本篇内容主要讲解“SpringBoot如何通过lucene实现全文检索”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“springboot如何通过lucene实现全文检索”吧!Lucene提供了一
本篇内容主要讲解“SpringBoot如何通过lucene实现全文检索”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“springboot如何通过lucene实现全文检索”吧!
Lucene提供了一个简单却强大的应用程序接口(api),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具。
Lucene全文检索就是对文档中全部内容进行分词,然后对所有单词建立倒排索引的过程。主要操作是使用Lucene的API来实现对索引的增(创建索引)、删(删除索引)、改(修改索引)、查(搜索数据)。
假设我们的电脑的目录中含有很多文本文档,我们需要查找哪些文档含有某个关键词。为了实现这种功能,我们首先利用 Lucene 对这个目录中的文档建立索引,然后在建立好的索引中搜索我们所要查找的文档。通过这个例子读者会对如何利用 Lucene 构建自己的搜索应用程序有个比较清楚的认识。
Document
Document 是用来描述文档的,这里的文档可以指一个 html 页面,一封电子邮件,或者是一个文本文件。一个 Document 对象由多个 Field 对象组成,可以把一个 Document 对象想象成数据库中的一个记录,而每个 Field 对象就是记录的一个字段。
Field
Field 对象是用来描述一个文档的某个属性的,比如一封电子邮件的标题和内容可以用两个 Field 对象分别描述。
Analyzer
在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由 Analyzer 来做的。Analyzer 类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的 Analyzer。Analyzer 把分词后的内容交给 IndexWriter 来建立索引。
IndexWriter
IndexWriter 是 Lucene 用来创建索引的一个核心的类,他的作用是把一个个的 Document 对象加到索引中来。
Directory
这个类代表了 Lucene 的索引的存储的位置,这是一个抽象类,它目前有两个实现,第一个是 FSDirectory,它表示一个存储在文件系统中的索引的位置。第二个是 RAMDirectory,它表示一个存储在内存当中的索引的位置。
Query
这是一个抽象类,他有多个实现,比如 TerMQuery, BooleanQuery, PrefixQuery. 这个类的目的是把用户输入的查询字符串封装成 Lucene 能够识别的 Query。
Term
Term 是搜索的基本单位,一个 Term 对象有两个 String 类型的域组成。生成一个 Term 对象可以有如下一条语句来完成:Term term = new Term(“fieldName”,”queryWord”); 其中第一个参数代表了要在文档的哪一个 Field 上进行查找,第二个参数代表了要查询的关键词。
TermQuery
TermQuery 是抽象类 Query 的一个子类,它同时也是 Lucene 支持的最为基本的一个查询类。生成一个 TermQuery 对象由如下语句完成: TermQuery termQuery = new TermQuery(new Term(“fieldName”,”queryWord”)); 它的构造函数只接受一个参数,那就是一个 Term 对象。
IndexSearcher
IndexSearcher 是用来在建立好的索引上进行搜索的。它只能以只读的方式打开一个索引,所以可以有多个 IndexSearcher 的实例在一个索引上进行操作。
Hits
Hits 是用来保存搜索的结果的。
实例
pom依赖
<!-- lucene核心库 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>7.6.0</version> </dependency> <!-- Lucene的查询解析器 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>7.6.0</version> </dependency> <!-- lucene的默认分词器库,适用于英文分词 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>7.6.0</version> </dependency> <!-- lucene的高亮显示 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>7.6.0</version> </dependency> <!-- smartcn中文分词器 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-smartcn</artifactId> <version>7.6.0</version> </dependency> <!-- ik分词器 --> <dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> </dependency>自定义IK分词器
public class MyIKAnalyzer extends Analyzer { private boolean useSmart; public MyIKAnalyzer() { this(false); } public MyIKAnalyzer(boolean useSmart) { this.useSmart = useSmart; } @Override protected TokenStreamComponents createComponents(String s) { Tokenizer _MyIKTokenizer = new MyIKTokenizer(this.useSmart()); return new TokenStreamComponents(_MyIKTokenizer); } public boolean useSmart() { return this.useSmart; } public void setUseSmart(boolean useSmart) { this.useSmart = useSmart; }}public class MyIKTokenizer extends Tokenizer { private IKSegmenter _IKImplement; private final CharTermAttribute termAtt = (CharTermAttribute)this.addAttribute(CharTermAttribute.class); private final OffsetAttribute offsetAtt = (OffsetAttribute)this.addAttribute(OffsetAttribute.class); private final TypeAttribute typeAtt = (TypeAttribute)this.addAttribute(TypeAttribute.class); private int endPosition; //useSmart:设置是否使用智能分词。