目录为啥需要Map结构主流Map结构数组+链表的Map结构hash函数创建Map集合扩容基数扩容Map集合给Map集合添加元素打印Map集合获取Map集合中的指定元素判断键是否存在判
假设,数据很少,十个指头就能数过来,就不需要数据结构了。随便存就行了。既然数据多的问题不可避免,数据多了怎么存储。最简单的就是把一个一个的数据排成一排。这就是数组。数组这种结构,又称为列表List。数组是最简单和直观的数据结构。数组的容量很大,排列紧密,最节省空间,但数组的缺点是查找困难。假设你把100个个人信息放在一个列表里,当需要用到某个人的时候,就会出现“只在此山中,云深不知处”的问题。不知道第几个才是你需要的,所以需要从头开始一个一个的检查,直到找到了你需要的那个人。这个查找花费的时间长度是和人数成正比的。运气最不好的时候,可能找到最后一个人,才找到了你需要的那个人。你看这个查找多慢呀。列表中的总量越多,你的查找时间就可能越长。如果一百万,一千万,甚至更多,可能就根本查不出来了。因为时间太久了。所以这里需要解决这个查找难慢的问题。
我们分析一下为什么会出现查找难的问题,是因为在存信息的时候,根本就没有考虑未来有一天我查的时候,怎么能够方便一点。因为没有瞻前顾后,导致查找时的困难。所以,这次我们存储的时候,就要想好了,怎么能够快速查出来。首先确定一个问题,将来要用什么信息去作匹配。 这个信息一定要具备唯一性。比如说查寻人的信息,身份证id就是一个唯一性的信息,因为每个人的身份证号码都不一样。比方说有100个 个人信息,将来我们要用他们的身份证号去查询。所以存储的时候,不应该一股脑的放进一个列表中,这样不方便查,如果把这100个信息放入列表的位置和他们的身份证号有一个关系。这样当要用身份证号查询时,就能更快的知道存在什么地方了。
还有一个问题是,时间和空间。 我们的理想是查询时间最快 和 用最小的空间。但是实践中发现 鱼和熊掌不可兼得。 不可能使用的空间最小,还能查的又最快。只能浪费一些空间,去获得更快的查询体验,或者使用最少的空间,但是查询慢。就像100个信息,如果只给100个空间的话,正好能装满,一点空间都不浪费,但是查询时间就慢了。但是往往是空间比较便宜,而时间比较宝贵。如果说现在愿意拿出5倍的空间来存储数据, 如何能够让查询的时间更快一些呢?
现在将100个信息,存储在500个空间里。我们的目标是,在将数据存入500个空间时,不再顺序放了,因为这样找的话,就需要一个一个挨着看。每个信息都有一个唯一的信息,如身份证id, 如果有一个函数,输入是身份证号,输出是 存储位置的索引。那么,在存入时,我们先用这个函数,算出存储的位置索引,并存入,当需要取时,只需要将 身份号 放到这个函数中,就可以算出是在哪儿存的索引,直接去取就可以了。 这样查找时间就是1次就找到了,只需要花费计划索引的时间就可以了,这个函数叫哈希函数Hash。 哈希的过程是一个映射关系的计算 。
就拿上面的例子来说, 我们知道有100个元素要存储, 并且准备了500个空间。也就意味着, 哈希函数计算出来的值 必须要在 0-499 之间。 但是输入是一个18位的身份证号。18位数字的所有可能的组合要远大于500个。就可能出现碰撞的问题。 也就是两个不同的初始值,经过哈希函数后,算出来的值是一样的。碰撞是不可避免的,但是好的哈希函数是能够将碰撞控制到一个 非常小的比例。 这也取决与元素的个数 和 总的空间的比例。 显然,空间越大, 碰撞的问题就会越少,但是浪费的空间就越多。 这又是一个 鱼和熊掌的问题。
最后设计出来的Map可以实现无论多少数据都能基本上完成 O(1) 复杂度的查找效率。恐怖把,这也是每门高级语言必备的数据结构,但是在C语言中没有,需要我们自己设计
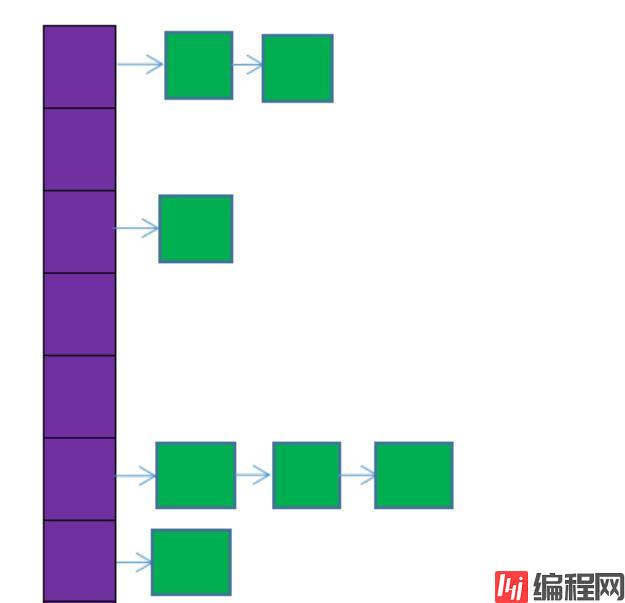
上图的数据结构比较简单就是数组的每个节点都是链表头,当有hash冲突或者取模相同的时候就会进行链表的挂载
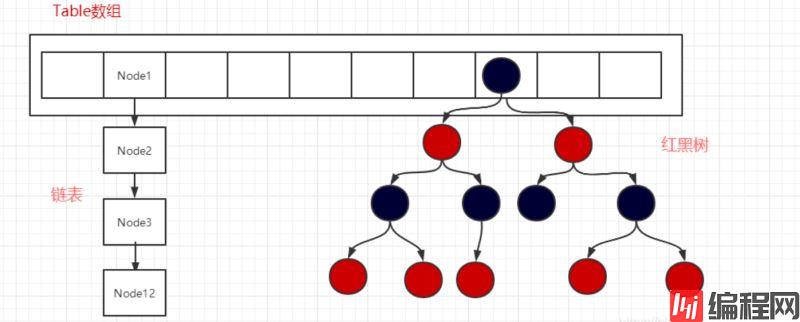
上图的数据结构就比较复杂了,数组+链表+红黑树, 分为2个等级, 链表长度达到 8 就转成红黑树,而当长度降到 6 就转换回去,这体现了时间和空间平衡的思想.
为啥是8按照泊松分布的计算公式计算出了桶中元素个数和概率的对照表,可以看到链表中元素个数为8时的概率已经非常小,再多的就更少了,所以原作者在选择链表元素个数时选择了8,是根据概率统计而选择的。
typedef struct entry {
char * key; // 键
void * value; // 值
struct entry * next; // 冲突链表
} Entry;
typedef int boolean;//定义一个布尔类型
#define TRUE 1
#define FALSE 0
// 哈希表结构体
typedef struct HashMap {
int size; // 集合元素个数
int capacity; // 容量
int nodeLen; //节点长度
Entry **list; // 存储区域
int dilatationCount; //扩容次数
int dilatationSum; //扩容总次数
} HashMap;
// 迭代器结构
typedef struct hashMapiterator {
Entry *nextEntry;// 迭代器当前指向
int count;//迭代次数
HashMap *hashMap;
int index; //位置
}HashMapIterator;
//最好的char类型的hash算法,冲突较少,效率较高
