Python 官方文档:入门教程 => 点击学习
网络爬虫—mongoDB详讲与实战 MongoDBMongoDB安装创建数据目录1.数据库操作2.集合操作3.文档操作4.索引操作5.聚合操作6.备份与恢复 MongoDB增删改查mong
前言:
3D8;️🏘️个人简介:以山河作礼。
🎖️🎖️:python领域新星创作者,CSDN实力新星认证
📝📝第一篇文章《1.认识网络爬虫》获得全站热榜第一,Python领域热榜第一。
🧾 🧾第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
🧾 🧾第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
🎁🎁《Python网络爬虫》专栏累计发表九篇文章,上榜三篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
MongoDB是一种开源的文档型数据库管理系统,采用分布式文件存储方式,可以存储非结构化的数据,如文档和键值对等。
它的特点是高性能、高可扩展性、高可用性和易于使用,可以支持复杂的查询和数据分析,同时还提供了数据复制、故障转移和自动分片等功能,可以应用于多种场景,如WEB应用、大数据、物联网等。
MongoDB使用BSON(Binary JSON)格式来存储数据,支持多种编程语言的驱动程序,如Java、Python、Ruby、PHP等。
MongoDB 提供了可用于 32 位和 64 位系统的预编译二进制包,你可以从MongoDB官网下载安装,MongoDB 预编译二进制包下载地址: MongoDB
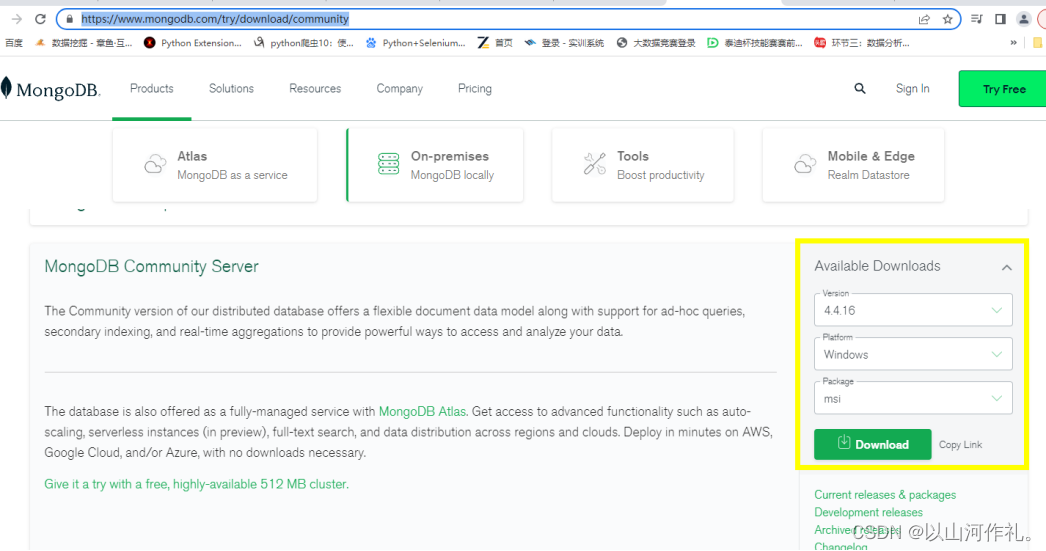
下载 .msi 文件,下载后双击该文件,按操作提示安装即可。
安装过程中,你可以通过点击 “Custom(自定义)” 按钮来设置你的安装目录。
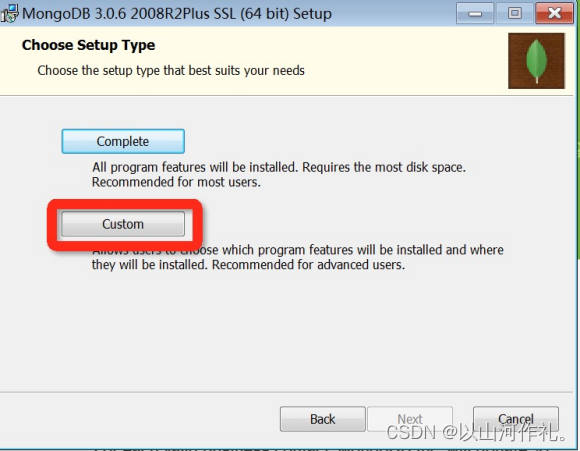
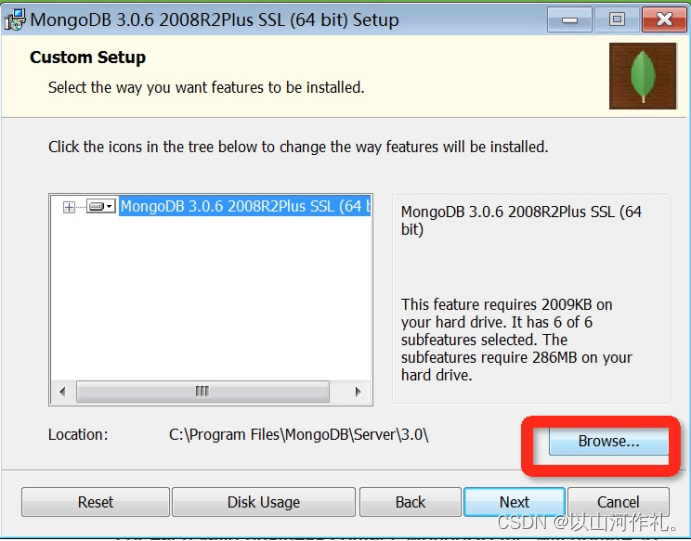

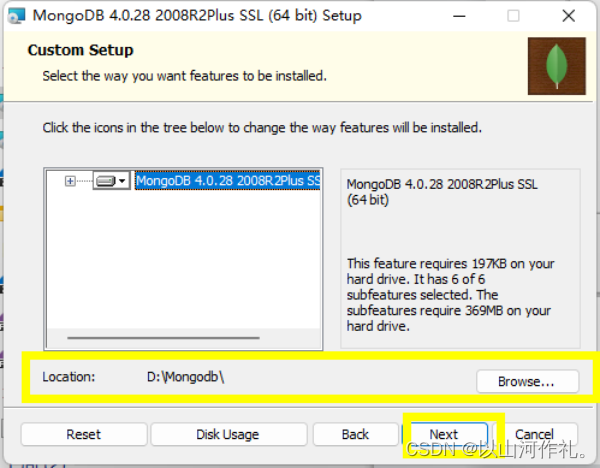
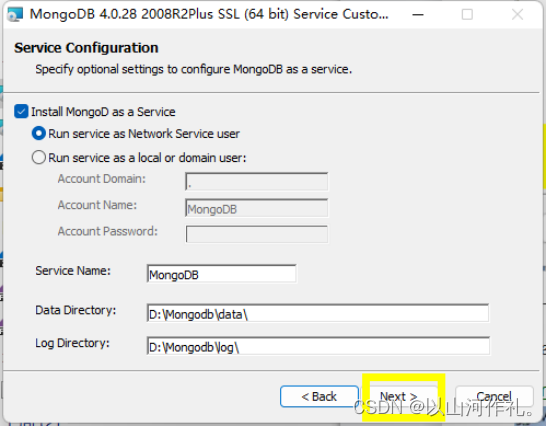
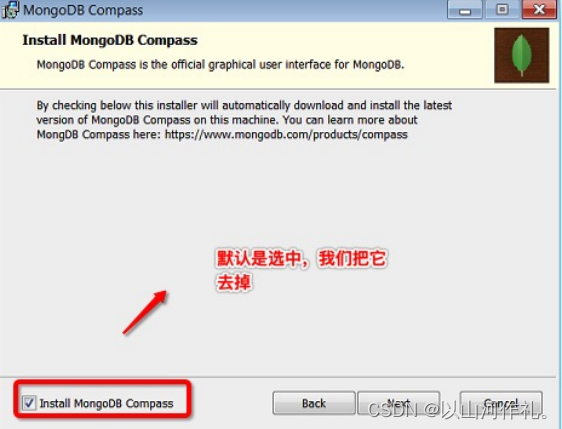
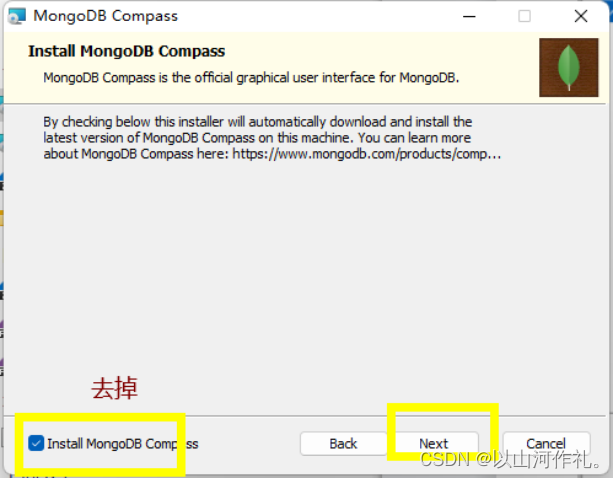
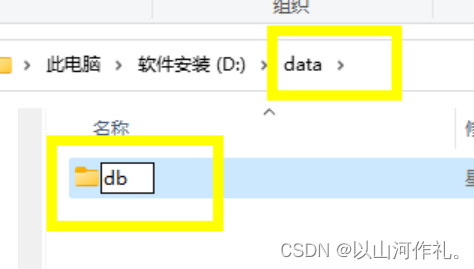
=MongoDB 将数据目录存储在 db 目录下。但是这个数据目录不会主动创建,我们在安装完成后需要创建它。请注意,数据目录应该放在根目录下 (如: C:\ 或者 D:\ 等 )。