默认为false,使用细粒度分词,这里如果更改为TRUE,那么搜索到的结果可能就少的很多 public MyIKTokenizer(boolean useSmart) { this._IKImplement = new IKSegmenter(this.input, useSmart); } @Override public boolean incrementToken() throws IOException { this.clearAttributes(); Lexeme nextLexeme = this._IKImplement.next(); if (nextLexeme != null) { this.termAtt.append(nextLexeme.getLexemeText()); this.termAtt.setLength(nextLexeme.getLength()); this.offsetAtt.setOffset(nextLexeme.getBeginPosition(), nextLexeme.getEndPosition()); this.endPosition = nextLexeme.getEndPosition(); this.typeAtt.setType(nextLexeme.getLexemeTypeString()); return true; } else { return false; } } @Override public void reset() throws IOException { super.reset(); this._IKImplement.reset(this.input); } @Override public final void end() { int finalOffset = this.correctOffset(this.endPosition); this.offsetAtt.setOffset(finalOffset, finalOffset); }}测试1
@RequestMapping("/createIndex") public String createIndex() throws IOException { List<Content> list1 = new ArrayList<>(); list1.add(new Content(null, "Java面向对象", "10", null, "Java面向对象从入门到精通,简单上手")); list1.add(new Content(null, "Java面向对象java", "10", null, "Java面向对象从入门到精通,简单上手")); list1.add(new Content(null, "Java面向编程", "15", null, "Java面向对象编程书籍")); list1.add(new Content(null, "javascript入门", "18", null, "JavaScript入门编程书籍")); list1.add(new Content(null, "深入理解Java编程", "13", null, "十三四天掌握Java基础")); list1.add(new Content(null, "从入门到放弃_Java", "20", null, "一门从入门到放弃的书籍")); list1.add(new Content(null, "Head First Java", "30", null, "《Head First Java》是一本完整地面向对象(object-oriented,OO)程序设计和Java的学习指导用书")); list1.add(new Content(null, "Java 核心技术:卷1 基础知识", "22", null, "全书共14章,包括Java基本的程序结构、对象与类、继承、接口与内部类、图形程序设计、事件处理、Swing用户界面组件")); list1.add(new Content(null, "Java 编程思想", "12", null, "本书赢得了全球程序员的广泛赞誉,即使是最晦涩的概念,在Bruce Eckel的文字亲和力和小而直接的编程示例面前也会化解于无形")); list1.add(new Content(null, "Java开发实战经典", "51", null, "本书是一本综合讲解Java核心技术的书籍,在书中使用大量的代码及案例进行知识点的分析与运用")); list1.add(new Content(null, "Effective Java", "10", null, "本书介绍了在Java编程中57条极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案")); list1.add(new Content(null, "分布式 Java 应用:基础与实践", "14", null, "本书介绍了编写分布式Java应用涉及的众多知识点,分为了基于Java实现网络通信、rpc;基于SOA实现大型分布式Java应用")); list1.add(new Content(null, "Http权威指南", "11", null, "超文本传输协议(Hypertext Transfer Protocol,HTTP)是在万维网上进行通信时所使用的协议方案")); list1.add(new Content(null, "Spring", "15", null, "这是啥,还需要学习吗?Java程序员必备书籍")); list1.add(new Content(null, "深入理解 Java 虚拟机", "18", null, "作为一位Java程序员,你是否也曾经想深入理解Java虚拟机,但是却被它的复杂和深奥拒之门外")); list1.add(new Content(null, "springboot实战", "11", null, "完成对于springboot的理解,是每个Java程序员必备的姿势")); list1.add(new Content(null, "springMVC学习", "72", null, "springmvc学习指南")); list1.add(new Content(null, "Vue入门到放弃", "20", null, "vue入门到放弃书籍信息")); list1.add(new Content(null, "vue入门到精通", "20", null, "vue入门到精通相关书籍信息")); list1.add(new Content(null, "vue之旅", "20", null, "由浅入深地全面介绍vue技术,包含大量案例与代码")); list1.add(new Content(null, "vue实战", "20", null, "以实战为导向,系统讲解如何使用 ")); list1.add(new Content(null, "vue入门与实践", "20", null, "现已得到苹果、微软、谷歌等主流厂商全面支持")); list1.add(new Content(null, "vue.js应用测试", "20", null, "Vue.js创始人尤雨溪鼎力推荐!Vue官方测试工具作者亲笔撰写,Vue.js应用测试完全学习指南")); list1.add(new Content(null, "PHP和MySQL web开发", "20", null, "本书是利用php和Mysql构建数据库驱动的WEB应用程序的权威指南")); list1.add(new Content(null, "Web高效编程与优化实践", "20", null, "从思想提升和内容修炼两个维度,围绕前端工程师必备的前端技术和编程基础")); list1.add(new Content(null, "Vue.js 2.x实践指南", "20", null, "本书旨在让初学者能够快速上手vue技术栈,并能够利用所学知识独立动手进行项目开发")); list1.add(new Content(null, "初始vue", "20", null, "解开vue的面纱")); list1.add(new Content(null, "什么是vue", "20", null, "一步一步的了解vue相关信息")); list1.add(new Content(null, "深入浅出vue", "20", null, "深入浅出vue,慢慢掌握")); list1.add(new Content(null, "三天vue实战", "20", null, "三天掌握vue开发")); list1.add(new Content(null, "不知火舞", "20", null, "不知名的vue")); list1.add(new Content(null, "娜可露露", "20", null, "一招秒人")); list1.add(new Content(null, "宫本武藏", "20", null, "我就是一个超级兵")); list1.add(new Content(null, "vue宫本vue", "20", null, "我就是一个超级兵")); // 创建文档的集合 Collection<Document> docs = new ArrayList<>(); for (int i = 0; i < list1.size(); i++) { //contentMapper.insertSelective(list1.get(i)); // 创建文档对象 Document document = new Document(); //StringField会创建索引,但是不会被分词,TextField,即创建索引又会被分词。 