Python 官方文档:入门教程 => 点击学习
目录前言时间序列的相关检验白噪声检验平稳性检验自相关和偏相关分析移动平均算法简单移动平均法简单指数平滑法霍尔特(Holt)线性趋势法Holt-Winters季节性预测模型ARIMA模
时间序列分析是基于随机过程理论和数理统计学方法:
时间序列分析主要通过statsmodel库的tsa模块完成:
如果为白噪声数据(即独立分布的随机数据),说明其没有任何有用的信息
## 输出高清图像
%config InlineBackend.figure_fORMat = 'retina'
%matplotlib inline
## 图像显示中文的问题
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font= "Kaiti",style="ticks",font_scale=1.4)## 导入会使用到的相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import *
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.tsa.api import SimpleExpSmoothing,Holt,ExponentialSmoothing,AR,ARIMA,ARMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import pmdarima as pm
from sklearn.metrics import mean_absolute_error
import pyflux as pf
from fbprophet import Prophet
## 忽略提醒
import warnings
warnings.filterwarnings("ignore")## 读取时间序列数据,该数据包含:X1为飞机乘客数据,X2为一组随机数据
df = pd.read_csv("data/chap6/timeserise.csv")
## 查看数据的变化趋势
df.plot(kind = "line",figsize = (10,6))
plt.grid()
plt.title("时序数据")
plt.show()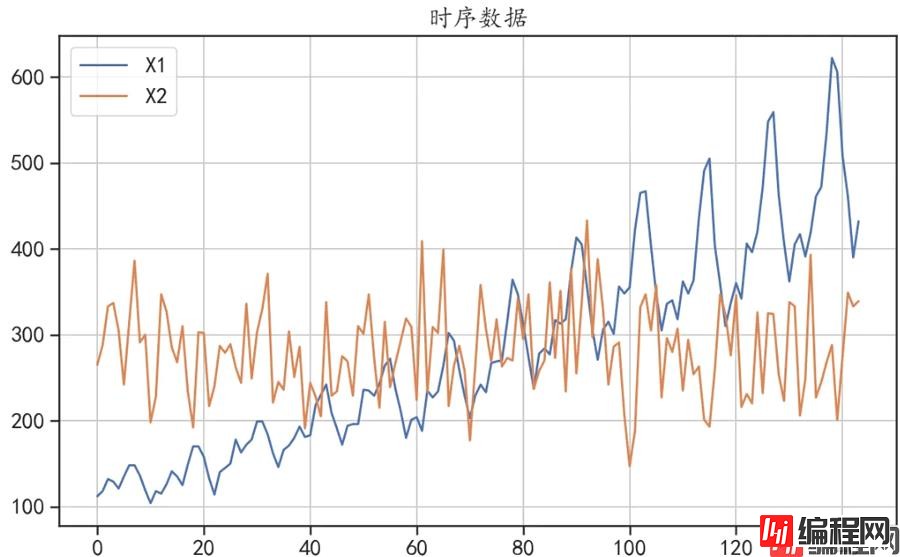
## 白噪声检验Ljung-Box检验
## 该检验用来检查序列是否为随机序列,如果是随机序列,那它们的值之间没有任何关系
## 使用LB检验来检验序列是否为白噪声,原假设为在延迟期数内序列之间相互独立。
lags = [4,8,16,32]
LB = sm.stats.diagnostic.acorr_ljungbox(df["X1"],lags = lags,return_df = True)
print("序列X1的检验结果:\n",LB)
LB = sm.stats.diagnostic.acorr_ljungbox(df["X2"],lags = lags,return_df = True)
print("序列X2的检验结果:\n",LB)
## 如果P值小于0.05,说明序列之间不独立,不是白噪声
'''
序列X1的检验结果:
lb_stat lb_pvalue
4 427.738684 2.817731e-91
8 709.484498 6.496271e-148
16 1289.037076 1.137910e-264
32 1792.523003 0.000000e+00
序列X2的检验结果:
lb_stat lb_pvalue
4 1.822771 0.768314
8 8.452830 0.390531
16 15.508599 0.487750
32 28.717743 0.633459
'''在延迟阶数为[4,6,16,32]的情况下,序列X1的LB检验P值均小于0.05,即该数据不是随机的。有规律可循,有分析价值,而序列X2的LB检验P值均大于0.05,该数据为白噪声,没有分析价值
时间序列是否平稳,对选择预测的数学模型非常关键
如果数据是平稳的,可以使用自回归平均移动模型(ARMA)
如果数据是不平稳的,可以使用差分移动自回归平均移动模型(ARIMA)
## 序列的单位根检验,即检验序列的平稳性
dftest = adfuller(df["X2"],autolag='BIC')
dfoutput = pd.Series(dftest[0:4], index=['adf','p-value','usedlag','Number of Observations Used'])
