通过DF,spark可以跟大量各型的数据源(文件/数据库/大数据)进行交互。前面我们已经看到DF可以生成视图,这就是一个非常使用的功能。 简单的读写流程如下: 通过read方法拿到DataFrameReader对象,与之类似的就有D

通过DF,spark可以跟大量各型的数据源(文件/数据库/大数据)进行交互。前面我们已经看到DF可以生成视图,这就是一个非常使用的功能。
简单的读写流程如下:

通过read方法拿到DataFrameReader对象,与之类似的就有DataFrameWriter对象,通过DF的write方法拿到,通过其save方法将数据保存到文件或数据库。
Spark官方列出的支持的数据格式有:
我们来尝试几个例子。
我们的json文件还是之前那种不规范格式,我期望读到DF后能变成规范的格式:

这样执行会报错,说文件已经存在。

于是换一个文件people1.json,这样会生成一个文件夹people1.json,而任务报错:

网上找了一个答案试一下:Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$windows.access0(Ljava/lang/String;I)Z - Stack Overflow
到https://GitHub.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin 下载hadoop.dll到hadoop的bin目录,执行了一下倒是没报错(看来只是win系统的原因,linux应该不报错吧),产生了一个文件夹:

真奇怪,为什么spark非要使用parquet呢?可这样保存了该咋用呢?
根据 Parquet Files - Spark 3.2.0 Documentation (apache.org) 的说明,Parquet是apache的一款列式存储数据文件。spark会自动解析它的格式(有哪些字段),并把每一列都作为可空的。主要还是在hadoop相关的环境下使用。
上面生成的parquet文件时可以直接读取的。和读取json文件一样,spark提供了parquet()方法:
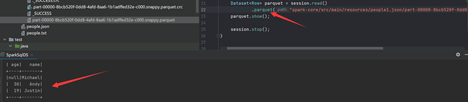
除了save方法,spark也支持通过parquet方法直接保存:


这种方式对于我们来说可能是使用最多的。从数据库中读取数据,经过处理再写回到数据库。
使用JDBC连接有两种方法,第一种方法是通过option传入连接参数:
直接执行会报错,因为找不到数据库驱动

通过Maven引入驱动(实际开发中如果不是使用maven项目,需要把驱动jar包放到服务器上指定classpath)即可成功

除了option参数,spark还提供了通过Jdbc方法来生成DF,这样没有load的显式过程:

可以看到代码更短更面向对象,所以推荐第二种。
另外库名可以放到url中也可以放到表名前面。下面这样也可以,这是驱动提供的能力,和编码无关

现在要把一个DF保存到数据库,使用write即可:
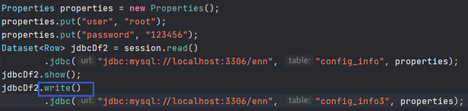
注意要保存的表不能提前存在,不然会说表已经有了。那spark自己怎么创建表呢?它会根据推断的类型创建一个字段都可空的表:

如果想追加数据呢?总不能每次都创建新表吧。可以使用mode方法指定,可以看到插入了两遍:
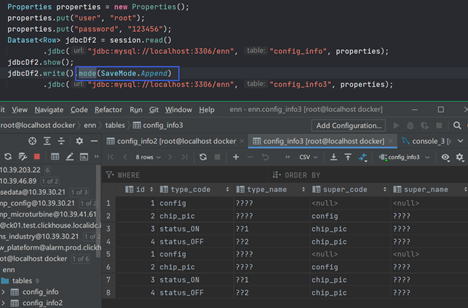
还有一个问题是汉字编码问题,我们需要指定一下:

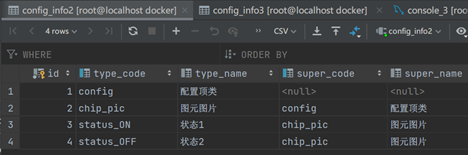
这里使用一张已经存在的表,表定义是复制的原始表:
--结束END--
本文标题: Spark3 学习【基于Java】4. Spark-Sql数据源
本文链接: https://www.lsjlt.com/news/8998.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-04-03
2024-04-03
2024-04-01
2024-01-21
2024-01-21
2024-01-21
2024-01-21
2023-12-23
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0