document.add(new StringField("id", (i + 1) + "", Field.Store.YES)); document.add(new TextField("title", list1.get(i).getTitle(), Field.Store.YES)); document.add(new TextField("price", list1.get(i).getPrice(), Field.Store.YES)); document.add(new TextField("descs", list1.get(i).getDescs(), Field.Store.YES)); docs.add(document); } // 索引目录类,指定索引在硬盘中的位置,我的设置为D盘的indexDir文件夹 Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lucene\\indexDir")); // 引入IK分词器 Analyzer analyzer = new MyIKAnalyzer(); // 索引写出工具的配置对象,这个地方就是最上面报错的问题解决方案 IndexWriterConfig conf = new IndexWriterConfig(analyzer); // 设置打开方式:OpenMode.APPEND 会在索引库的基础上追加新索引。OpenMode.CREATE会先清空原来数据,再提交新的索引 conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE); // 创建索引的写出工具类。参数:索引的目录和配置信息 IndexWriter indexWriter = new IndexWriter(directory, conf); // 把文档集合交给IndexWriter indexWriter.aDDDocuments(docs); // 提交 indexWriter.commit(); // 关闭 indexWriter.close(); return "success"; } @RequestMapping("/updateIndex") public String update(String age) throws IOException { // 创建目录对象 Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lucene\\indexDir")); // 创建配置对象 IndexWriterConfig conf = new IndexWriterConfig(new MyIKAnalyzer()); // 创建索引写出工具 IndexWriter writer = new IndexWriter(directory, conf); // 创建新的文档数据 Document doc = new Document(); doc.add(new StringField("id", "34", Field.Store.YES)); //Content content = contentMapper.selectByPrimaryKey("34"); //content.setTitle("宫本武藏超级兵"); //contentMapper.updateByPrimaryKeySelective(content); Content content = new Content(34, "宫本武藏超级兵", "", "", ""); doc.add(new TextField("title", content.getTitle(), Field.Store.YES)); doc.add(new TextField("price", content.getPrice(), Field.Store.YES)); doc.add(new TextField("descs", content.getDescs(), Field.Store.YES)); writer.updateDocument(new Term("id", "34"), doc); // 提交 writer.commit(); // 关闭 writer.close(); return "success"; } @RequestMapping("/deleteIndex") public String deleteIndex() throws IOException { // 创建目录对象 Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lucene\\indexDir")); // 创建配置对象 IndexWriterConfig conf = new IndexWriterConfig(new IKAnalyzer()); // 创建索引写出工具 IndexWriter writer = new IndexWriter(directory, conf); // 根据词条进行删除 writer.deleteDocuments(new Term("id", "34")); // 提交 writer.commit(); // 关闭 writer.close(); return "success"; } @RequestMapping("/searchText") public Object searchText(String text, httpservletRequest request) throws IOException, ParseException { Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lucene\\indexDir")); // 索引读取工具 IndexReader reader = DirectoryReader.open(directory); // 索引搜索工具 IndexSearcher searcher = new IndexSearcher(reader); // 创建查询解析器,两个参数:默认要查询的字段的名称,分词器 QueryParser parser = new QueryParser("descs", new MyIKAnalyzer()); // 创建查询对象 Query query = parser.parse(text); // 获取前十条记录 TopDocs topDocs = searcher.search(query, 10); // 获取总条数 System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据"); // 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分 ScoreDoc[] scoreDocs = topDocs.scoreDocs; List<Content> list = new ArrayList<>(); for (ScoreDoc scoreDoc : scoreDocs) { // 