print("X2单位根检验结果:\n",dfoutput)
dftest = adfuller(df["X1"],autolag='BIC')
dfoutput = pd.Series(dftest[0:4], index=['adf','p-value','usedlag','Number of Observations Used'])
print("X1单位根检验结果:\n",dfoutput)
## 对X1进行一阶差分后的序列进行检验
X1diff = df["X1"].diff().dropna()
dftest = adfuller(X1diff,autolag='BIC')
dfoutput = pd.Series(dftest[0:4], index=['adf','p-value','usedlag','Number of Observations Used'])
print("X1一阶差分单位根检验结果:\n",dfoutput)
## 一阶差分后 P值大于0.05, 小于0.1,可以认为其是平稳的
'''
X2单位根检验结果:
adf -1.124298e+01
p-value 1.788000e-20
usedlag 0.000000e+00
Number of Observations Used 1.430000e+02
dtype: float64
X1单位根检验结果:
adf 0.815369
p-value 0.991880
usedlag 13.000000
Number of Observations Used 130.000000
dtype: float64
X1一阶差分单位根检验结果:
adf -2.829267
p-value 0.054213
usedlag 12.000000
Number of Observations Used 130.000000
dtype: float64
'''序列X2的检验P值小于0.05,说明X2是一个平稳时间序列(该序列是白噪声,白噪声序列是平稳序列)
序列X1的检验P值远大于0.05,说明不平稳,而其一阶差分后的结果,P值大于0.05,但小于0.1,可以认为平稳
针对数据的平稳性检验,还可以使用KPSS检验,其原假设该序列是平稳的,该检验可以用kpss()函数完成
## KPSS检验的原假设为:序列x是平稳的。
## 对序列X2使用KPSS检验平稳性
dfkpss = kpss(df["X2"])
dfoutput = pd.Series(dfkpss[0:3], index=["kpss_stat"," p-value"," usedlag"])
print("X2 KPSS检验结果:\n",dfoutput)
## 接受序列平稳的原假设
## 对序列X1使用KPSS检验平稳性
dfkpss = kpss(df["X1"])
dfoutput = pd.Series(dfkpss[0:3], index=["kpss_stat"," p-value"," usedlag"])
print("X1 KPSS检验结果:\n",dfoutput)
## 拒绝序列平稳的原假设
## 对序列X1使用KPSS检验平稳性
dfkpss = kpss(X1diff)
dfoutput = pd.Series(dfkpss[0:3], index=["kpss_stat"," p-value"," usedlag"])
print("X1一阶差分KPSS检验结果:\n",dfoutput)
## 接受序列平稳的原假设
'''
X2 KPSS检验结果:
kpss_stat 0.087559
p-value 0.100000
usedlag 14.000000
dtype: float64
X1 KPSS检验结果:
kpss_stat 1.052175
p-value 0.010000
usedlag 14.000000
dtype: float64
X1一阶差分KPSS检验结果:
kpss_stat 0.05301
p-value 0.10000
usedlag 14.00000
dtype: float64
'''ARIMA(p,d,q)模型
## 检验ARIMA模型的参数d
X1d = pm.arima.ndiffs(df["X1"], alpha=0.05, test="kpss", max_d=3)
print("使用KPSS方法对序列X1的参数d取值进行预测,d = ",X1d)
X1diffd = pm.arima.ndiffs(X1diff, alpha=0.05, test="kpss", max_d=3)
