Python 官方文档:入门教程 => 点击学习
目录读取 txt 文件读取 csv 文件读取 Mysql 数据库表读取 JSON 文件中文输出乱码前提: 可以参考文章 SpringBoot 接入 spark springBoot
前提: 可以参考文章 SpringBoot 接入 spark
@Resource
private SparkSession sparkSession;
@Resource
private JavaSparkContext javaSparkContext;

java 代码
public void testSparkText() {
String file = "D:\\TEMP\\word.txt";
JavaRDD<String> fileRDD = javaSparkContext.textFile(file);
JavaRDD<String> wordsRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaPairRDD<String, Integer> wordAndOneRDD = wordsRDD.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> wordAndCountRDD = wordAndOneRDD.reduceByKey((a, b) -> a + b);
//输出结果
List<Tuple2<String, Integer>> result = wordAndCountRDD.collect();
result.forEach(System.out::println);
}
结果得出,123 有 3 个,456 有 2 个,789 有 1 个

测试文件 testcsv.csv
java 代码
public void testSparkCsv() {
String file = "D:\\TEMP\\testcsv.csv";
JavaRDD<String> fileRDD = javaSparkContext.textFile(file);
JavaRDD<String> wordsRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
//输出结果
System.out.println(wordsRDD.collect());
}
输出结果
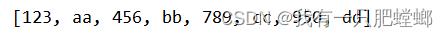
public void testSparkMysql() throws IOException {
Dataset<Row> jdbcDF = sparkSession.read()
.format("jdbc")
.option("url", "jdbc:mysql://192.168.140.1:3306/user?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai")
.option("dbtable", "(SELECT * FROM xxxtable) tmp")
.option("user", "root")
.option("password", "xxxxxxxxxx*k")
.option("driver", "com.mysql.cj.jdbc.Driver")
.load();
jdbcDF.printSchema();
jdbcDF.show();
//转化为RDD
JavaRDD<Row> rowJavaRDD = jdbcDF.javaRDD();
System.out.println(rowJavaRDD.collect());
}
也可以把表内容输出到文件,添加以下代码
List<Row> list = rowJavaRDD.collect();
BufferedWriter bw;
bw = new BufferedWriter(new FileWriter("d:/test.txt"));
for (int j = 0; j < list.size(); j++) {
bw.write(list.get(j).toString());
bw.newLine();
bw.flush();
}
bw.close();
结果输出

测试文件 testjson.json,内容如下
[{
"name": "name1",
"age": "1"
}, {
"name": "name2",
"age": "2"
}, {
"name": "name3",
"age": "3"
}, {
"name": "name4",
"age": "4"
}]
注意:testjson.json 文件的内容不能带格式,需要进行压缩

java 代码
public void testSparkJson() {
Dataset<Row> df = sparkSession.read().json("D:\\TEMP\\testjson.json");
df.printSchema();
df.createOrReplaceTempView("t");
Dataset<Row> row = sparkSession.sql("select age,name from t where age > 3");
JavaRDD<Row> rowJavaRDD = row.javaRDD();
System.out.println(rowJavaRDD.collect());
}
输出结果

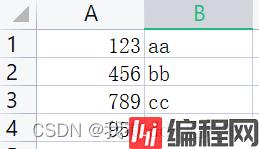
测试文件 testcsv.csv
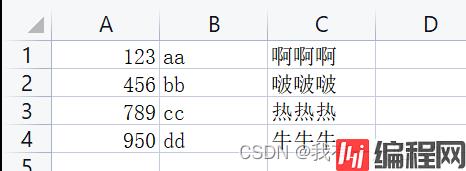
public void testSparkCsv() {
String file = "D:\\TEMP\\testcsv.csv";
JavaRDD<String> fileRDD = javaSparkContext.textFile(file);
JavaRDD<String> wordsRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
//输出结果
System.out.println(wordsRDD.collect());
}
输出结果,发现中文乱码,可恶
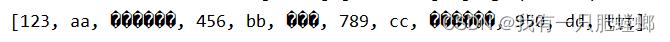
原因:textFile 读取文件没有解决乱码问题,但 sparkSession.read() 却不会乱码
解决办法:获取文件方式由 textFile 改成 hadoopFile,由 hadoopFile 指定具体编码
public void testSparkCsv() {
String file = "D:\\TEMP\\testcsv.csv";
String code = "gbk";
JavaRDD<String> gbkRDD = javaSparkContext.hadoopFile(file, TextInputFormat.class, LongWritable.class, Text.class).map(p -> new String(p._2.getBytes(), 0, p._2.getLength(), code));
JavaRDD<String> gbkWordsRDD = gbkRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
//输出结果
System.out.println(gbkWordsRDD.collect());
}
输出结果

到此这篇关于SpringBoot使用Spark过程详解的文章就介绍到这了,更多相关SpringBoot Spark内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: SpringBoot使用Spark过程详解
本文链接: https://www.lsjlt.com/news/196198.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0