比如我这里安装在了D盘,那就在D盘创建一个data文件夹,进入文件夹创建db文件夹。
命令行下运行 MongoDB 服务器
为了从命令提示符下运行 MongoDB 服务器,你必须从 MongoDB 目录的 bin 目录中执行 mongod.exe 文件。
D:\Mongodb\bin\mongod --dbpath D:\data\db如果执行成功,会输出如下信息:
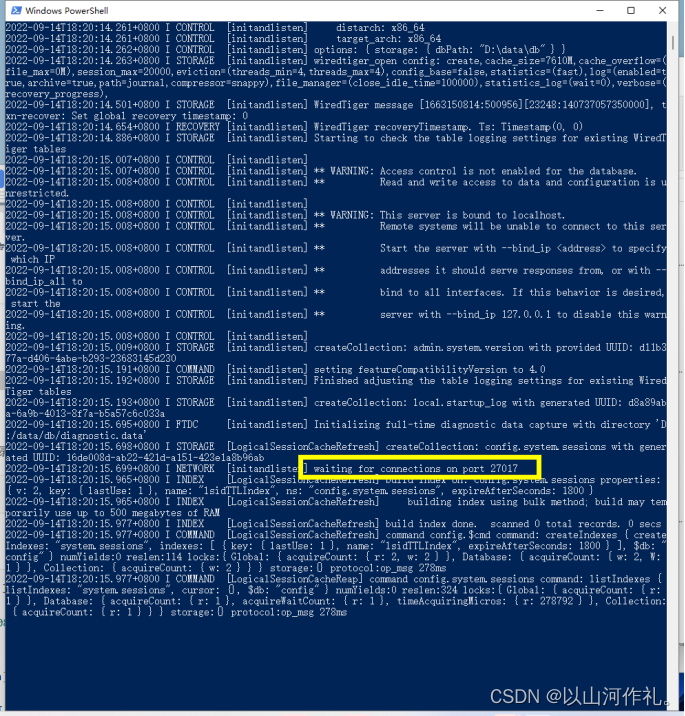
有27017就代表成功!!!
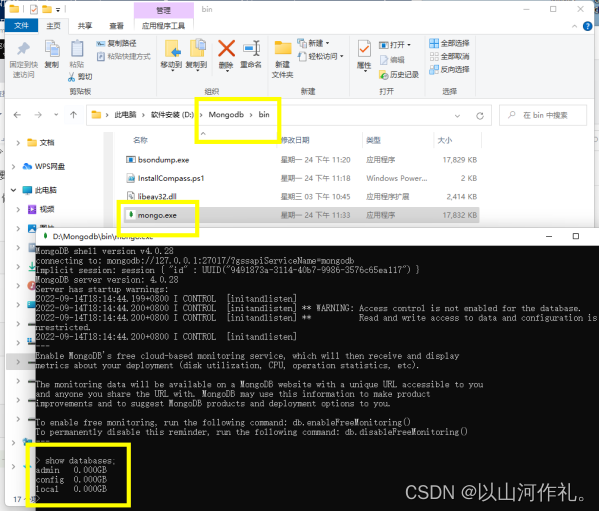
连接mongodb 有就说明成功了
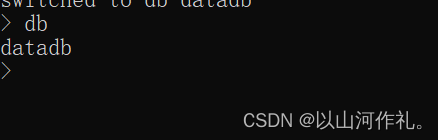
use datadb
查看当前数据库:db
查看所有数据库:show dbs

db.dropDatabase()创建集合:db.createCollection("

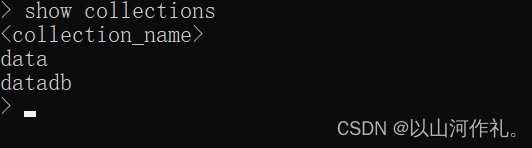
查看集合show collections
删除集合:db.
db..insert() db..find(, ) db..update(, , ) db..remove(, ) db..createIndex(, ) db..getIndexes() db..dropIndex() db..aggregate() 使用db.