print("使用KPSS方法对序列X1一阶差分后的参数d取值进行预测,d = ",X1diffd)
X2d = pm.arima.ndiffs(df["X2"], alpha=0.05, test="kpss", max_d=3)
print("使用KPSS方法对序列X2的参数d取值进行预测,d = ",X2d)
'''
使用KPSS方法对序列X1的参数d取值进行预测,d = 1
使用KPSS方法对序列X1一阶差分后的参数d取值进行预测,d = 0
使用KPSS方法对序列X1的参数d取值进行预测,d = 0
'''针对SARIMA模型,还有一个季节性平稳性参数D
## 检验SARIMA模型的参数季节阶数D
X1d = pm.arima.nsdiffs(df["X1"], 12, max_D=2)
print("对序列X1的季节阶数D取值进行预测,D = ",X1d)
X1diffd = pm.arima.nsdiffs(X1diff, 12, max_D=2)
print("序列X1一阶差分后的季节阶数D取值进行预测,D = ",X1diffd)
'''
对序列X1的季节阶数D取值进行预测,D = 1
序列X1一阶差分后的季节阶数D取值进行预测,D = 1
'''## 对随机序列X2进行自相关和偏相关分析可视化
fig = plt.figure(figsize=(16,5))
plt.subplot(1,3,1)
plt.plot(df["X2"],"r-")
plt.grid()
plt.title("X2序列波动")
ax = fig.add_subplot(1,3,2)
plot_acf(df["X2"], lags=60,ax = ax)
plt.grid()
ax = fig.add_subplot(1,3,3)
plot_pacf(df["X2"], lags=60,ax = ax)
plt.grid()
plt.tight_layout()
plt.show()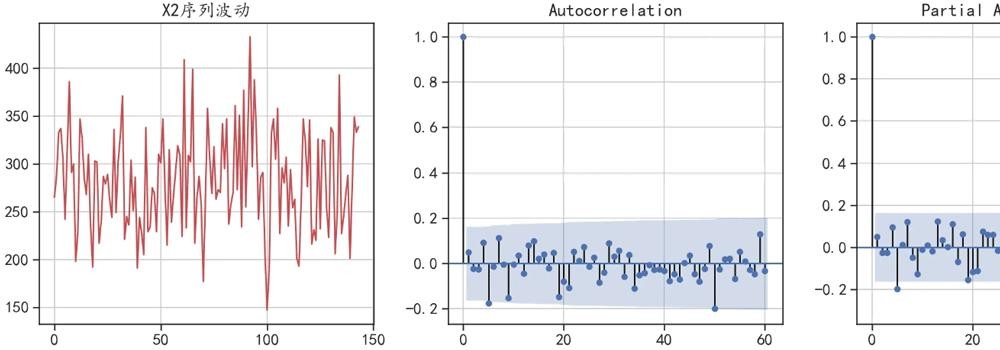
在图像中滞后0表示自己和自己的相关性,恒等于1。不用于确定p和q。
## 对非随机序列X1进行自相关和偏相关分析可视化
fig = plt.figure(figsize=(16,5))
plt.subplot(1,3,1)
plt.plot(df["X1"],"r-")
plt.grid()
plt.title("X1序列波动")
ax = fig.add_subplot(1,3,2)
plot_acf(df["X1"], lags=60,ax = ax)
plt.grid()
ax = fig.add_subplot(1,3,3)
plot_pacf(df["X1"], lags=60,ax = ax)
plt.ylim([-1,1])
plt.grid()
plt.tight_layout()
plt.show()
## 对非随机序列X1一阶差分后的序列进行自相关和偏相关分析可视化
fig = plt.figure(figsize=(16,5))
plt.subplot(1,3,1)
plt.plot(X1diff,"r-")
plt.grid()
plt.title("X1序列一阶差分后波动")
ax = fig.add_subplot(1,3,2)
plot_acf(X1diff, lags=60,ax = ax)
plt.grid()
ax = fig.add_subplot(1,3,3)
plot_pacf(X1diff, lags=60,ax = ax)
plt.grid()
plt.tight_layout()
plt.show()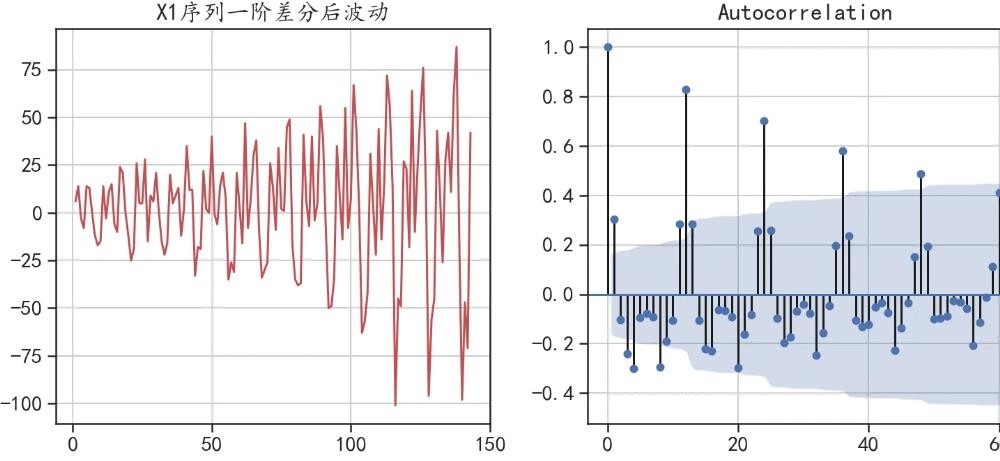
ARMA(p,q)中,自相关系数的滞后,对应着参数q;偏相关系数的滞后对应着参数p。
## 时间序列的分解
## 通过观察序列X1,可以发现其既有上升的趋势,也有周期性的趋势,所以可以将该序列进行分解
## 使用乘法模型分解结果(通常适用于有增长趋势的序列)
X1decomp = pm.arima.decompose(df["X1"].values,"multiplicative", m=12)
## 可视化出分解的结果
ax = pm.utils.decomposed_plot(X1decomp,figure_kwargs = {"figsize": (10, 6)},
show=False)
ax[0].set_title("乘法模型分解结果")
plt.show()