static unsigned int BKDRHash(char *str)
{
unsigned int seed = 131;
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
//hash值长度取模最后获取实际位置的下标
static unsigned int defaultHashCode(HashMap hashMap, char * key){
return BKDRHash(key)% hashMap.capacity;
}
HashMap *createHashMap(int capacity) {
//创建哈希表
HashMap *hashMap= (HashMap *)malloc(sizeof(HashMap));
//创建存储区域
if(capacity<10){
capacity=10;
}
hashMap->size=0;
hashMap->dilatationCount=0;
hashMap->dilatationSum=0;
hashMap->nodeLen=0;
hashMap->capacity=capacity;
hashMap->list = (Entry **)calloc(capacity,sizeof(Entry));
return hashMap;
}//扩容基数
static int expansionBase( HashMap *hashMap){
int len = hashMap->capacity;
int dilatationCount= hashMap->dilatationCount;
hashMap->dilatationSum++;
//基础扩容
len+= (len>=100000000?len*0.2:
len>=50000000?len*0.3:
len>=10000000?len*0.4:
len>=5000000?len*0.5:
len>=1000000?len*0.6:
len>=500000?len*0.7:
len>=100000?len*0.8:
len>=50000?len*0.9:
len*1.0);
hashMap->dilatationCount++;
//频率扩容
if(dilatationCount>=5){
len+= (len>=100000000?len*1:
len>=50000000?len*2:
len>=10000000?len*3:
len>=5000000?len*4:
len>=1000000?len*5:
len>=500000?len*6:
len>=100000?len*7:
len>=50000?len*8:
len>=10000?len*9:
len>=1000?len*10:
len*20);
hashMap->dilatationCount=0;
}
return len;
}//扩容Map集合
static void dilatationHash(HashMap *hashMap){
//原来的容量
int capacity = hashMap->capacity;
//扩容后的容量
hashMap->capacity=expansionBase(hashMap);
//节点长度清空
hashMap->nodeLen=0;
//创建新的存储区域
Entry **newList=(Entry **)calloc(hashMap->capacity,sizeof(Entry));
//遍历旧的存储区域,将旧的存储区域的数据拷贝到新的存储区域
for(int i=0;i<capacity;i++){
Entry *entry=hashMap->list[i];
if(entry!=NULL){
//获取新的存储区域的下标
unsigned int newIndex=defaultHashCode(*hashMap,entry->key);
if(newList[newIndex]==NULL){
Entry *newEntry = (Entry *)malloc(sizeof(Entry));
newEntry->key = entry->key;
newEntry->value = entry->value;
newEntry->next = NULL;
newList[newIndex] = newEntry;
hashMap->nodeLen++;
}else{//那么就是冲突链表添加链表节点
Entry *newEntry = (Entry *)malloc(sizeof(Entry));
newEntry->key = entry->key;
newEntry->value = entry->value;
//将新节点插入到链表头部(这样的好处是插入快,但是不能保证插入的顺序)
newEntry->next = newList[newIndex];
newList[newIndex] = newEntry;
}
//判断节点内链表是否为空
if(entry->next!=NULL){
//遍历链表,将链表节点插入到新的存储区域
Entry *nextEntry=entry->next;
while(nextEntry!=NULL){
//获取新的存储区域的下标
unsigned int newIndex=defaultHashCode(*hashMap,nextEntry->key);
if(newList[newIndex]==NULL){
Entry *newEntry = (Entry *)malloc(sizeof(Entry));
newEntry->key = nextEntry->key;