.aggregate()方法对指定集合中的文档进行聚合操作。其中,pipeline参数是一个数组,包含了一系列聚合操作的步骤。每个步骤都是一个文档,包含了一个操作符和对应的参数。
聚合操作的步骤可以包括以下几种:
$match:筛选符合条件的文档;
$group:按照指定的字段进行分组,可以对每个组进行计算;
$sort:对文档进行排序;
$limit:限制返回的文档数量;
$project:指定返回的文档中包含哪些字段,可以对字段进行修改或计算;
$unwind:将数组类型的字段展开成多个文档。
聚合操作可以根据实际需求进行组合,以实现复杂的数据处理任务。
mongodump -d -o mongorestore -d 插入演示
db.
插入实例
db.book.insert({'name':'小明','age':20,'gender':'男'})
其中,‘name’、'age’和’gender’是文档的字段名,‘小明’、20和’男’是对应的字段值。通过这个操作,我们成功向book集合中插入了一条文档。
输出演示
db.
普通输出,获取所有数据
db.book.find()
美化输出
db.book.find().pretty()
删除数据
db.
删除实例
db.book.remove({'name':'小明'})
只对一条满足要求的数据进行操作
db.col.update({'title':'MongoDB data''},{$set:{'title':'MongoDB'}})
db.book.update({'name':'小明'},{$set:{'age':18}})
对所有满足要求的数据进行操作
db.col.update({'title':'MongoDB data''},{$set:{'title':'MongoDB'}},{multi:true})