## 使用加法模型分解结果(通常适用于平稳趋势的序列)
X1decomp = pm.arima.decompose(X1diff.values,"additive", m=12)
## 可视化出分解的结果
ax = pm.utils.decomposed_plot(X1decomp,figure_kwargs = {"figsize": (10, 6)},
show=False)
ax[0].set_title("加法模型分解结果")
plt.show()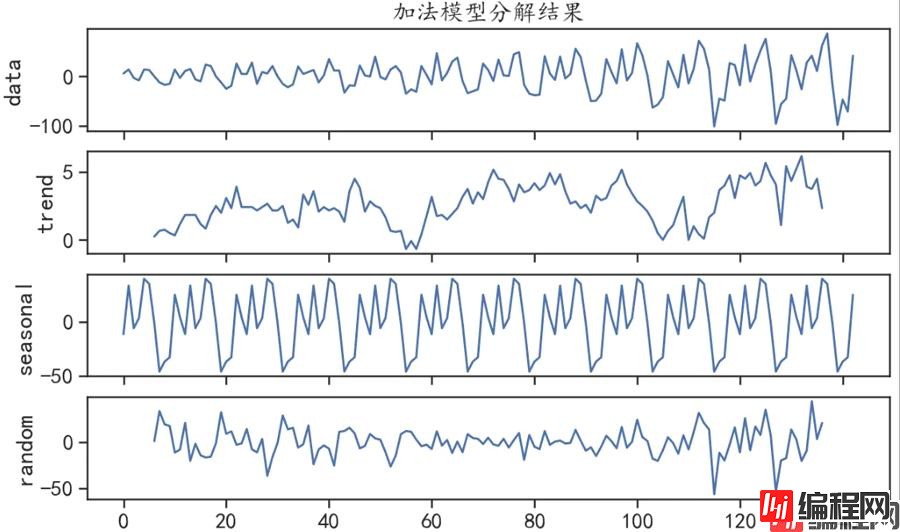
## 数据准备
## 对序列X1进行切分,后面的24个数据用于测试集
train = pd.DataFrame(df["X1"][0:120])
test = pd.DataFrame(df["X1"][120:])
## 可视化切分后的数据
train["X1"].plot(figsize=(14,7), title= "乘客数量数据",label = "X1 train")
test["X1"].plot(label = "X1 test")
plt.legend()
plt.grid()
plt.show()
print(train.shape)
print(test.shape)
df["X1"].shape
'''
(120, 1)
(24, 1)
(144,)
'''## 简单移动平均进行预测
y_hat_avg = test.copy(deep = False)
y_hat_avg["moving_avg_forecast"] = train["X1"].rolling(24).mean().iloc[-1]
## 可视化出预测结果
plt.figure(figsize=(14,7))
train["X1"].plot(figsize=(14,7),label = "X1 train")
test["X1"].plot(label = "X1 test")
y_hat_avg["moving_avg_forecast"].plot(style="g--o", lw=2,
label="移动平均预测")
plt.legend()
plt.grid()
plt.title("简单移动平均预测")
plt.show()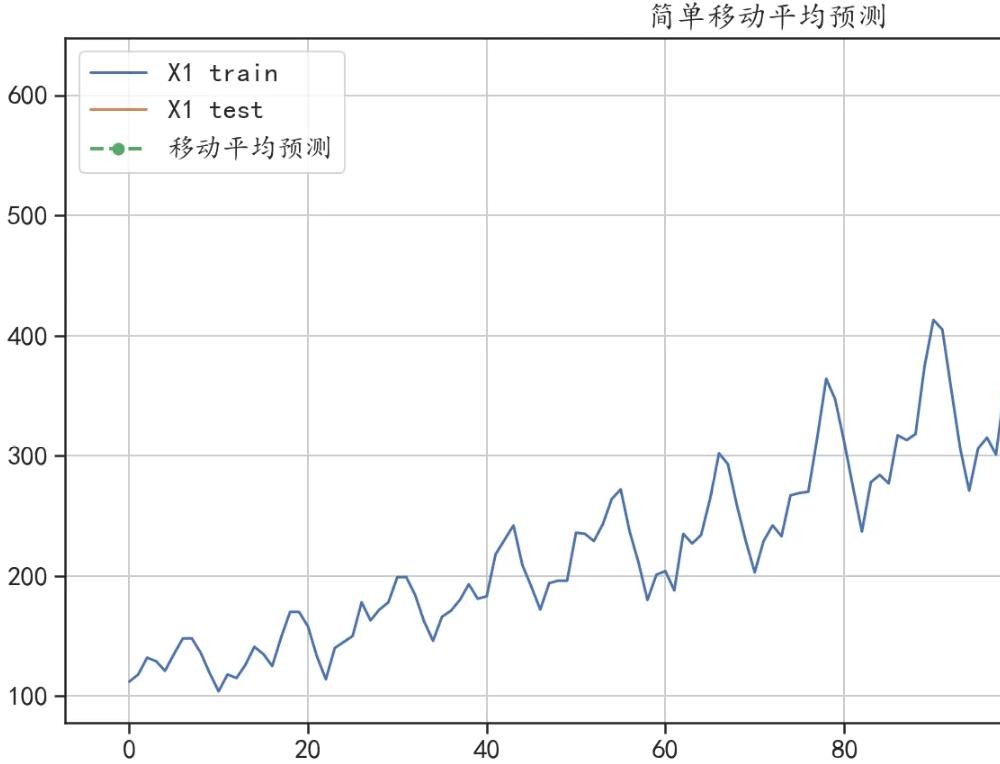
## 计算预测结果和真实值的误差
print("预测绝对值误差:",mean_absolute_error(test["X1"],y_hat_avg["moving_avg_forecast"]))
'''
预测绝对值误差: 82.55208333333336
'''## 数据准备
y_hat_avg = test.copy(deep = False)
## 模型构建
model1 = SimpleExpSmoothing(train["X1"].values).fit(smoothing_level=0.15)
y_hat_avg["exp_smooth_forecast1"] = model1.forecast(len(test))
model2 = SimpleExpSmoothing(train["X1"].values).fit(smoothing_level=0.5)
y_hat_avg["exp_smooth_forecast2"] = model2.forecast(len(test))
## 可视化出预测结果
plt.figure(figsize=(14,7))
train["X1"].plot(figsize=(14,7),label = "X1 train")
test["X1"].plot(label = "X1 test")
y_hat_avg["exp_smooth_forecast1"].plot(style="g--o", lw=2,
label="smoothing_level=0.15")
y_hat_avg["exp_smooth_forecast2"].plot(style="g--s", lw=2,
label="smoothing_level=0.5")
plt.legend()
plt.grid()
plt.title("简单指数平滑预测")
plt.show()
## 计算预测结果和真实值的误差
print("smoothing_level=0.15,预测绝对值误差:",
mean_absolute_error(test["X1"],y_hat_avg["exp_smooth_forecast1"]))
print("smoothing_level=0.5,预测绝对值误差:",
