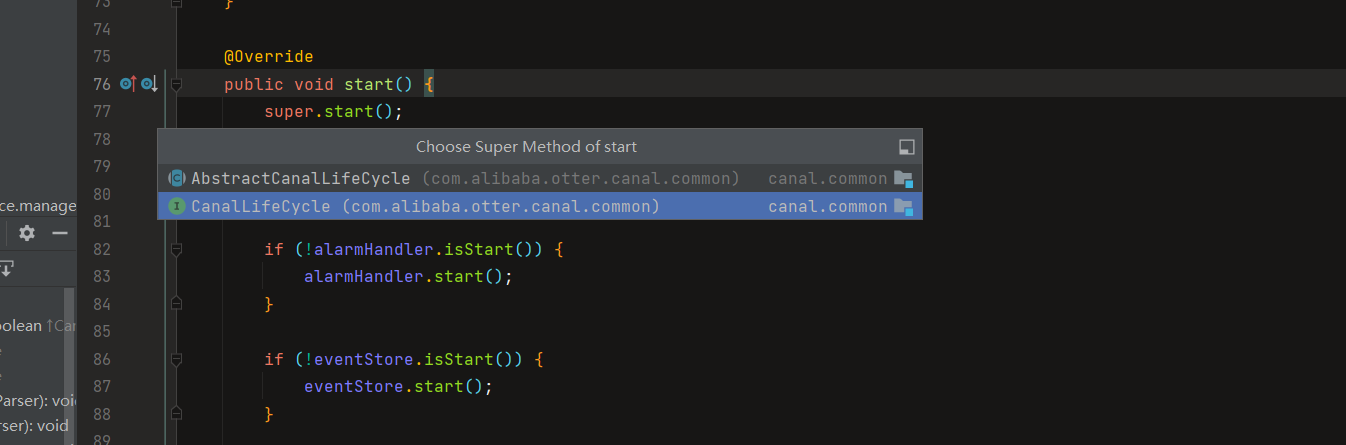
前者调用了startEventParserInternal,后者调用了stopEventParserInternal,
就是分别负责了CanalLogPositionManager和CanalHAController的启动停止工作。
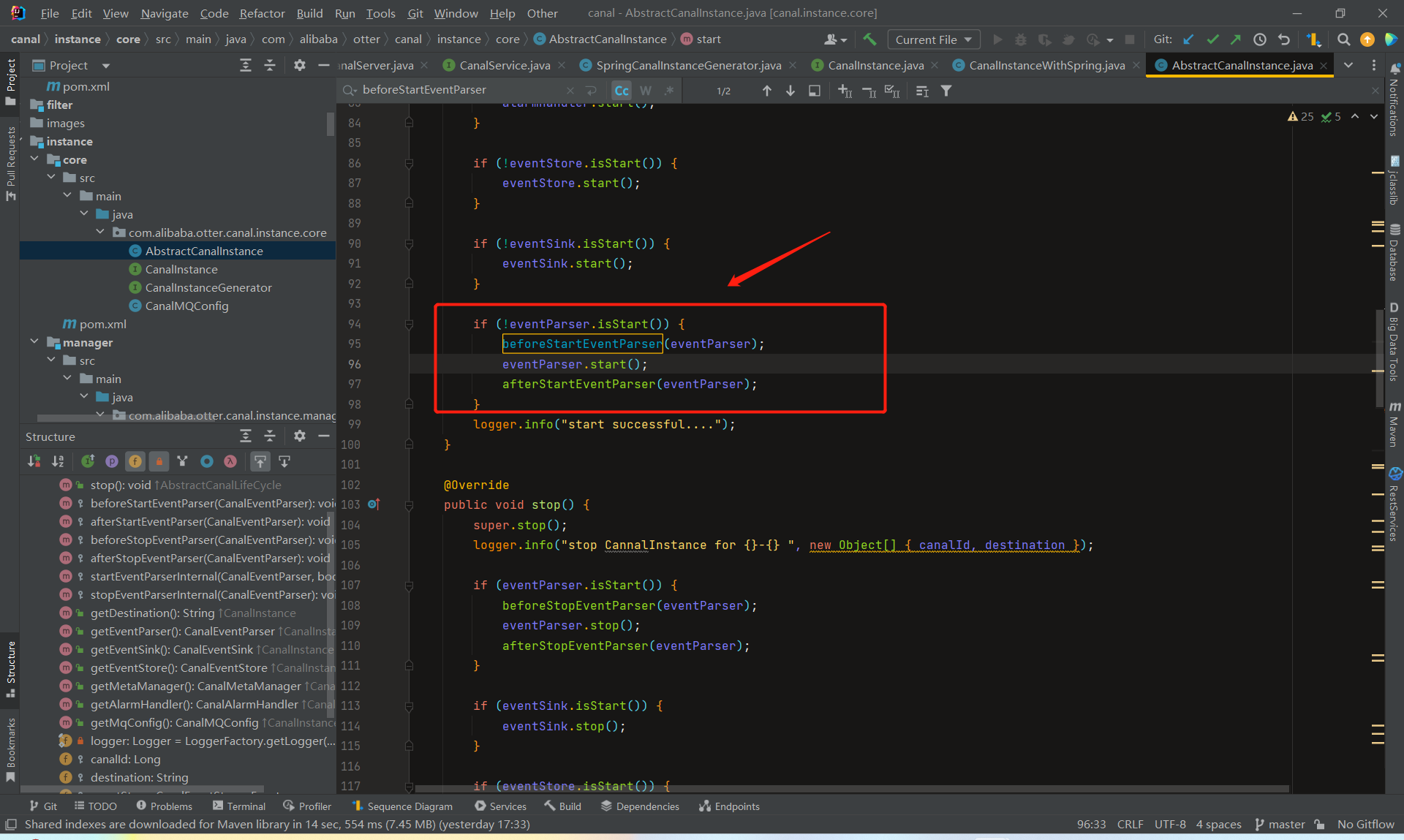
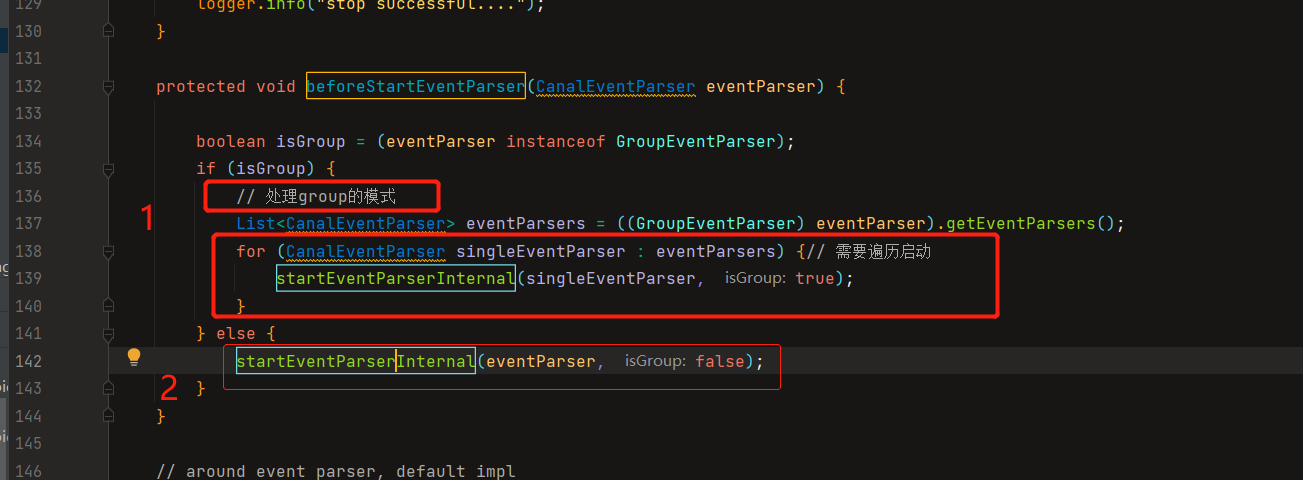
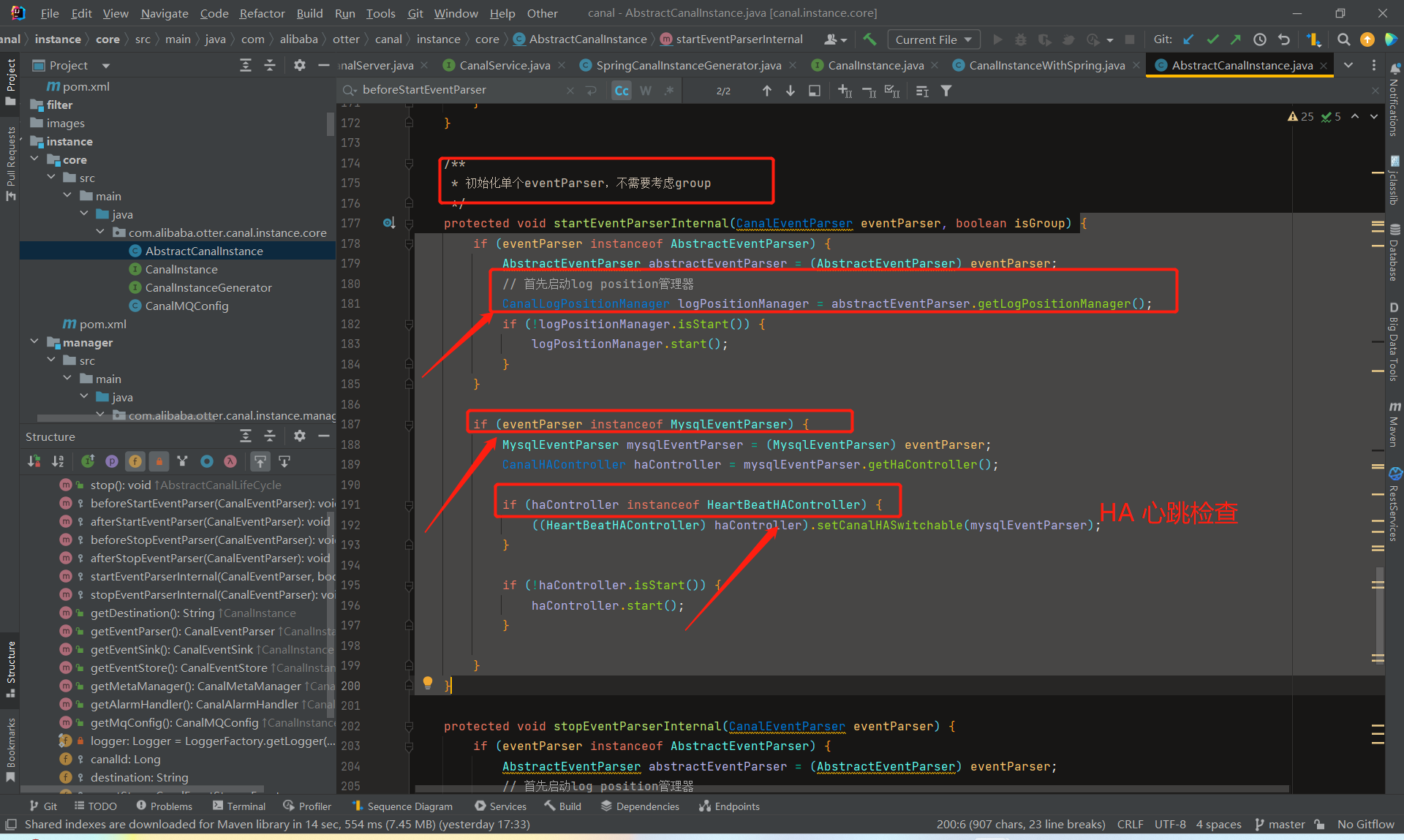
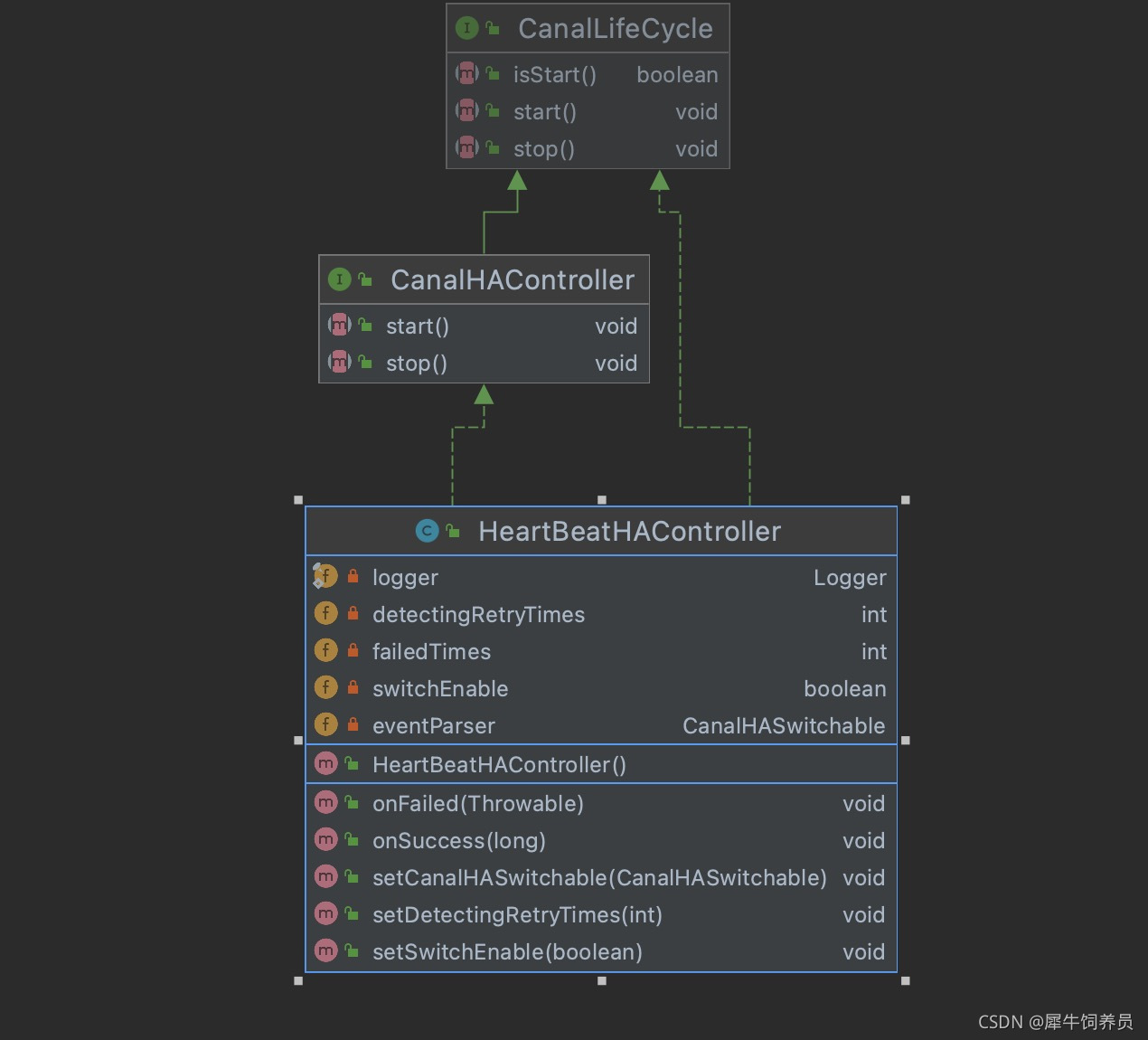
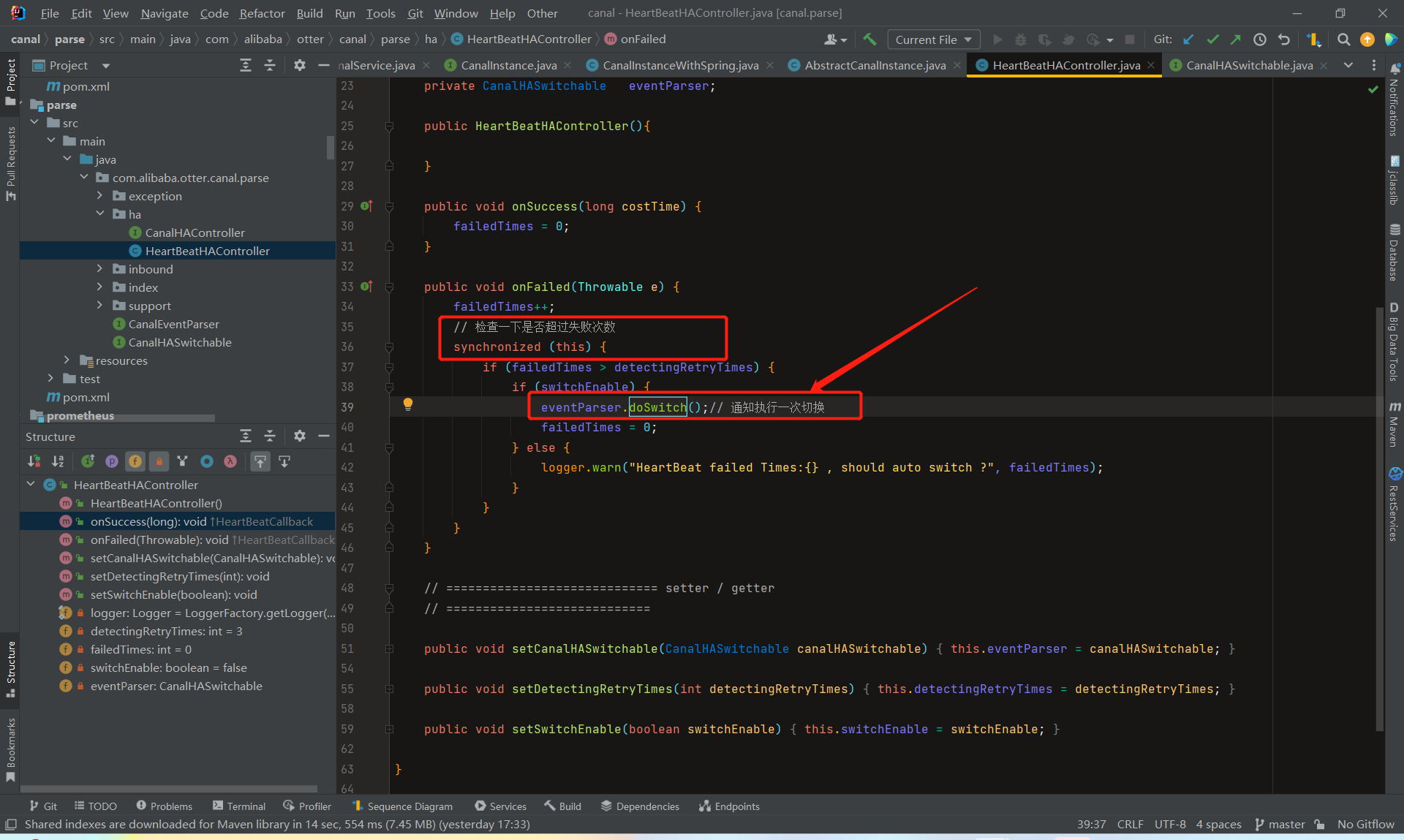
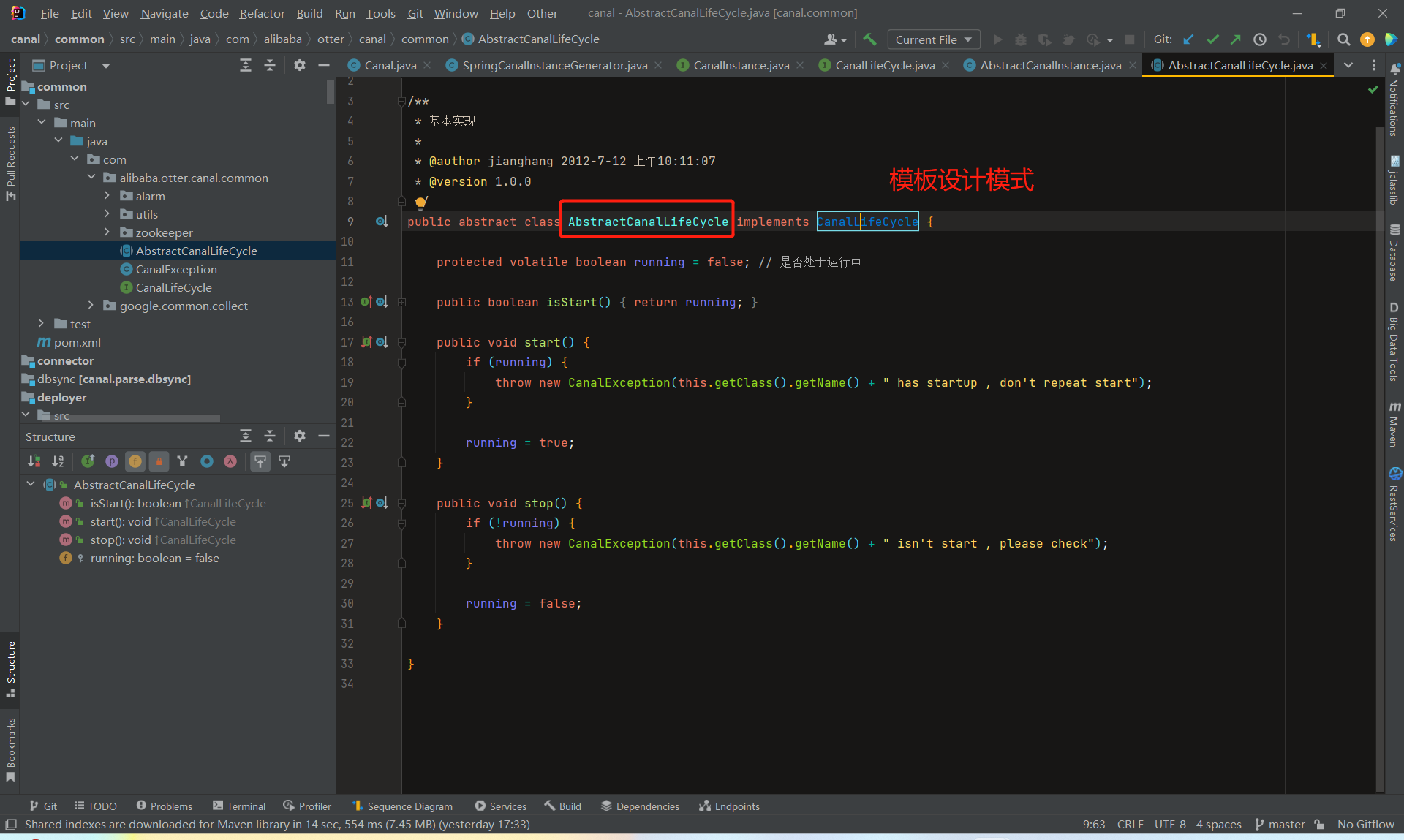
总体来看,CanalInstance模块本身没有什么特别复杂的逻辑,它的核心处理都在parser、sink、store、metamanager等内部组件里
canal 1.1.1版本之后, 默认支持将canal server接收到的binlog数据直接投递到MQ, 目前默认支持的MQ系统有:
到官网地址(release)下载最新压缩包,请下载 canal.deployer-latest.tar.gz
mkdir -p /usr/local/canal cp canal.deployer-1.1.6.tar.gz /usr/local/canal tar -zxvf canal.deployer-1.1.6.tar.gz
a. 修改instance 配置文件 vi conf/example/instance.properties
# 按需修改成自己的数据库信息 ################################################# ... canal.instance.master.address=192.168.1.20:3306 # username/passWord,数据库的用户名和密码 ... canal.instance.dbUsername = canal canal.instance.dbPassword = canal ... # mq config canal.mq.topic=example # 针对库名或者表名发送动态topic #canal.mq.dynamicTopic=mytest,.*,mytest.user,mytest\\..*,.*\\..* canal.mq.partition=0 # hash partition config #canal.mq.partitionsNum=3 #库名.表名: 唯一主键,多个表之间用逗号分隔 #canal.mq.partitionHash=mytest.person:id,mytest.role:id #################################################
对应ip 地址的MySQL 数据库需进行相关初始化与设置, 可参考 Canal QuickStart
b. 修改canal 配置文件vi /usr/local/canal/conf/canal.properties
# ... # 可选项: tcp(默认), kafka,RocketMQ,rabbitmq,pulsarmq canal.serverMode = kafka # ... # Canal的batch size, 默认50K, 由于kafka最大消息体限制请勿超过1M(900K以下) canal.mq.canalBatchSize = 50 # Canal get数据的超时时间, 单位: 毫秒, 空为不限超时 canal.mq.canalGetTimeout = 100 # 是否为flat JSON格式对象 canal.mq.flatMessage = false
| 参数名 | 参数说明 | 默认值 |
| canal.mq.servers | kafka为bootstrap.servers | 127.0.0.1:6667 |
| canal.mq.retries | 发送失败重试次数 | 0 |