db.book.update({'name':'小明'},{$set:{'age':22}},{multi:true})
在终端输入代码安装:
pip install pymongo
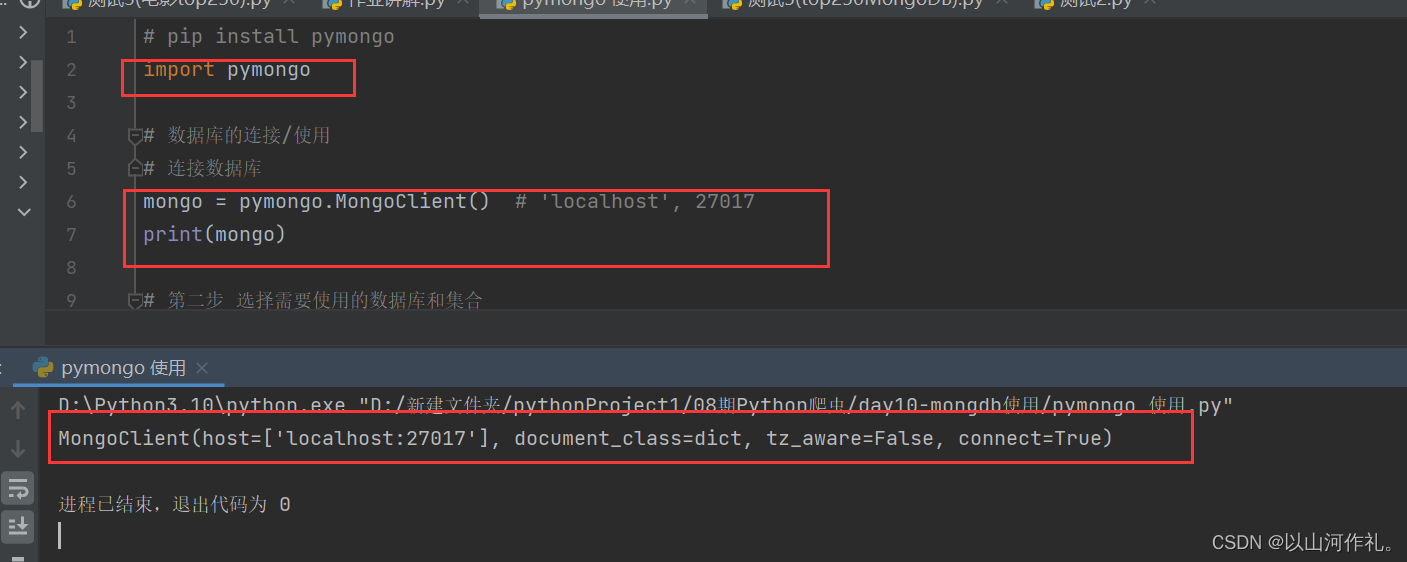
mongo = pymongo.MongoClient() # 'localhost', 27017mongo = pymongo.MongoClient() 这行代码中,mongo是一个MongoDB客户端对象,可以用来连接MongoDB数据库,执行数据库操作等。如果MongoDB服务运行在其他主机上,可以通过传递参数来指定主机名和端口号,如:
mongo = pymongo.MongoClient('mongodb://:' )其中,为MongoDB服务所在主机的IP地址或者主机名,为MongoDB服务所监听的端口号。
选择数据库
# 选择数据库db = mongo.test# print(db)使用 mongo 连接MongoDB数据库中的 test 数据库,返回一个 test 数据库对象,用于执行数据库操作。如果 test
数据库不存在,则会在MongoDB中创建一个名为 test 的数据库。
选择集合
col = db.book # 选择集合# print(col)在 test 数据库中选择了一个名为 book 的集合,返回一个 book 集合对象,用于执行集合操作。如果 book 集合不存在,则会在
test 数据库中创建一个名为 book 的集合。
查找数据
print(list(col.find()))print(list(col.find_one())) # 返回数据的key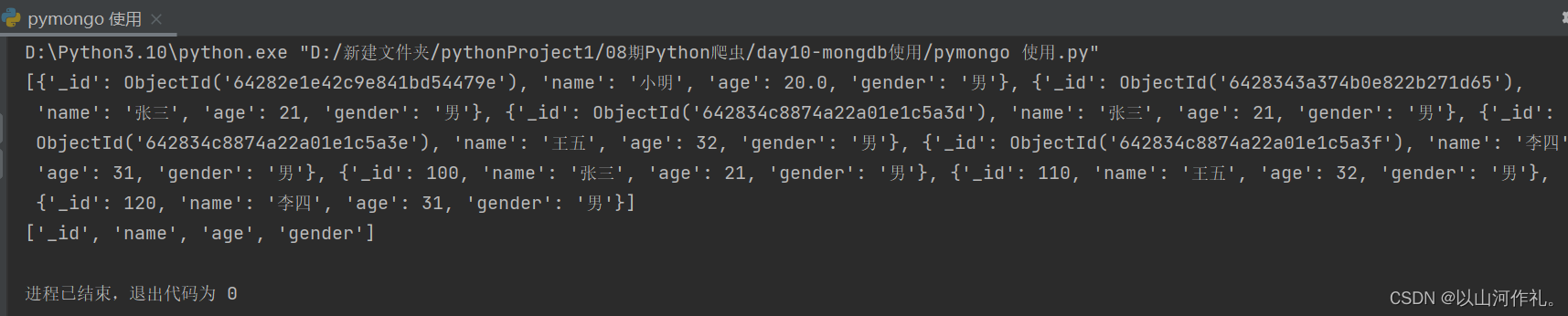