mean_absolute_error(test["X1"],y_hat_avg["exp_smooth_forecast2"]))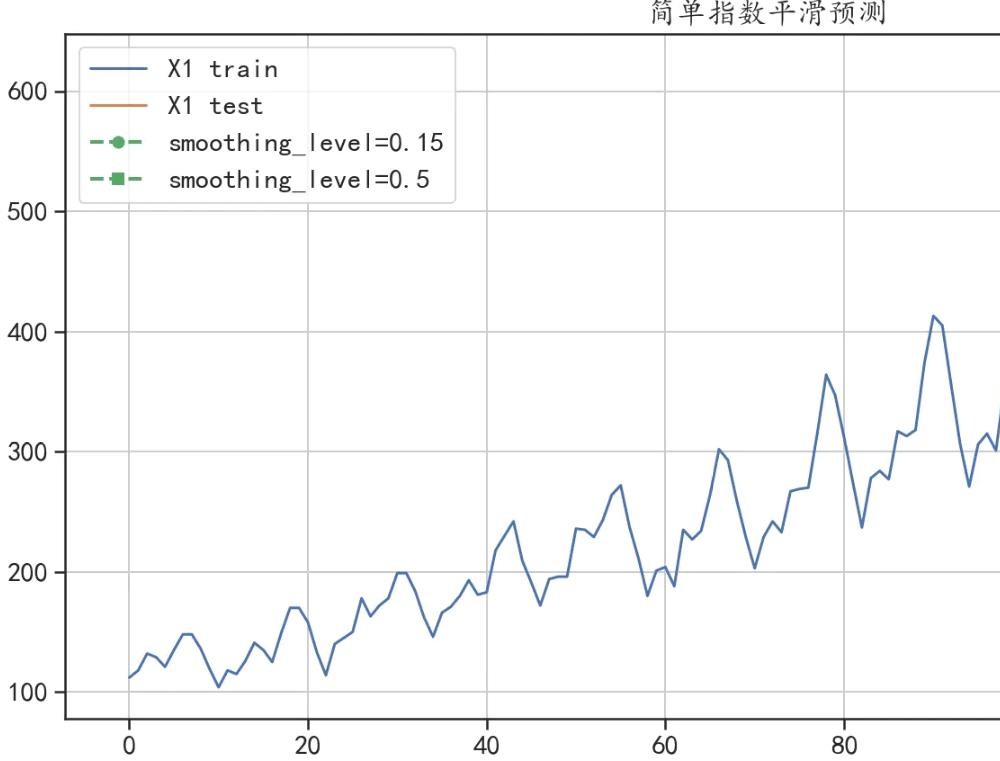
smoothing_level=0.15,预测绝对值误差: 81.10115706423566
smoothing_level=0.5,预测绝对值误差: 106.813228720506
## 数据准备
y_hat_avg = test.copy(deep = False)
## 模型构建
model1 = Holt(train["X1"].values).fit(smoothing_level=0.1, smoothing_slope = 0.05)
y_hat_avg["holt_forecast1"] = model1.forecast(len(test))
model2 = Holt(train["X1"].values).fit(smoothing_level=0.1, smoothing_slope = 0.25)
y_hat_avg["holt_forecast2"] = model2.forecast(len(test))
## 可视化出预测结果
plt.figure(figsize=(14,7))
train["X1"].plot(figsize=(14,7),label = "X1 train")
test["X1"].plot(label = "X1 test")
y_hat_avg["holt_forecast1"].plot(style="g--o", lw=2,
label="Holt线性趋势法(1)")
y_hat_avg["holt_forecast2"].plot(style="g--s", lw=2,
label="Holt线性趋势法(2)")
plt.legend()
plt.grid()
plt.title("Holt线性趋势法预测")
plt.show()
## 计算预测结果和真实值的误差
print("smoothing_slope = 0.05,预测绝对值误差:",
mean_absolute_error(test["X1"],y_hat_avg["holt_forecast1"]))
print("smoothing_slope = 0.25,预测绝对值误差:",
mean_absolute_error(test["X1"],y_hat_avg["holt_forecast2"]))
smoothing_slope = 0.05,预测绝对值误差: 54.727467142360275
smoothing_slope = 0.25,预测绝对值误差: 69.79052992788556
## 数据准备
y_hat_avg = test.copy(deep = False)
## 模型构建
model1 = ExponentialSmoothing(train["X1"].values,
seasonal_periods=12, # 周期性为12
trend="add", seasonal="add").fit()
y_hat_avg["holt_winter_forecast1"] = model1.forecast(len(test))
## 可视化出预测结果
plt.figure(figsize=(14,7))
train["X1"].plot(figsize=(14,7),label = "X1 train")
test["X1"].plot(label = "X1 test")
y_hat_avg["holt_winter_forecast1"].plot(style="g--o", lw=2,
label="Holt-Winters")
plt.legend()
plt.grid()
plt.title("Holt-Winters季节性预测模型")
plt.show()
## 计算预测结果和真实值的误差
print("Holt-Winters季节性预测模型,预测绝对值误差:",
mean_absolute_error(test["X1"],y_hat_avg["holt_winter_forecast1"]))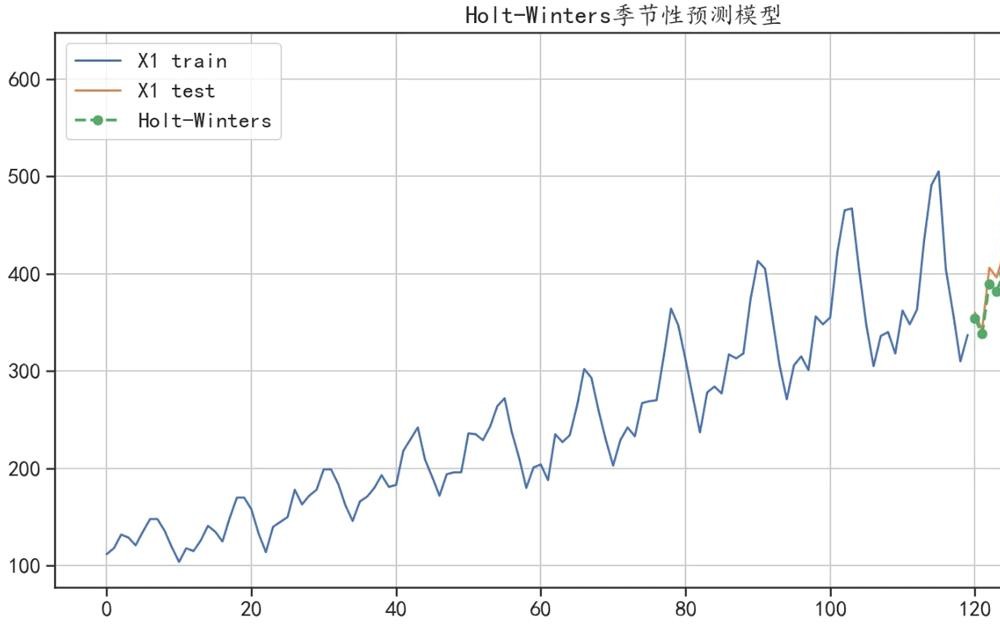
Holt-Winters季节性预测模型,预测绝对值误差: 30.06821059070873
## 使用AR模型对乘客数据进行预测
## 经过前面序列的偏相关系数的可视化结果,使用AR(2)模型可对序列进行建模
## 数据准备
y_hat = test.copy(deep = False)