newEntry->value = nextEntry->value;
newEntry->next = NULL;
newList[newIndex] = newEntry;
hashMap->nodeLen++;
}else{//那么就是冲突链表添加链表节点
Entry *newEntry = (Entry *)malloc(sizeof(Entry));
newEntry->key = nextEntry->key;
newEntry->value = nextEntry->value;
//将新节点插入到链表头部(这样的好处是插入快,但是不能保证插入的顺序)
newEntry->next = newList[newIndex];
newList[newIndex] = newEntry;
}
nextEntry=nextEntry->next;
}
}
}
}
//释放旧的存储区域
free(hashMap->list);
//将新的存储区域赋值给旧的存储区域
hashMap->list=newList;
}void putHashMap(HashMap *hashMap, char *key, void *value) {
//判断是否需要扩容
if(hashMap->nodeLen==hashMap->capacity){
dilatationHash(hashMap);
}
//获取hash值
unsigned int hashCode = defaultHashCode(*hashMap, key);
//获取节点
Entry *entry = hashMap->list[hashCode];
//如果节点是空的那么直接添加
if(entry==NULL){
Entry *newEntry = (Entry *)malloc(sizeof(Entry));
newEntry->key = key;
newEntry->value = value;
newEntry->next = NULL;
hashMap->list[hashCode] = newEntry;
hashMap->size++;
hashMap->nodeLen++;
return;
}
//判断是否存在该键,并且一样的话,更新值
if(entry->key !=NULL && strcmp(entry->key,key)==0){
entry->value = value;
return;
}
// 当前节点不为空,而且key不一样,那么表示hash冲突了,需要添加到链表中
//添加前需要先判断链表中是否存在该键
while (entry != NULL) {
//如果存在该键,那么更新值
if (strcmp(entry->key, key) == 0) {
entry->value = value;
return;
}
entry = entry->next;
}
//如果链表中不存在,那么就创建新的链表节点
Entry *newEntry = (Entry *)malloc(sizeof(Entry));
newEntry->key = key;
newEntry->value = value;
//将新节点插入到链表头部(这样的好处是插入快,但是不能保证插入的顺序)
newEntry->next = hashMap->list[hashCode];
hashMap->list[hashCode] = newEntry;
hashMap->size++;
}
void printHashMap(HashMap *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Entry *entry = hashMap->list[i];
while (entry != NULL) {
printf("%s:%s\n", entry->key, entry->value);
entry = entry->next;
}
}
}
void *getHashMap(HashMap *hashMap, char *key) {
//获取hash值
unsigned int hashCode = defaultHashCode(*hashMap, key);
//获取节点
Entry *entry = hashMap->list[hashCode];
//如果节点是空的那么直接返回
if(entry==NULL){
return NULL;
}
//判断是否存在该键,并且一样的话,返回值
if(entry->key !=NULL && strcmp(entry->key,key)==0){
return entry->value;
}
// 当前节点不为空,而且key不一样,那么表示hash冲突了,需要查询链表
while (entry != NULL) {
//如果找到该键,那么返回值
if (strcmp(entry->key, key) == 0) {
return entry->value;
}
entry = entry->next;
}
return NULL;
}boolean containsKey(HashMap *hashMap, char *key) {
//获取hash值
unsigned int hashCode = defaultHashCode(*hashMap, key);
//获取节点
Entry *entry = hashMap->list[hashCode];
//如果节点是空的那么直接返回FALSE
if(entry==NULL){
return FALSE;