取出文档编号 int docID = scoreDoc.doc; // 根据编号去找文档 Document doc = reader.document(docID); //Content content = contentMapper.selectByPrimaryKey(doc.get("id")); Content content = new Content(); content.setId(Integer.valueOf(doc.get("id"))); content.setTitle(doc.get("title")); content.setDescs(doc.get("descs")); list.add(content); } return list; } @RequestMapping("/searchText1") public Object searchText1(String text, HttpServletRequest request) throws IOException, ParseException { String[] str = {"title", "descs"}; Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir")); // 索引读取工具 IndexReader reader = DirectoryReader.open(directory); // 索引搜索工具 IndexSearcher searcher = new IndexSearcher(reader); // 创建查询解析器,两个参数:默认要查询的字段的名称,分词器 MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer()); // 创建查询对象 Query query = parser.parse(text); // 获取前十条记录 TopDocs topDocs = searcher.search(query, 100); // 获取总条数 System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据"); // 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分 ScoreDoc[] scoreDocs = topDocs.scoreDocs; List<Content> list = new ArrayList<>(); for (ScoreDoc scoreDoc : scoreDocs) { // 取出文档编号 int docID = scoreDoc.doc; // 根据编号去找文档 Document doc = reader.document(docID); //Content content = contentMapper.selectByPrimaryKey(doc.get("id")); Content content = new Content(); content.setId(Integer.valueOf(doc.get("id"))); list.add(content); } return list; } @RequestMapping("/searchText2") public Object searchText2(String text, HttpServletRequest request) throws IOException, ParseException, InvalidTokenOffsetsException { String[] str = {"title", "descs"}; Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir")); // 索引读取工具 IndexReader reader = DirectoryReader.open(directory); // 索引搜索工具 IndexSearcher searcher = new IndexSearcher(reader); // 创建查询解析器,两个参数:默认要查询的字段的名称,分词器 MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer()); // 创建查询对象 Query query = parser.parse(text); // 获取前十条记录 TopDocs topDocs = searcher.search(query, 100); // 获取总条数 System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据"); //高亮显示 SimpleHTMLFORMatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>"); Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query)); Fragmenter fragmenter = new SimpleFragmenter(100); //高亮后的段落范围在100字内 highlighter.setTextFragmenter(fragmenter); // 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分 ScoreDoc[] scoreDocs = topDocs.scoreDocs; List<Content> list = new ArrayList<>(); for (ScoreDoc scoreDoc : scoreDocs) { // 取出文档编号 int docID = scoreDoc.doc; // 根据编号去找文档 Document doc = reader.document(docID); //Content content = contentMapper.selectByPrimaryKey(doc.get("id")); Content content = new Content(); //处理高亮字段显示 String title = highlighter.getBestFragment(new MyIKAnalyzer(), "title", doc.get("title")); if (title == null) { title = content.getTitle(); } String descs = highlighter.getBestFragment(new MyIKAnalyzer(), "descs", doc.get("descs")); if (descs == null) { descs = content.getDescs(); } content.setDescs(descs); content.setTitle(title); list.add(content); } request.setAttribute("list", list); return "index"; } @RequestMapping("/searchText3") public String searchText3(String text, HttpServletRequest request) throws IOException, ParseException, InvalidTokenOffsetsException { String[] str = {"title", "descs"}; int page = 1; int pageSize = 10; Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir")); // 索引读取工具 IndexReader reader = DirectoryReader.open(directory); // 索引搜索工具 IndexSearcher searcher = new IndexSearcher(reader); // 