## 模型构建
ar_model = ARMA(train["X1"].values,order = (2,0)).fit()
## 输出拟合模型的结果
print(ar_model.summary())
## AIC=1141.989;BIC= 1153.138;两个系数是显著的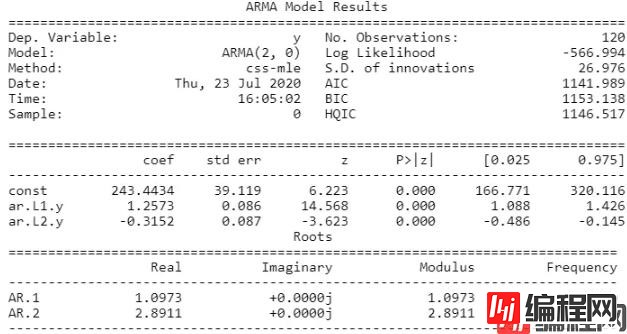
## 查看模型的拟合残差分布
fig = plt.figure(figsize=(12,5))
ax = fig.add_subplot(1,2,1)
plt.plot(ar_model.resid)
plt.title("AR(2)残差曲线")
## 检查残差是否符合正太分布
ax = fig.add_subplot(1,2,2)
sm.qqplot(ar_model.resid, line='q', ax=ax)
plt.title("AR(2)残差Q-Q图")
plt.tight_layout()
plt.show()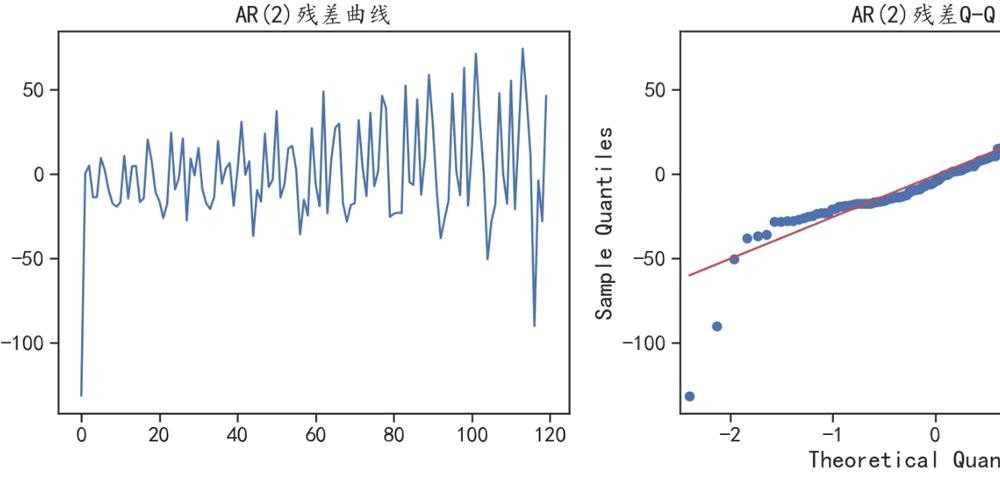
## 预测未来24个数据,并输出95%置信区间
pre, se, conf = ar_model.forecast(24, alpha=0.05)
## 整理数据
y_hat["ar2_pre"] = pre
y_hat["ar2_pre_lower"] = conf[:,0]
y_hat["ar2_pre_upper"] = conf[:,1]
## 可视化出预测结果
plt.figure(figsize=(14,7))
train["X1"].plot(figsize=(14,7),label = "X1 train")
test["X1"].plot(label = "X1 test")
y_hat["ar2_pre"].plot(style="g--o", lw=2,label="AR(2)")
## 可视化出置信区间
plt.fill_between(y_hat.index, y_hat["ar2_pre_lower"],
y_hat["ar2_pre_upper"],color='k',alpha=.15,
label = "95%置信区间")
plt.legend()
plt.grid()
plt.title("AR(2)模型")
plt.show()
# 计算预测结果和真实值的误差
print("AR(2)模型预测的绝对值误差:",
mean_absolute_error(test["X1"],y_hat["ar2_pre"]))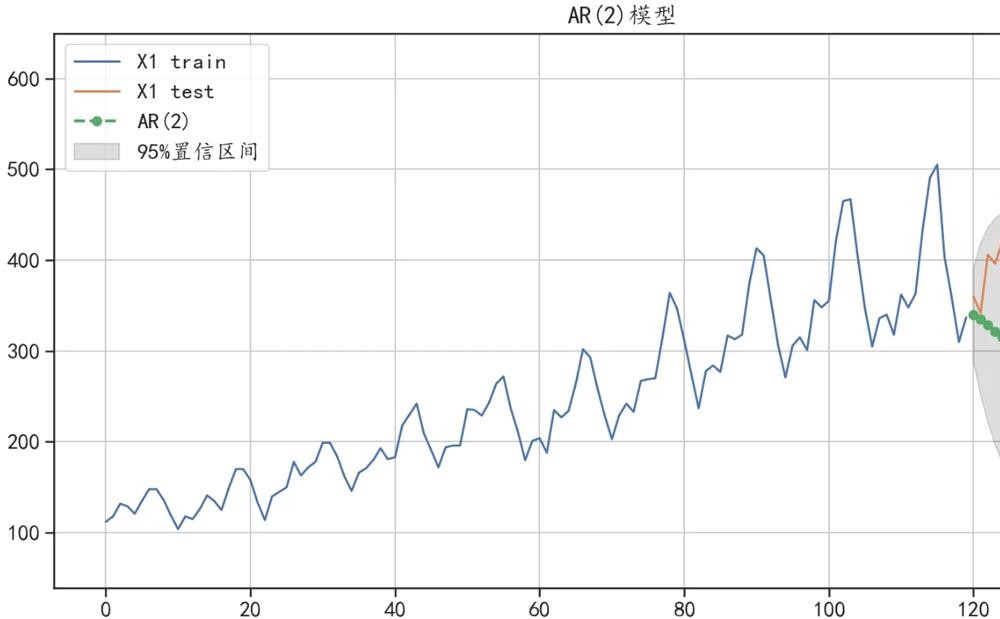
AR(2)模型预测的绝对值误差: 165.79608244918572
可以发现使用AR(2)的预测效果并不好
## 尝试使用ARMA模型进行预测
## 根据前面的自相关系数和偏相关系数,为了降低模型的复杂读,可以使用ARMA(2,1)
## 数据准备
y_hat = test.copy(deep = False)
## 模型构建
arma_model = ARMA(train["X1"].values,order = (2,1)).fit()
## 输出拟合模型的结果
print(arma_model.summary())
## AIC=1141.989;BIC= 1153.138;两个系数是显著的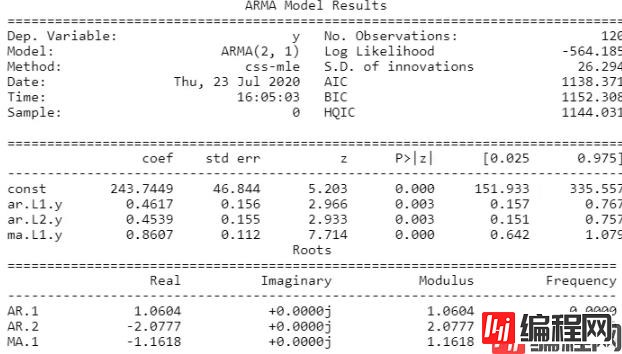
## 查看模型的拟合残差分布
fig = plt.figure(figsize=(12,5))
ax = fig.add_subplot(1,2,1)
plt.plot(arma_model.resid)
plt.title("ARMA(2,1)残差曲线")
## 检查残差是否符合正太分布
ax = fig.add_subplot(1,2,2)
sm.qqplot(arma_model.resid, line='q', ax=ax)
plt.title("ARMA(2,1)残差Q-Q图")
plt.tight_layout()
plt.show()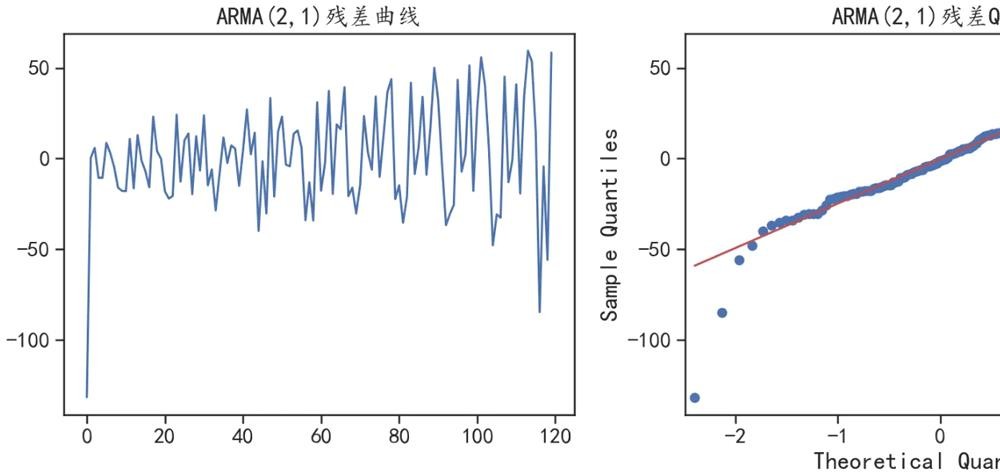
## 预测未来24个数据,并输出95%置信区间
pre, se, conf = arma_model.forecast(24, alpha=0.05)
## 整理数据
y_hat["arma_pre"] = pre
y_hat["arma_pre_lower"] = conf[:,0]