}
//判断是否存在该键,并且一样的话,返回TRUE
if(entry->key !=NULL && strcmp(entry->key,key)==0){
return TRUE;
}
// 当前节点不为空,而且key不一样,那么表示hash冲突了,需要查询链表
while (entry != NULL) {
//如果找到该键,那么返回TRUE
if (strcmp(entry->key, key) == 0) {
return TRUE;
}
entry = entry->next;
}
return FALSE;
}//判断值是否存在
boolean containsValue(HashMap *hashMap, void *value) {
for (int i = 0; i < hashMap->capacity; i++) {
Entry *entry = hashMap->list[i];//获取节点
while (entry != NULL) {
if (entry->value == value) {//如果找到该值,那么返回TRUE
return TRUE;
}
entry = entry->next;//否则查询节点链表内部
}
}
return FALSE;
}
void removeHashMap(HashMap *hashMap, char *key) {
//获取hash值
unsigned int hashCode = defaultHashCode(*hashMap, key);
//获取节点
Entry *entry = hashMap->list[hashCode];
//如果节点是空的那么直接返回
if(entry==NULL){
return;
}
//判断是否存在该键,并且一样的话,删除该节点
if(entry->key !=NULL && strcmp(entry->key,key)==0){
hashMap->list[hashCode] = entry->next;
free(entry);
hashMap->size--;
return;
}
// 当前节点不为空,而且key不一样,那么表示hash冲突了,需要查询链表
while (entry != NULL) {
//如果找到该键,那么删除该节点
if (strcmp(entry->key, key) == 0) {
Entry *next = entry->next;
entry->next = next->next;
free(next);
hashMap->size--;
return;
}
entry = entry->next;
}
}void updateHashMap(HashMap *hashMap, char *key, void *value) {
//获取hash值
unsigned int hashCode = defaultHashCode(*hashMap, key);
//获取节点
Entry *entry = hashMap->list[hashCode];
//如果节点是空的那么直接返回
if(entry==NULL){
return;
}
//判断是否存在该键,并且一样的话,修改该节点的值
if(entry->key !=NULL && strcmp(entry->key,key)==0){
entry->value = value;
return;
}
// 当前节点不为空,而且key不一样,那么表示hash冲突了,需要查询链表
while (entry != NULL) {
//如果找到该键,那么修改该节点的值
if (strcmp(entry->key, key) == 0) {
entry->value = value;
return;
}
entry = entry->next;
}
}HashMapIterator *createHashMapIterator(HashMap *hashMap){
HashMapIterator *hashMapIterator= malloc(sizeof(HashMapIterator));;
hashMapIterator->hashMap = hashMap;
hashMapIterator->count= 0;//迭代次数
hashMapIterator->index= 0;//迭代位置
hashMapIterator->nextEntry= NULL;//下次迭代节点
return hashMapIterator;
}
boolean hasNextHashMapIterator(HashMapIterator *iterator){
return iterator->count < iterator->hashMap->size ? TRUE : FALSE;
}
Entry *nextHashMapIterator(HashMapIterator *iterator) {
if (hasNextHashMapIterator(iterator)) {
//如果节点中存在hash冲突链表那么就迭代链表
if(iterator->nextEntry!=NULL){//如果下次迭代节点不为空,那么直接返回下次迭代节点
Entry *entry = iterator->nextEntry;
iterator->nextEntry = entry->next;
iterator->count++;
return entry;
}
Entry *pEntry1 = iterator->hashMap->list[iterator->index];