| canal.mq.batchSize | kafka为ProducerConfig.BATCH_SIZE_CONFIG | 16384 |
| canal.mq.maxRequestSize | kafka为ProducerConfig.MAX_REQUEST_SIZE_CONFIG | 1048576 |
| canal.mq.lingerMs | kafka为ProducerConfig.LINGER_MS_CONFIG , 如果是flatMessage格式建议将该值调大, 如: 200 | 1 |
| canal.mq.bufferMemory | kafka为ProducerConfig.BUFFER_MEMORY_CONFIG | 33554432 |
| canal.mq.acks | kafka为ProducerConfig.ACKS_CONFIG | all |
| canal.mq.kafka.kerberos.enable | kafka为ProducerConfig.ACKS_CONFIG | false |
| canal.mq.kafka.kerberos.krb5FilePath | kafka kerberos认证 | ../conf/kerberos/krb5.conf |
| canal.mq.kafka.kerberos.jaasFilePath | kafka kerberos认证 | ../conf/kerberos/jaas.conf |
| canal.mq.producerGroup | kafka无意义 | Canal-Producer |
| canal.mq.accessChannel | kafka无意义 | local |
| --- | --- | --- |
| canal.mq.vhost= | rabbitMQ配置 | 无 |
| canal.mq.exchange= | rabbitMQ配置 | 无 |
| canal.mq.username= | rabbitMQ配置 | 无 |
| canal.mq.password= | rabbitMQ配置 | 无 |