y_hat["arma_pre_upper"] = conf[:,1]
## 可视化出预测结果
plt.figure(figsize=(14,7))
train["X1"].plot(figsize=(14,7),label = "X1 train")
test["X1"].plot(label = "X1 test")
y_hat["arma_pre"].plot(style="g--o", lw=2,label="ARMA(2,1)")
## 可视化出置信区间
plt.fill_between(y_hat.index, y_hat["arma_pre_lower"],
y_hat["arma_pre_upper"],color='k',alpha=.15,
label = "95%置信区间")
plt.legend()
plt.grid()
plt.title("ARMA(2,1)模型")
plt.show()
# 计算预测结果和真实值的误差
print("ARMA模型预测的绝对值误差:",
mean_absolute_error(test["X1"],y_hat["arma_pre"]))
ARMA模型预测的绝对值误差: 147.26531763335154
## 自动搜索合适的参数
model = pm.auto_arima(train["X1"].values,
start_p=1, start_q=1, # p,q的开始值
max_p=12, max_q=12, # 最大的p和q
d = 0, # 寻找ARMA模型参数
m=1, # 序列的周期
seasonal=False, # 没有季节性趋势
trace=True,error_action='ignore',
suppress_warnings=True, stepwise=True)
print(model.summary())## 使用ARMA(3,2)对测试集进行预测
pre, conf = model.predict(n_periods=24, alpha=0.05,
return_conf_int=True)
## 可视化ARMA(3,2)的预测结果,整理数据
y_hat["arma_pre"] = pre
y_hat["arma_pre_lower"] = conf[:,0]
y_hat["arma_pre_upper"] = conf[:,1]
## 可视化出预测结果
plt.figure(figsize=(14,7))
train["X1"].plot(figsize=(14,7),label = "X1 train")
test["X1"].plot(label = "X1 test")
y_hat["arma_pre"].plot(style="g--o", lw=2,label="ARMA(3,2)")
## 可视化出置信区间
plt.fill_between(y_hat.index, y_hat["arma_pre_lower"],
y_hat["arma_pre_upper"],color='k',alpha=.15,
label = "95%置信区间")
plt.legend()
plt.grid()
plt.title("ARMA(3,2)模型")
plt.show()
# 计算预测结果和真实值的误差
print("ARMA模型预测的绝对值误差:",
mean_absolute_error(test["X1"],y_hat["arma_pre"]))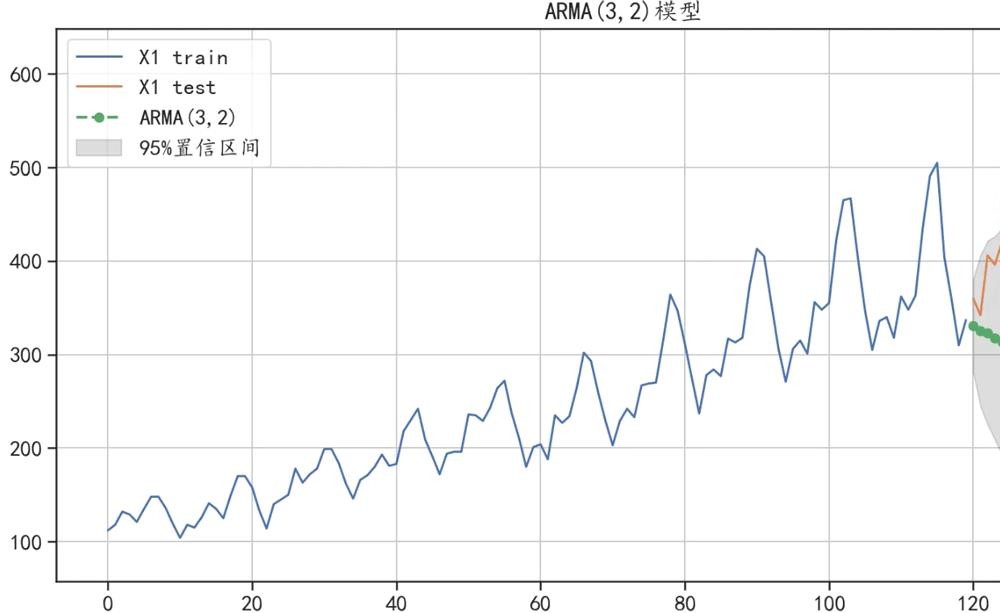
ARMA模型预测的绝对值误差: 158.11464180972925
可以发现使用自动ARMA(3,2)模型的效果并没有ARMA(2,1)的预测效果好
可以将突然增大或突然减小的数据无规律看作异常值
## 使用prophet检测时间序列是否有异常值
## 从1991年2月到2005年5月,每周提供美国成品汽车汽油产品的时间序列(每天数千桶)
## 数据准备
data = pm.datasets.load_gasoline()
datadf = pd.DataFrame({"y":data})
datadf["ds"] = pd.date_range(start="1991-2",periods=len(data),freq="W")
## 可视化时间序列的变化情况
datadf.plot(x = "ds",y = "y",style = "b-o",figsize=(14,7))
plt.grid()
plt.title("时间序列数据的波动情况")