//找到不是空的节点
while (pEntry1==NULL){
pEntry1 = iterator->hashMap->list[++iterator->index];
}
//如果没有hash冲突节点,那么下次迭代节点在当前节点向后继续搜索
if(pEntry1->next==NULL){
Entry *pEntry2= iterator->hashMap->list[++iterator->index];
while (pEntry2==NULL){
pEntry2 = iterator->hashMap->list[++iterator->index];
}
iterator->nextEntry =pEntry2;
}else{
iterator->nextEntry = pEntry1->next;
}
iterator->count++;
return pEntry1;
}
return NULL;
}需要借助我之前文件写的List集合,有兴趣的可以去看看
//获取所有的key ,返回一个自定义的List集合
CharList *geTKEys(HashMap *hashMap){
CharList *pCharlist = createCharList(10);
HashMapIterator *pIterator = createHashMapIterator(hashMap);
while (hasNextHashMapIterator(pIterator)) {
Entry *entry = nextHashMapIterator(pIterator);
addCharList(&pCharlist,entry->key);
}
return pCharlist;
}
//获取所有的value,返回一个自定义的List集合
CharList *getValues(HashMap *hashMap){
CharList *pCharlist = createCharList(10);
HashMapIterator *pIterator = createHashMapIterator(hashMap);
while (hasNextHashMapIterator(pIterator)) {
Entry *entry = nextHashMapIterator(pIterator);
addCharList(&pCharlist,entry->value);
}
return pCharlist;
}
HashMap *copyHashMap(HashMap *hashMap){
HashMap *pHashMap = createHashMap(hashMap->capacity);
HashMapIterator *pIterator = createHashMapIterator(hashMap);
while (hasNextHashMapIterator(pIterator)) {
Entry *entry = nextHashMapIterator(pIterator);
putHashMap(pHashMap,entry->key,entry->value);
}
return pHashMap;
}
//将一个map集合,合并到另一个map集合里 hashMap2合并到hashMap1
void mergeHashMap(HashMap *hashMap1,HashMap *hashMap2){
HashMapIterator *pIterator = createHashMapIterator(hashMap2);
while (hasNextHashMapIterator(pIterator)) {
Entry *entry = nextHashMapIterator(pIterator);
putHashMap(hashMap1,entry->key,entry->value);
}
}
HashMap *mergeHashMapNewMap(HashMap *hashMap1,HashMap *hashMap2){
HashMap *pHashMap = createHashMap(hashMap1->capacity+hashMap2->capacity);
HashMapIterator *pIterator1 = createHashMapIterator(hashMap1);
while (hasNextHashMapIterator(pIterator1)) {
Entry *entry = nextHashMapIterator(pIterator1);
putHashMap(pHashMap,entry->key,entry->value);
}
HashMapIterator *pIterator2 = createHashMapIterator(hashMap2);
while (hasNextHashMapIterator(pIterator2)) {
Entry *entry = nextHashMapIterator(pIterator2);
putHashMap(pHashMap,entry->key,entry->value);
}
return pHashMap;
}
//差集,返回一个新的Map集合,返回hashMap2的差集
HashMap *differenceHashMap(HashMap *hashMap1,HashMap *hashMap2){
HashMap *pHashMap = createHashMap(hashMap1->capacity);