| canal.mq.aliyunuid= | rabbitMQ配置 | 无 |
| --- | --- | --- |
| canal.mq.canalBatchSize | 获取canal数据的批次大小 | 50 |
| canal.mq.canalGetTimeout | 获取canal数据的超时时间 | 100 |
| canal.mq.parallelThreadSize | mq数据转换并行处理的并发度 | 8 |
| canal.mq.flatMessage | 是否为json格式 | false |
| --- | --- | --- |
| canal.mq.topic | mq里的topic名 | 无 |
| canal.mq.dynamicTopic | mq里的动态topic规则, 1.1.3版本支持 | 无 |
| canal.mq.partition | 单队列模式的分区下标, | 1 |
| canal.mq.partitionsNum | 散列模式的分区数 | 无 |
| canal.mq.partitionHash | 散列规则定义 | 无 |
在1.1.5版本开始,引入了MQ Connector设计,因此参数配置做了部分调整
| 参数名 | 参数说明 | 默认值 |
| canal.aliyun.accessKey | 阿里云ak | 无 |
| canal.aliyun.secreTKEy | 阿里云sk | 无 |
| canal.aliyun.uid | 阿里云uid | 无 |
| canal.mq.flatMessage | 是否为json格式 | false |
| canal.mq.canalBatchSize | 获取canal数据的批次大小 | 50 |
| canal.mq.canalGetTimeout | 获取canal数据的超时时间 | 100 |
| canal.mq.accessChannel = local | 是否为阿里云模式,可选值local/cloud | local |
| canal.mq.database.hash | 是否开启database混淆hash,确保不同库的数据可以均匀分散,如果关闭可以确保只按照业务字段做MQ分区计算 | true |