plt.show()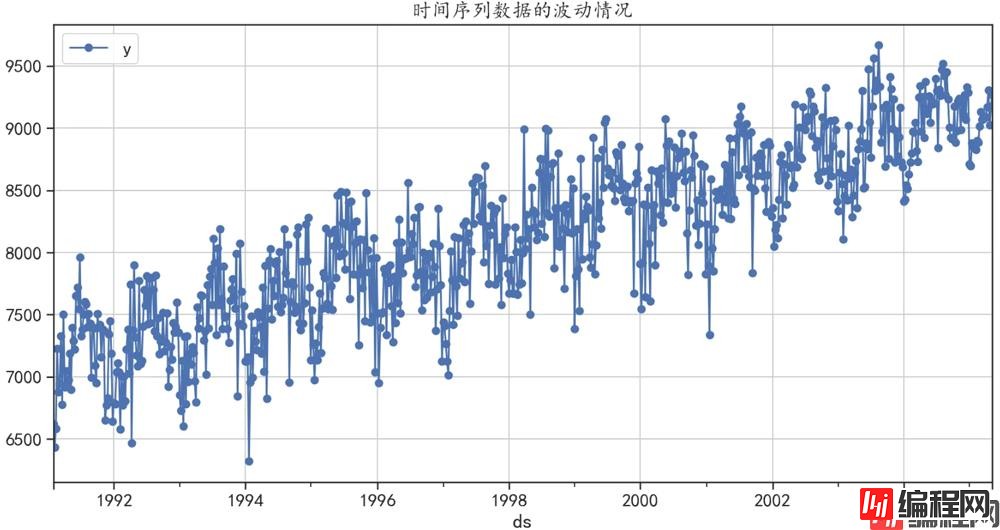
## 对该数据建立一个时间序列模型
np.random.seed(1234) ## 设置随机数种子
model = Prophet(growth="linear",daily_seasonality = False,
weekly_seasonality=False,
seasonality_mode = 'multiplicative',
interval_width = 0.95, ## 获取95%的置信区间
)
model = model.fit(datadf) # 使用数据拟合模型
forecast = model.predict(datadf) # 使用模型对数据进行预测
forecast["y"] = datadf["y"].reset_index(drop = True)
forecast[["ds","y","yhat","yhat_lower","yhat_upper"]].head()| ds | y | yhat | yhat_lower | yhat_upper | |
|---|---|---|---|---|---|
| 0 | 1991-02-03 | 6621.0 | 6767.051491 | 6294.125979 | 7303.352309 |
| 1 | 1991-02-10 | 6433.0 | 6794.736479 | 6299.430616 | 7305.414252 |
| 2 | 1991-02-17 | 6582.0 | 6855.096282 | 6352.579489 | 7379.717614 |
| 3 | 1991-02-24 | 7224.0 | 6936.976642 | 6415.157617 | 7445.523000 |
| 4 | 1991-03-03 | 6875.0 | 6990.511503 | 6489.781400 | 7488.240435 |
## 根据模型预测值的置信区间"yhat_lower"和"yhat_upper"判断样本是否为异常值
def outlier_detection(forecast):
index = np.where((forecast["y"] <= forecast["yhat_lower"])|
(forecast["y"] >= forecast["yhat_upper"]),True,False)
return index
outlier_index = outlier_detection(forecast)
outlier_df = datadf[outlier_index]
print("异常值的数量为:",np.sum(outlier_index))
'''
异常值的数量为: 38
'''## 可视化异常值的结果
fig, ax = plt.subplots()
## 可视化预测值
forecast.plot(x = "ds",y = "yhat",style = "b-",figsize=(14,7),
label = "预测值",ax=ax)
## 可视化出置信区间
ax.fill_between(forecast["ds"].values, forecast["yhat_lower"],
forecast["yhat_upper"],color='b',alpha=.2,
label = "95%置信区间")
forecast.plot(kind = "scatter",x = "ds",y = "y",c = "k",
s = 20,label = "原始数据",ax = ax)
## 可视化出异常值的点
outlier_df.plot(x = "ds",y = "y",style = "rs",ax = ax,
label = "异常值")
plt.legend(loc = 2)
plt.grid()
plt.title("时间序列异常值检测结果")
plt.show()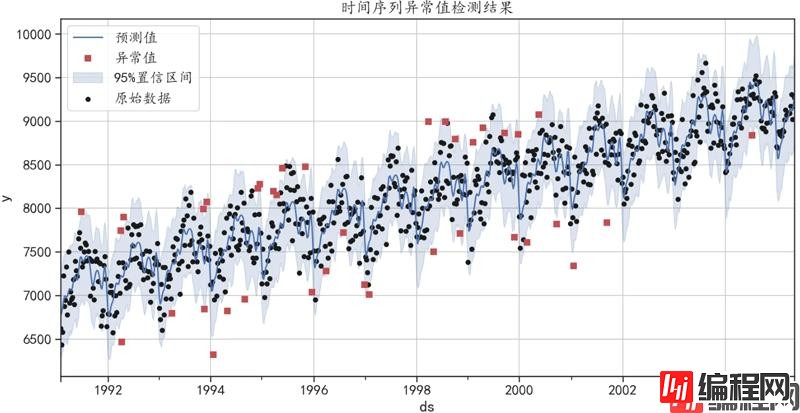
异常值大部分都在置信区间外
到此这篇关于python数据分析之时间序列分析详情的文章就介绍到这了,更多相关Python时间序列分析内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: python数据分析之时间序列分析详情
本文链接: https://www.lsjlt.com/news/119969.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0