增加一条数据
data_dict = {'name': '小雨', 'age': 20, 'gender': '男'}col.insert_one(data_dict)增加多条数据
data_dict = [{'name': '小雨', 'age': 20, 'gender': '男'}, {'name': '小芳', 'age': 19, 'gender': '女'}]col.insert_many(data_dict)删除一条数据 只对一条数据生效
col.delete_one({'name': '小明'})删除所有满足要求的数据 对所有数据生效col.delete_many({'name': '小明'})更新数据 只对一条数据生效
col.update_one({'name': '小雨'}, {'$set': {'age': 22}})更新数据 对所有数据生效
col.update_many({'name': '小雨'}, {'$set': {'age': 22}})分两部分,第一部分,获取数据,第二部分,将数据写入MongoDB
前面我们讲解了很多获取数据的方法,我们今天就不在这里作过多的展示,博主这里使用的是xpath进行解析数据,如果有什么疑问可以阅读博主之前的文章帮助理解和学习。《5.网络爬虫——Xpath解析》
直接查看结果:
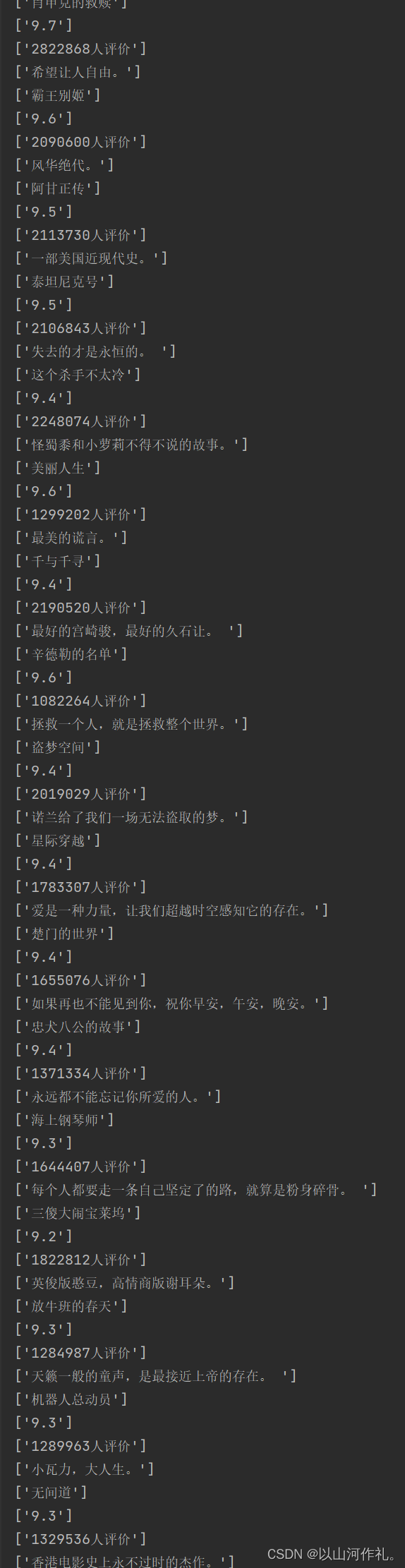
我们本次目的是获取电影top250的电影名字,评分,评价人数和简介。数据较多,仅展示部分!!
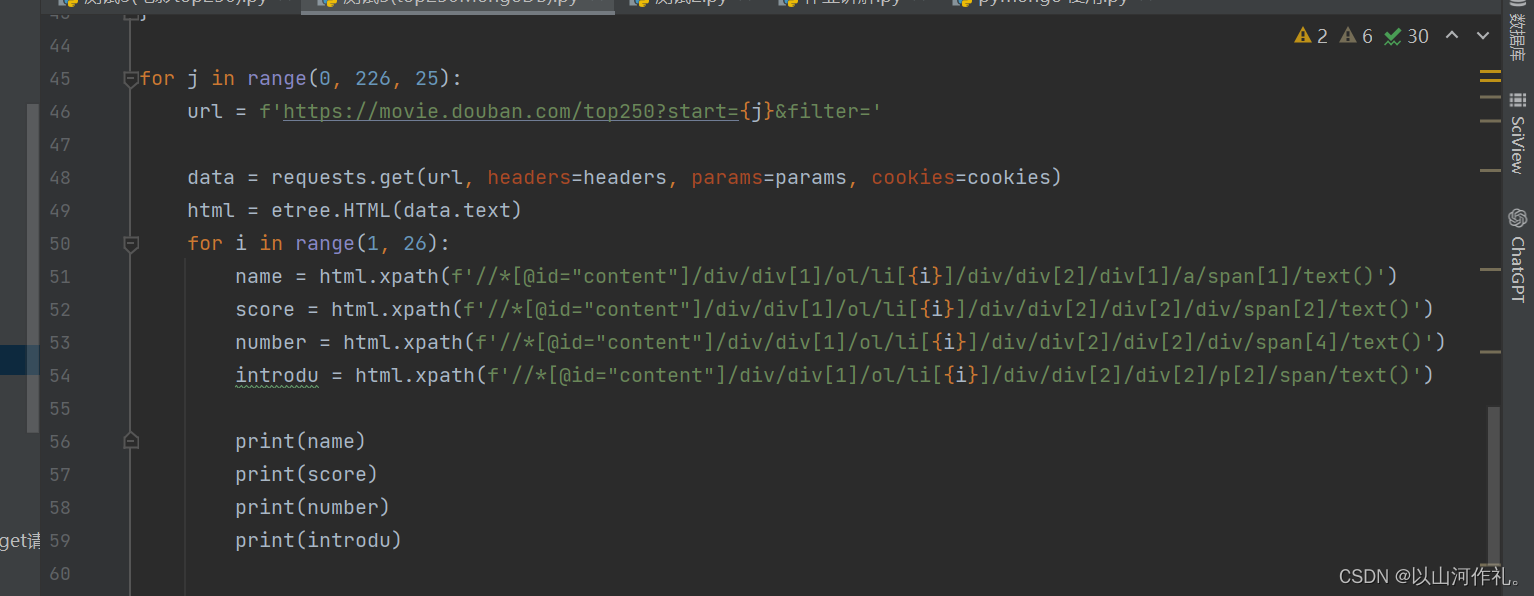
mongo = pymongo.MongoClient() # 连接数据库print(mongo)连接成功!