HashMapIterator *pIterator1 = createHashMapIterator(hashMap1);
while (hasNextHashMapIterator(pIterator1)) {
Entry *entry = nextHashMapIterator(pIterator1);
if(!containsKey(hashMap2,entry->key)){
putHashMap(pHashMap,entry->key,entry->value);
}
}
return pHashMap;
}
//交集,返回一个新的Map集合
HashMap *intersectionHashMap(HashMap *hashMap1,HashMap *hashMap2){
HashMap *pHashMap = createHashMap(hashMap1->capacity);
HashMapIterator *pIterator1 = createHashMapIterator(hashMap1);
while (hasNextHashMapIterator(pIterator1)) {
Entry *entry = nextHashMapIterator(pIterator1);
if(containsKey(hashMap2,entry->key)){
putHashMap(pHashMap,entry->key,entry->value);
}
}
return pHashMap;
}
//补集,返回一个新的Map集合
HashMap *complementHashMap(HashMap *hashMap1,HashMap *hashMap2){
HashMap *pHashMap = createHashMap(hashMap1->capacity);
HashMapIterator *pIterator1 = createHashMapIterator(hashMap1);
while (hasNextHashMapIterator(pIterator1)) {
Entry *entry = nextHashMapIterator(pIterator1);
if(!containsKey(hashMap2,entry->key)){
putHashMap(pHashMap,entry->key,entry->value);
}
}
HashMapIterator *pIterator2 = createHashMapIterator(hashMap2);
while (hasNextHashMapIterator(pIterator2)) {
Entry *entry = nextHashMapIterator(pIterator2);
if(!containsKey(hashMap1,entry->key)){
putHashMap(pHashMap,entry->key,entry->value);
}
}
return pHashMap;
}HashMap *uNIOnHashMap(HashMap *hashMap1,HashMap *hashMap2){
HashMap *pHashMap = createHashMap(hashMap1->capacity+hashMap2->capacity);
HashMapIterator *pIterator1 = createHashMapIterator(hashMap1);
while (hasNextHashMapIterator(pIterator1)) {
Entry *entry = nextHashMapIterator(pIterator1);
putHashMap(pHashMap,entry->key,entry->value);
}
HashMapIterator *pIterator2 = createHashMapIterator(hashMap2);
while (hasNextHashMapIterator(pIterator2)) {
Entry *entry = nextHashMapIterator(pIterator2);
putHashMap(pHashMap,entry->key,entry->value);
}
return pHashMap;
}
void hashMapClear(HashMap *hashMap){
for (int i = 0; i < hashMap->nodeLen; i++) {
// 释放冲突值内存
Entry *entry = hashMap->list[i];
if(entry!=NULL){
Entry *nextEntry = entry->next;
while (nextEntry != NULL) {
Entry *next = nextEntry->next;
free(nextEntry);
nextEntry = next;
}
free(entry);
}
}
// 释放存储空间
free(hashMap->list);
free(hashMap);
}到此这篇关于C语言实现手写Map(全功能)的示例代码的文章就介绍到这了,更多相关C语言 Map内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: C语言实现手写Map(全功能)的示例代码
本文链接: https://www.lsjlt.com/news/166009.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0