| canal.mq.send.thread.size | MQ消息发送并行度 | 30 |
| canal.mq.build.thread.size | MQ消息构建并行度 | 8 |
| ------ | ----------- | ------- |
| kafka.bootstrap.servers | kafka服务端地址 | 127.0.0.1:9092 |
| kafka.acks | kafka为ProducerConfig.ACKS_CONFIG | all |
| kafka.compression.type | 压缩类型 | none |
| kafka.batch.size | kafka为ProducerConfig.BATCH_SIZE_CONFIG | 16384 |
| kafka.linger.ms | kafka为ProducerConfig.LINGER_MS_CONFIG , 如果是flatMessage格式建议将该值调大, 如: 200 | 1 |
| kafka.max.request.size | kafka为ProducerConfig.MAX_REQUEST_SIZE_CONFIG | 1048576 |
| kafka.buffer.memory | kafka为ProducerConfig.BUFFER_MEMORY_CONFIG | 33554432 |
| kafka.max.in.flight.requests.per.connection | kafka为ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION | 1 |
| kafka.retries | 发送失败重试次数 | 0 |
| kafka.kerberos.enable | kerberos认证 | false |
| kafka.kerberos.krb5.file | kerberos认证 | ../conf/kerberos/krb5.conf |
| kafka.kerberos.jaas.file | kerberos认证 | ../conf/kerberos/jaas.conf |
| ------ | ----------- | ------- |
| rocketmq.producer.group | rocketMQ为ProducerGroup名 | test |
| rocketmq.enable.message.trace | 是否开启message trace | false |
| rocketmq.customized.trace.topic | message trace的topic | 无 |
| rocketmq.namespace | rocketmq的namespace | 无 |
| rocketmq.namesrv.addr | rocketmq的namesrv地址 | 127.0.0.1:9876 |
| rocketmq.retry.times.when.send.failed | 重试次数 | 0 |
| rocketmq.vip.channel.enabled | rocketmq是否开启vip channel | false |
| rocketmq.tag | rocketmq的tag配置 | 空值 |
| --- | --- | --- |
| rabbitmq.host | rabbitMQ配置 | 无 |
| rabbitmq.virtual.host | rabbitMQ配置 | 无 |
| rabbitmq.exchange | rabbitMQ配置 | 无 |
| rabbitmq.username | rabbitMQ配置 | 无 |
| rabbitmq.password | rabbitMQ配置 | 无 |
| rabbitmq.deliveryMode | rabbitMQ配置 | 无 |
| --- | --- | --- |
| pulsarmq.serverUrl | pulsarmq配置 | 无 |
| pulsarmq.roleToken | pulsarmq配置 | 无 |