db = mongo.datadbprint(db)
col = db.bookprint(col)
插入数据
把刚才获取的数据插入到mongodb中。
data_dict = {'name': name, 'score': score, 'number': number, 'introdu': introdu} # 插入数据 col.insert_one(data_dict) time.sleep(1) # 睡眠1秒,防止过快请求被封IPprint('数据写入完成')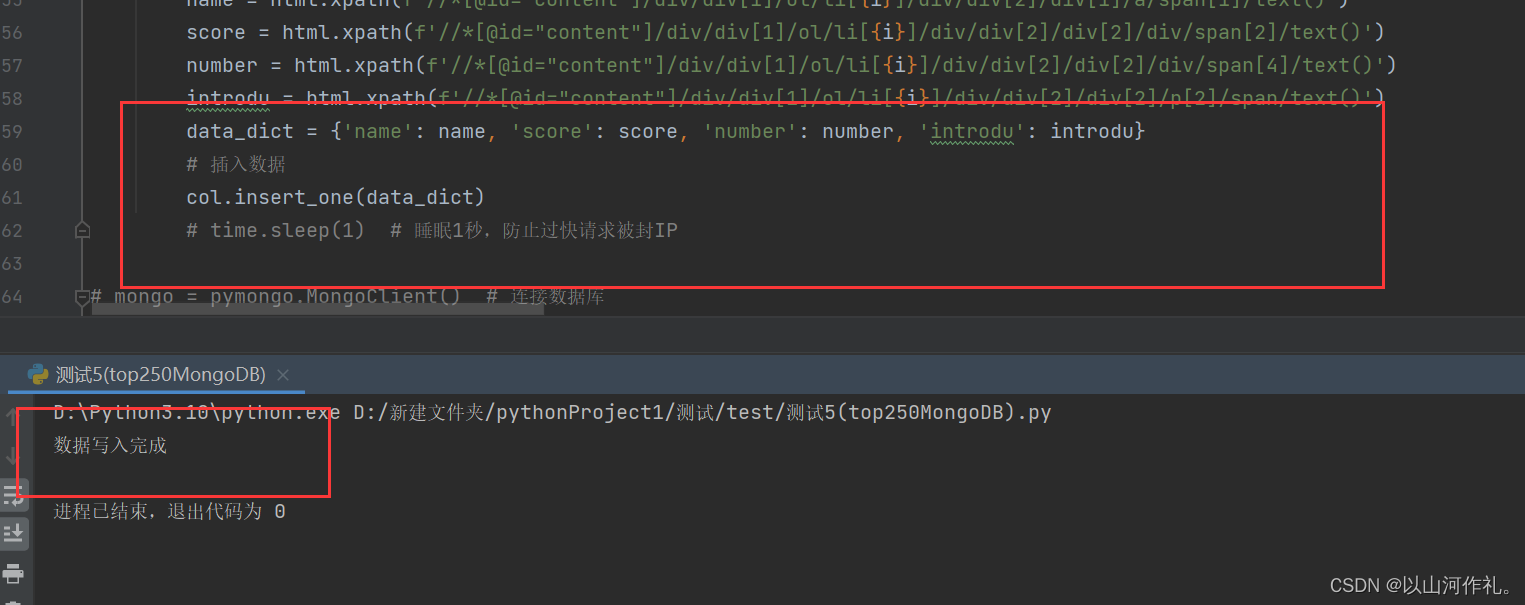
查看数据
results = col.find()for result in results: print(result)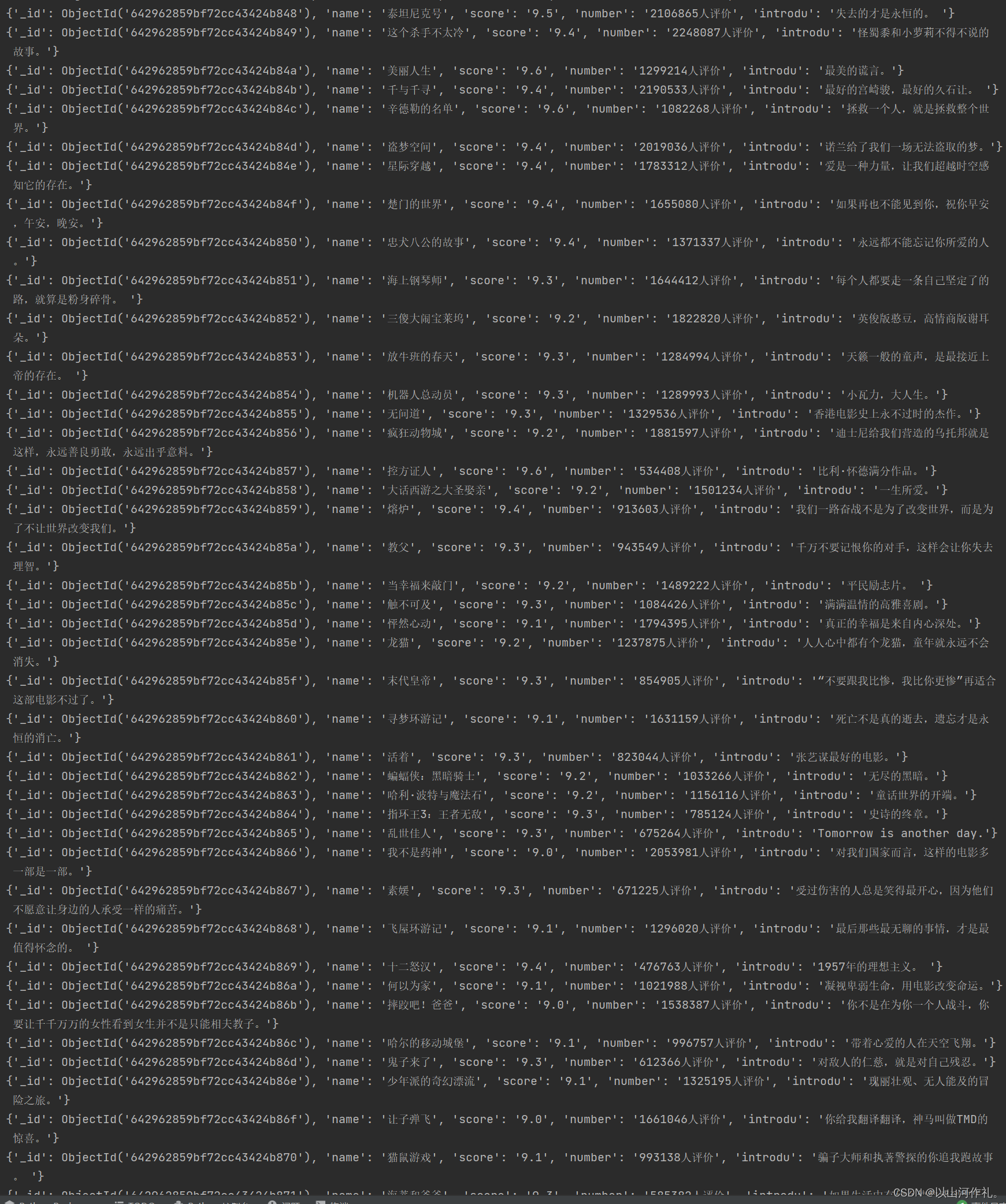
仅展示部分数据,数据太长了。正确来说一个有250条数据在里面。
写在最后:
👉 👉本专栏所有文章是博主学习笔记,仅供学习使用,爬虫只是一种技术,希望学习过的人能正确使用它。博主也会定时一周三更爬虫相关技术更大家系统学习,如有问题,可以私信我,没有回,那我可能在上课或者睡觉,写作不易,感谢大家的支持!!🌹🌹🌹
来源地址:https://blog.csdn.net/weixin_50804299/article/details/129912208
--结束END--
本文标题: 10.网络爬虫—MongoDB详讲与实战
本文链接: https://www.lsjlt.com/news/402153.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0