创建查询解析器,两个参数:默认要查询的字段的名称,分词器 MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer()); // 创建查询对象 Query query = parser.parse(text); // 获取前十条记录 //TopDocs topDocs = searcher.search(query, 100); TopDocs topDocs = searchByPage(page, pageSize, searcher, query); // 获取总条数 System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据"); //高亮显示 SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>"); Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query)); Fragmenter fragmenter = new SimpleFragmenter(100); //高亮后的段落范围在100字内 highlighter.setTextFragmenter(fragmenter); // 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分 ScoreDoc[] scoreDocs = topDocs.scoreDocs; List<Content> list = new ArrayList<>(); for (ScoreDoc scoreDoc : scoreDocs) { // 取出文档编号 int docID = scoreDoc.doc; // 根据编号去找文档 Document doc = reader.document(docID); //Content content = contentMapper.selectByPrimaryKey(doc.get("id")); Content content = new Content(); //处理高亮字段显示 String title = highlighter.getBestFragment(new MyIKAnalyzer(), "title", doc.get("title")); if (title == null) { title = content.getTitle(); } String descs = highlighter.getBestFragment(new MyIKAnalyzer(), "descs", doc.get("descs")); if (descs == null) { descs = content.getDescs(); } content.setDescs(descs); content.setTitle(title); list.add(content); } System.err.println("list的长度:" + list.size()); request.setAttribute("page", page); request.setAttribute("pageSize", pageSize); request.setAttribute("list", list); return "index"; } private TopDocs searchByPage(int page, int perPage, IndexSearcher searcher, Query query) throws IOException { TopDocs result = null; if (query == null) { System.out.println(" Query is null return null "); return null; } ScoreDoc before = null; if (page != 1) { TopDocs docsBefore = searcher.search(query, (page - 1) * perPage); ScoreDoc[] scoreDocs = docsBefore.scoreDocs; if (scoreDocs.length > 0) { before = scoreDocs[scoreDocs.length - 1]; } } result = searcher.searchAfter(before, query, perPage); return result; } @RequestMapping("/searchText4") public String searchText4(String text, HttpServletRequest request) throws IOException, ParseException, InvalidTokenOffsetsException { String[] str = {"title", "descs"}; int page = 1; int pageSize = 100; IndexSearcher searcher = getMoreSearch("d:\\indexDir"); // 创建查询解析器,两个参数:默认要查询的字段的名称,分词器 MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer()); // 创建查询对象 Query query = parser.parse(text); TopDocs topDocs = searchByPage(page, pageSize, searcher, query); // 获取总条数 System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据"); //高亮显示 SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>"); Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query)); Fragmenter fragmenter = new SimpleFragmenter(100); //高亮后的段落范围在100字内 highlighter.setTextFragmenter(fragmenter); // 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分 ScoreDoc[] scoreDocs = topDocs.scoreDocs; List<Content> list = new ArrayList<>(); for (ScoreDoc scoreDoc : scoreDocs) { // 取出文档编号 int docID = scoreDoc.doc; // 根据编号去找文档 //Document doc = reader.document(docID); Document doc = searcher.doc(docID);//多索引找文档要用searcher找了,reader容易报错 //Content content = contentMapper.selectByPrimaryKey(doc.get("id")); Content content = new Content(); //处理高亮字段显示 String title = highlighter.getBestFragment(new MyIKAnalyzer(), "title", doc.get("title")); if (title == null) { title = content.getTitle(); } String descs = highlighter.getBestFragment(new MyIKAnalyzer(), "descs", doc.get("descs")); if (descs == null) { descs = content.getDescs(); } content.setDescs(descs); content.setTitle(title); list.add(content); } System.err.println("list的长度:" + list.size()); request.setAttribute("page", page); request.setAttribute("pageSize", pageSize); request.setAttribute("list", list); return "index"; } private IndexSearcher getMoreSearch(String string) { MultiReader reader = null; //设置 try { File[] files = new File(string).listFiles(); IndexReader[] readers = new IndexReader[files.length]; for (int i = 0; i < files.length; i++) { readers[i] = DirectoryReader.open(FSDirectory.open(Paths.get(files[i].getPath(), new String[0]))); } reader = new MultiReader(readers); } catch (IOException e) { e.printStackTrace(); } return new IndexSearcher(reader); //如果索引文件过多,可以这样加快效率 }测试2
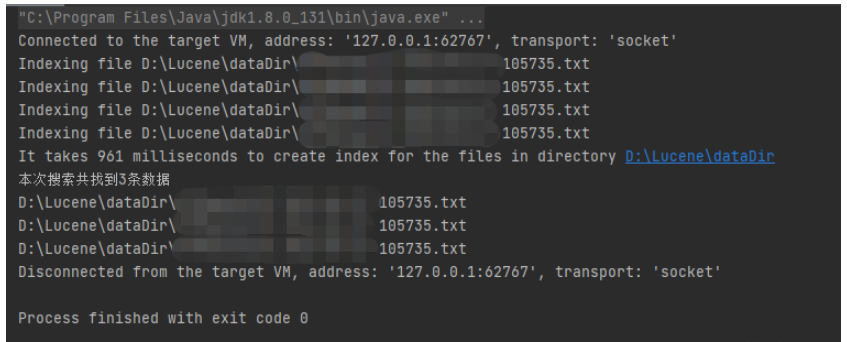
public static void main(String[] args) throws IOException, ParseException { long startTime = System.currentTimeMillis(); // indexDir is the directory that hosts Lucene's index files File indexDir = new File("D:\\Lucene\\indexDir"); // dataDir is the directory that hosts the text files that to be indexed File dataDir = new File("D:\\Lucene\\dataDir"); Analyzer luceneAnalyzer = new StandardAnalyzer(); // 或引入IK分词器 Analyzer IkAnalyzer = new MyIKAnalyzer(); Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lucene\\indexDir")); IndexWriterConfig indexWriterConfig = new IndexWriterConfig(IkAnalyzer); // 设置打开方式:OpenMode.APPEND 会在索引库的基础上追加新索引、OpenMode.CREATE会先清空原来数据,再提交新的索引 indexWriterConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE); IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig); File[] dataFiles = dataDir.listFiles(); for (int i = 0; i < dataFiles.length; i++) { if (dataFiles[i].isFile() && dataFiles[i].getName().endsWith(".txt")) { System.out.println("Indexing file " + dataFiles[i].getCanonicalPath()); Document document = new Document(); Reader txtReader = new FileReader(dataFiles[i]); document.add(new TextField("path", dataFiles[i].getCanonicalPath(), Field.Store.YES)); document.add(new TextField("contents", txtReader)); indexWriter.addDocument(document); } } indexWriter.commit(); indexWriter.close(); long endTime = System.currentTimeMillis(); System.out.println("It takes " + (endTime - startTime) + " milliseconds to create index for the files in directory " + dataDir.getPath()); String queryStr = "hello"; // 索引读取工具 IndexReader indexReader = DirectoryReader.open(directory); // 索引搜索工具 IndexSearcher indexSearcher = new IndexSearcher(indexReader); // 创建查询解析器,两个参数:默认要查询的字段的名称,分词器 QueryParser parser = new QueryParser("contents", IkAnalyzer); // 创建查询对象 Query query = parser.parse(queryStr); // 获取前十条记录 TopDocs topDocs = indexSearcher.search(query, 10); // 获取总条数 System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据"); // 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分 ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { // 取出文档编号 int docID = scoreDoc.doc; // 根据编号去找文档 Document doc = indexReader.document(docID); System.out.println(doc.get("path")); } }IndexWriter对象将dataDir下的所有txt文件建立索引,指定索引文件的目录为indexDir,Document对象对应一个带搜索的文件,可以是文本文件也可以是一个网页,为Document对象指定field,这里为文本文件定义了两个field:path和contents,运行完第一部分代码后,则在指定目录下生成了索引文件,如下

IndexReader对象读取索引文件,通过QueryParser对象指定语法分析器和对document的那个字段进行查询,Query对象则制定了搜索的关键字,通过IndexSearcher对象实现检索,并返回结果集TopDocs,运行完第二部分代码后,会看到打印包含关键字的文本文件的路径,如下
到此,相信大家对“Springboot如何通过lucene实现全文检索”有了更深的了解,不妨来实际操作一番吧!这里是编程网网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
--结束END--
本文标题: Springboot如何通过lucene实现全文检索
本文链接: https://www.lsjlt.com/news/340626.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0