| pulsarmq.topicTenantPrefix | pulsarmq配置 | 无 |
| --- | --- | --- |
| canal.mq.topic | mq里的topic名 | 无 |
| canal.mq.dynamicTopic | mq里的动态topic规则, 1.1.3版本支持 | 无 |
| canal.mq.partition | 单队列模式的分区下标, | 1 |
| canal.mq.enableDynamicQueuePartition | 动态获取MQ服务端的分区数,如果设置为true之后会自动根据topic获取分区数替换canal.mq.partitionsNum的定义,目前主要适用于RocketMQ | false |
| canal.mq.partitionsNum | 散列模式的分区数 | 无 |
| canal.mq.dynamicTopicPartitionNum | mq里的动态队列分区数,比如针对不同topic配置不同partitionsNum | 无 |
| canal.mq.partitionHash | 散列规则定义 | 无 |
canal 1.1.3版本之后, 支持配置格式:schema 或 schema.table,多个配置之间使用逗号或分号分隔
为满足更大的灵活性,允许对匹配条件的规则指定发送的topic名字,配置格式:topicName:schema 或 topicName:schema.table
大家可以结合自己的业务需求,设置匹配规则,建议MQ开启自动创建topic的能力
canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
注意:大家可以结合自己的业务需求,设置匹配规则,多条匹配规则之间是按照顺序进行匹配(命中一条规则就返回)
其他详细参数可参考Canal AdminGuide
binlog本身是有序的,写入到mq之后如何保障顺序是很多人会比较关注,在issue里也有非常多人咨询了类似的问题,这里做一个统一的解答
1.1.5版本可以在5k~50k左右,具体可参考:Canal-MQ-Performance
# 配置ak/sk canal.aliyun.accessKey = XXX canal.aliyun.secretKey = XXX # 配置topic canal.mq.accessChannel = cloud canal.mq.servers = 内网接入点 canal.mq.producerGroup = GID_**group(在后台创建) canal.mq.namespace = rocketmq实例id canal.mq.topic=(在后台创建)
# canal.properties配置文件 kafka.kerberos.enable = true kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf" kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
cd /usr/local/canal/ sh bin/startup.sh
a.查看 logs/canal/canal.log
vi logs/canal/canal.log
b. 查看instance的日志:
vi logs/example/example.log
cd /usr/local/canal/ sh bin/stop.sh
canal.client下有对应的MQ数据消费的样例工程,包含数据编解码的功能
© 2023 gitHub, Inc.
1.通过 destination 产生特定的 CanalInstance
来源地址:https://blog.csdn.net/weixin_43241803/article/details/129562160
--结束END--
本文标题: Canal——数据同步
本文链接: https://www.lsjlt.com/news/422780.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-08
2024-05-08
2024-05-08
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0